跟李沐学AI:A Gentle Introduction to Graph Neural Networks(图神经网络GNN)
跟李沐学AI:A Gentle Introduction to Graph Neural Networks
- 1. Intro
- 2. What a graph is
-
- 2.1 图表示的例子
- 2.2 图中三个层面的问题
-
- 2.2.1 graph-level
- 2.2.2 Node-level
- 2.2.3 Edge-level
- 2.3 在图上使用机器学习的挑战
- 3. Graph Neural Networks
-
- 3.1 一个简单的例子
- 3.2 信息传递
- 3.3 学习边的表示
- 3.4 添加全局表示
- 4. playground
- 5. Into the Weeds
原blog:A Gentle Introduction to Graph Neural Networks
1. Intro
图神经网络的发展才刚刚开始,其在药物发现、物理学模拟、假新闻检测、交通预测和推荐系统等领域的可以有实际的应用。
文章分为四部分:
- 什么数据可以表示成一张图
- 图与其它类型数据的不同
- 构建一个GNN模块
- 搭建一个GNN的playground
2. What a graph is
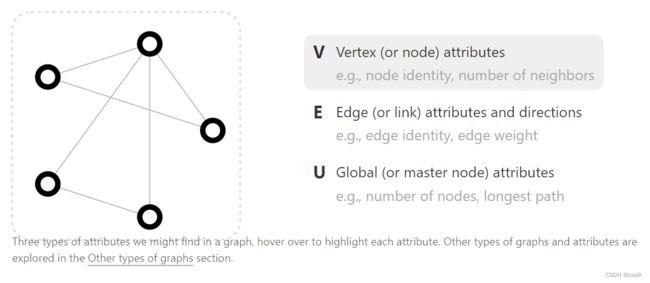
图表示的是一系列实体(节点)之间的关系(边)。

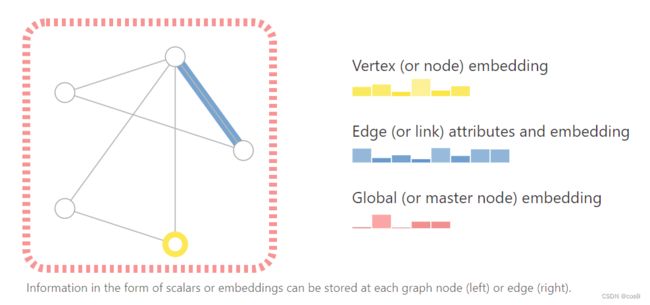
Attention:把节点信息、边信息和全局信息做embedding,通俗地说就是把这些信息存储为向量的形式(e.g. 如下图所示,node可以用一个长度为6的向量来表示)。所以图神经的核心就是,怎么样把我们想要的信息表示成向量,以及向量是否能通过数据学习到。
图中的边分为有向边和无向边,e.g. 微信好友之间的关系可以视为无向边,B站上粉丝关注一个up主可以看作是有向边
2.1 图表示的例子
- Images as graphs(将图片表示为图)
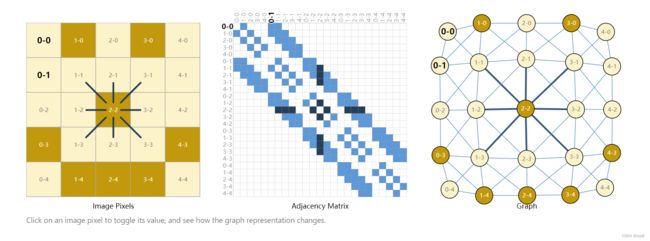
通常把图片表示为三维tensor,如224x224x3(学过CNN的同学就知道这里的三通道是指RGB三种颜色)。实际上我们可以把每个像素作为一个点,存在邻接关系则形成一条边。每个非边界像素正好有8个邻居,存储在每个节点的信息是一个3维向量,代表像素的RGB值。中间的就是邻接矩阵,相邻则是1,不相邻则是0,一般会是非常大的稀疏矩阵。
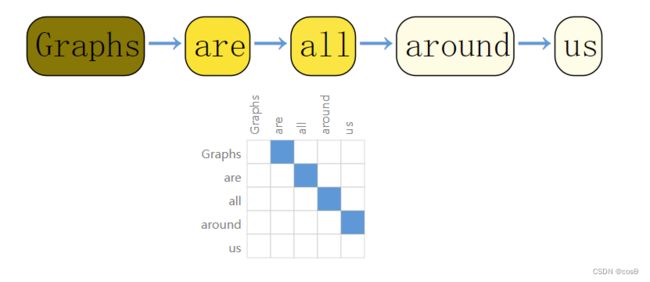
- Text as graphs(将文本表示为图)
文本是一个序列,把词表示为顶点,词与词存在有向边。
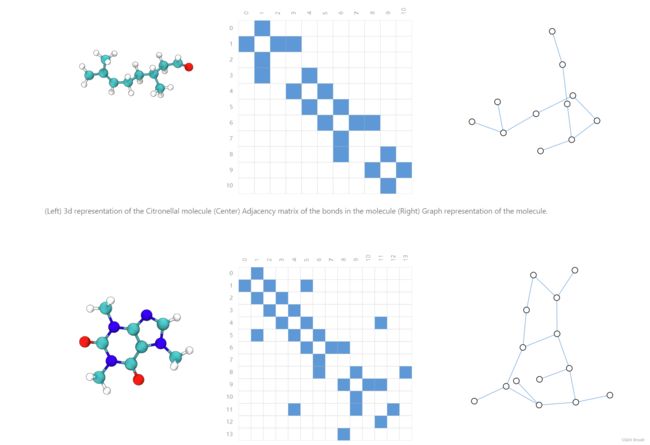
- Molecules as graphs(将分子结构图表示为图)
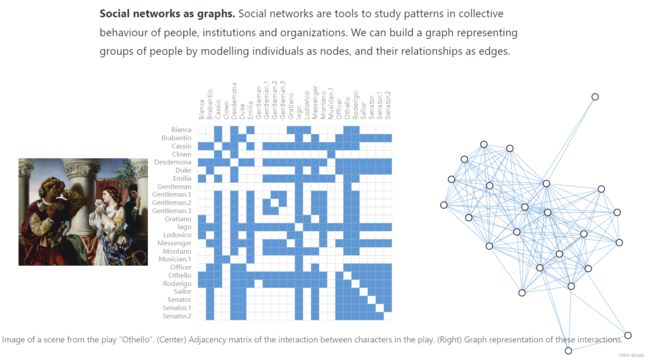
- Social networks as graphs(将社交网络表示为图)
下图表示奥赛德剧中出现人物的社交网络情况,有边代表两个人同时出现过
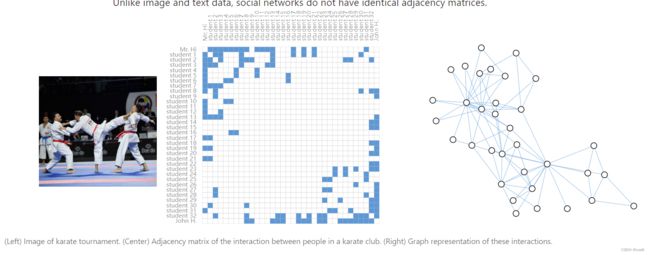
- Citation networks as graph(将引用网络表示为图)
文章之间的引用,会生成一条边,但是往往都是有向边,因为是新文章引用旧文章,双向引用就不太现实了。
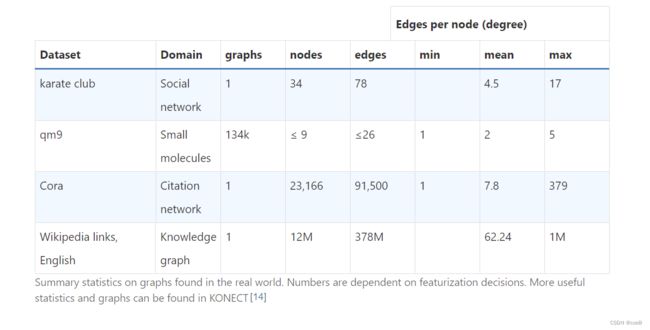
- 真实世界中的例子
2.2 图中三个层面的问题
2.2.1 graph-level
在图级任务中,我们的目标是预测整个图的属性。即给定一张图,对该图进行分类。
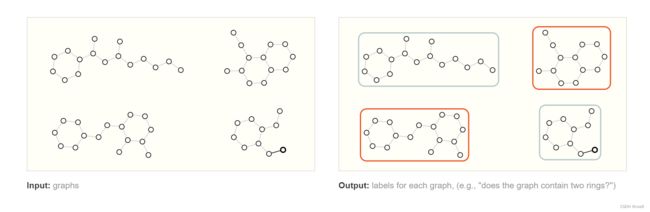
如上图,预测出哪些分子是具有两个环的。这个例子比较简单,可以用图的遍历来完成,当图非常复杂的时候,图神经网络可以发挥巨大作用。
2.2.2 Node-level
节点级任务关注的是预测图中每个节点属性的判断。
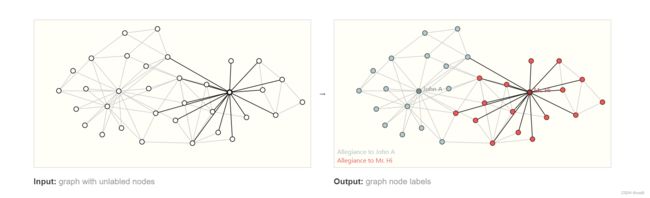
上图是空手道俱乐部数据集,将学员分类到两个老师的队伍中。
2.2.3 Edge-level
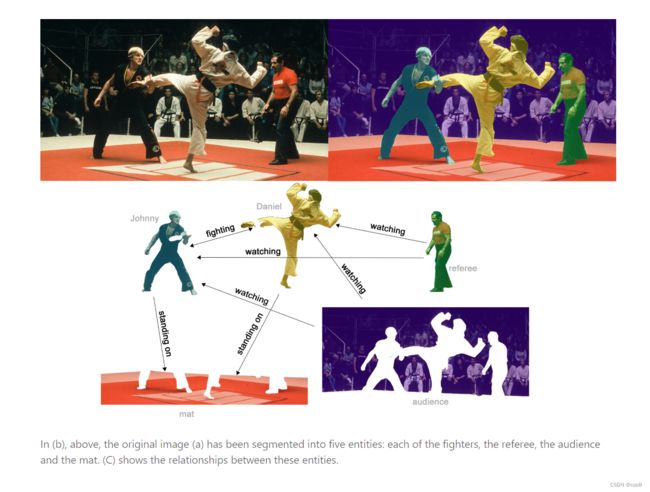
边的预测(链路预测)的例子是通过语义分割把人物、背景拿出来,然后分析实体间的关系(属性)。比如黄衣服的人在踢绿衣服的人,他们都站在地毯上。
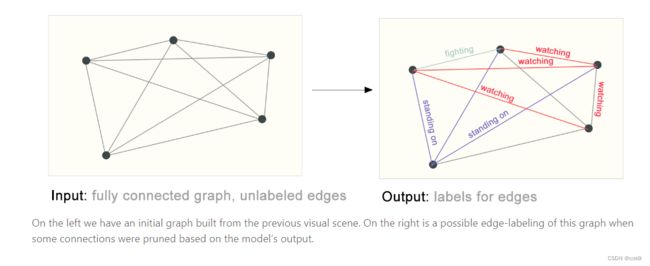
2.3 在图上使用机器学习的挑战
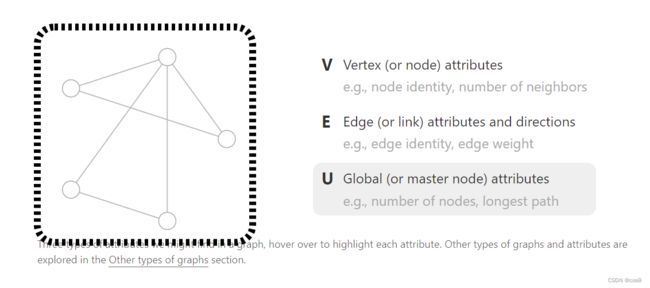
机器学习模型通常将矩形或网格状的阵列作为输入。因此,如何以一种与深度学习兼容的格式来表示它们,并不是很直观的。**图有多达四种类型的信息,我们有可能想用来进行预测:节点、边、全局信息和连接性(每条边连接了哪两个点)。**前三者相对简单,可以直接用向量来表示。
然而,表示一个图的连接性是比较复杂的。也许最明显的选择是使用邻接矩阵,因为这很容易进行张量处理。然而,这种表示方法有一些缺点:如果图非常大,比如Wikipedia,则存储不下来。由于是邻接矩阵很稀疏,所以用稀疏矩阵来存储会更好,而稀疏矩阵在GPU上训练一直是个技术难题。
另一个问题是,有许多邻接矩阵可以任意交换行列接,会导致邻接矩阵发生变化,但实际上的节点关系保持不变,不能保证这些不同的矩阵在深度神经网络中产生相同的结果。(也就是说,它们不具有permutation invariant)e.g. 下图不同样子的邻接矩阵都形成了连接性相同的图,而他们都是异构的。


那么想要存储高效且不受排序的影响应该如何存储呢?
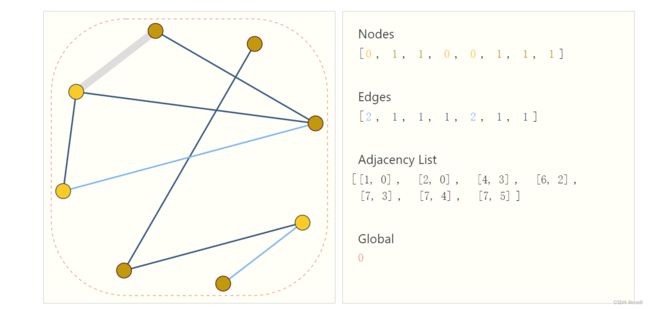
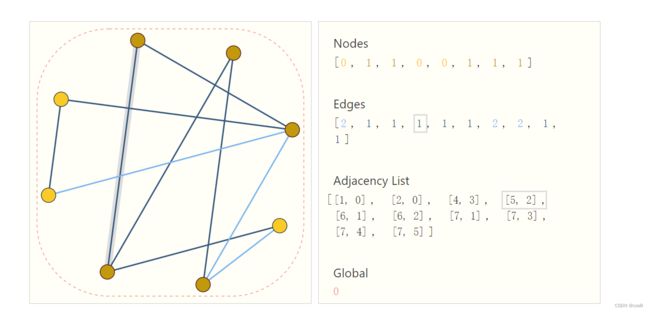
**上图中的节点、边和全局信息都可以用向量表示,而不一定只是标量。**这个adjacency list能够用节点id把边的连接关系表示出来。当node/edges发生改变时,只需要改变adjacency List即可。
3. Graph Neural Networks
什么是GNNs?是对图上所有属性(节点、边、全局上下文)进行可以优化的变换,变换能保持图的对称信息(节点重新排序后,结果不变)。message passing neural network是一种GNNs的框架,当然GNN是可以用别的方式构建。
GNNs是**“graph-in, graph-out”**,他会对节点、边的信息进行变换,但是图连接性是不变的。
3.1 一个简单的例子
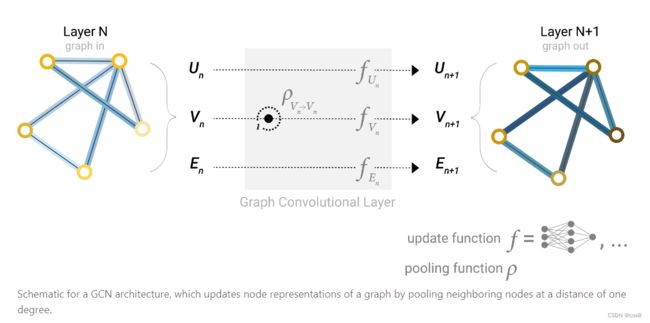
首先,对节点向量、边向量、全局向量分别构建一个MLP(多层感知机),MLP的输入输出的大小相同。
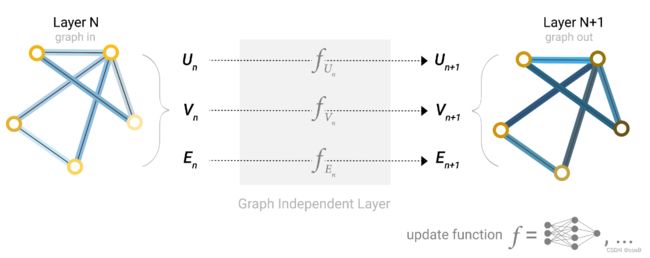
三个MLP( f U n , f V n , f E n f_{U_n},f_{V_n},f_{E_n} fUn,fVn,fEn)组成GNN的一层,一个图经过MLP后仍然是一个图。对于顶点、边、全局向量分别找到对应的MLP,作为其更新函数(update function)。可以看到,输出后图的属性变化了,但是图的结构没有改变,符合我们的需求。MLP对每个向量独自作用,不会影响的连接性。
堆叠了多层上述的模型后得到了GNN,现在来到最后一层,对节点进行预测。
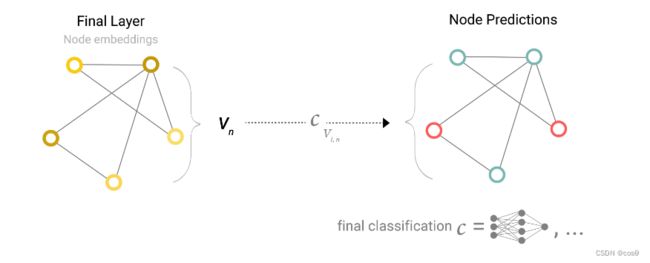
上图可以看到,经过GNN的最后一层,得到的也是一个图,然后在图后面接一个全连接层(分类的话神经元数量则是类别数,再套一个softmax,回归的话神经元数量则是1),所有节点共享一个全连接层( c V i , n c_{V_{i,n}} cVi,n)的参数。
考虑另一种情况,如果说某个节点是没有自己的属性(向量)的,应该怎么做?这里介绍到pooling(汇聚)

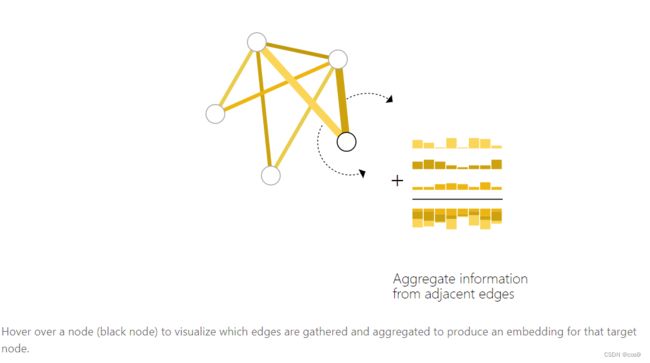
做法就是把节点相连的边向量拿出来,全局向量拿出来(如果向量长度不同,还需要做投影),然后将这些向量相加求和,最后经过一个节点共享的输出层得到节点预测结果。
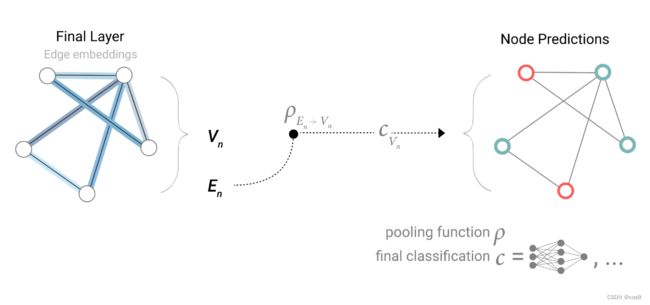
假如没有边向量而只有节点的向量,则汇聚相连的节点的向量,如下图所示:
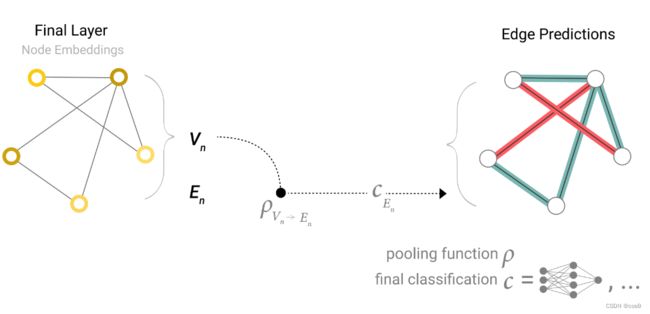
那如果没有全局向量,只有节点向量呢?就把全部的节点向量汇聚起来,经过最后的输出层得到全局的输出。
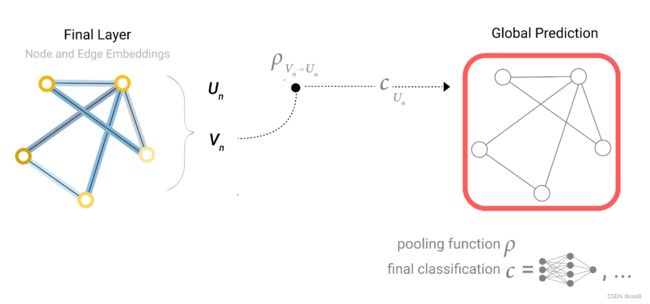
所以,不管缺哪类属性,我们都可以通过汇聚这个操作,得到最终的输出值。下图则是GNN流程的描述
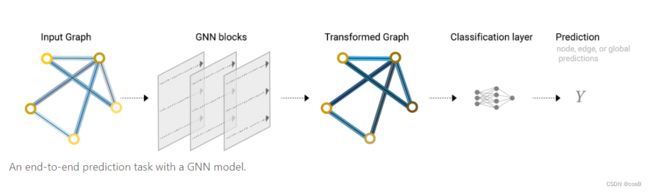
如上模型的局限性是很明显的,并没有用到图的结构,仅仅是点、边向量分别做MLP的过程
3.2 信息传递

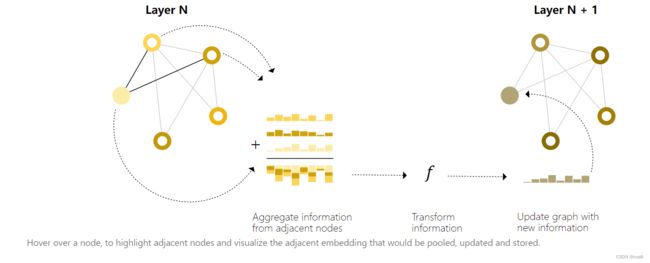
在更新某个节点的向量时,会将自己的向量和邻居节点的向量进行聚合操作,然后再传入MLP更新节点的向量。作者说这个过程和标准卷积相似,但其实不完全是。下图则是GCN的架构涉及,通过聚集邻居节点来更新节点的表达。
3.3 学习边的表示
下图是信息传递层的原理,从节点到边、边到节点的传递。
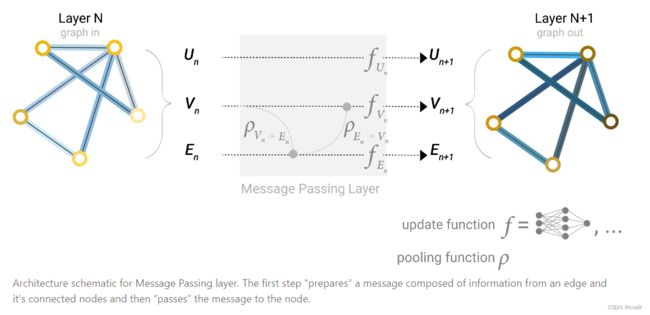
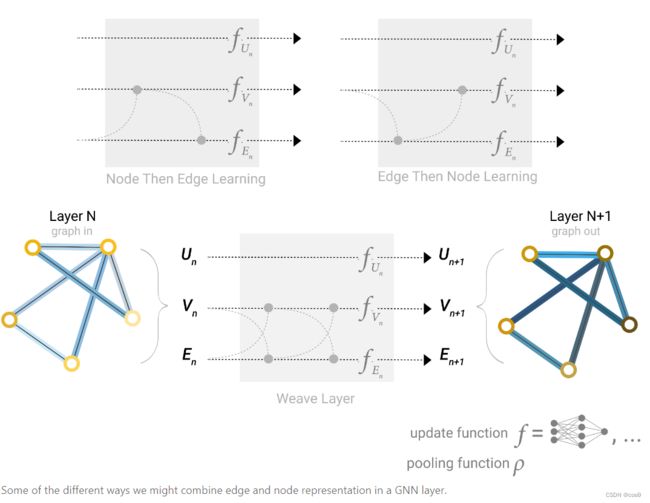
下面是两种不同的聚集方式:先从节点到边/先从边到节点。现在对于哪种做法更好还没有定论,作者提出可以交替进行(下图种的weave layer,同时边汇聚到顶点,顶点汇聚到边,汇聚之后再同时来一次),这样两边的信息都有了,只是向量会更宽一些。
3.4 添加全局表示
如果说图很大,或者连接不够紧密,那聚合就需要走很远很远的路。这里介绍了一种解决方案:master node or context vector,这是一个虚拟的、抽象的点,与所有的节点和边相连。
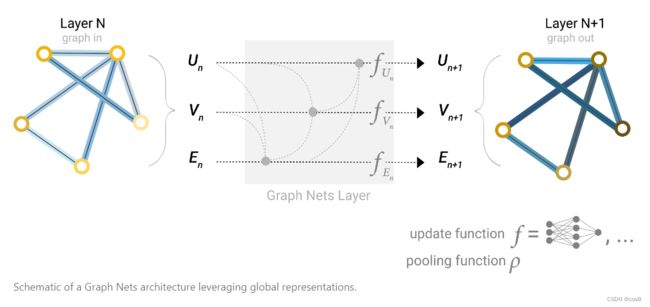
作者说这个其实可以认为是featurize-wise attention mechanism(特征级的注意力机制),因为将相近的节点聚集了过来。现在我们就知道了基于消息传递的图神经网络是怎么样工作的。
4. playground
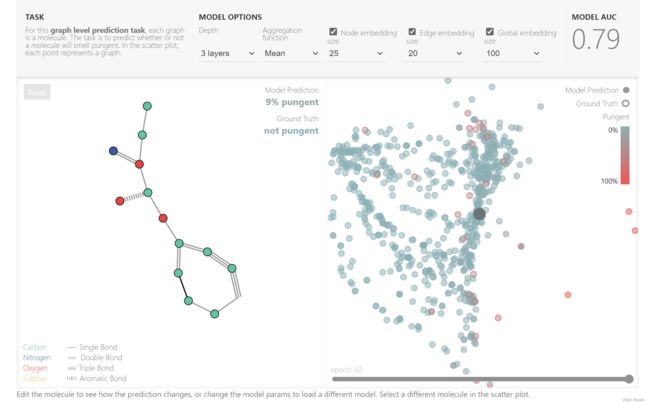
Aggression function:汇聚操作的情况,sum/max/mean,分别对应卷积神经网络里的max pooling和average pooling
Epoch:一个epoch表示所有的数据送入网络中, 完成了一次前向计算 + 反向传播的过程。
下面是超参数对效果的影响:
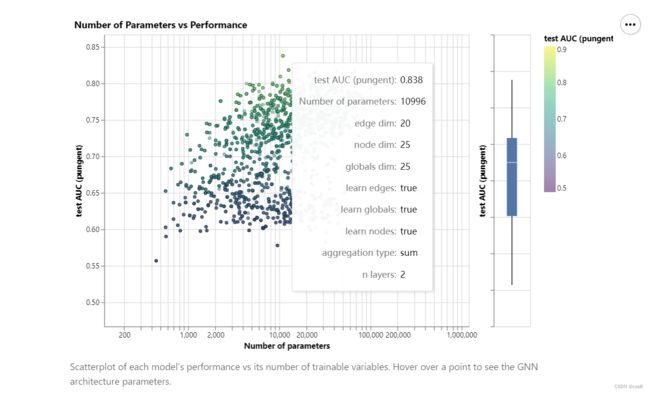
原blog下面还有各个超参数对效果的影响。
5. Into the Weeds
介绍图相关的技术
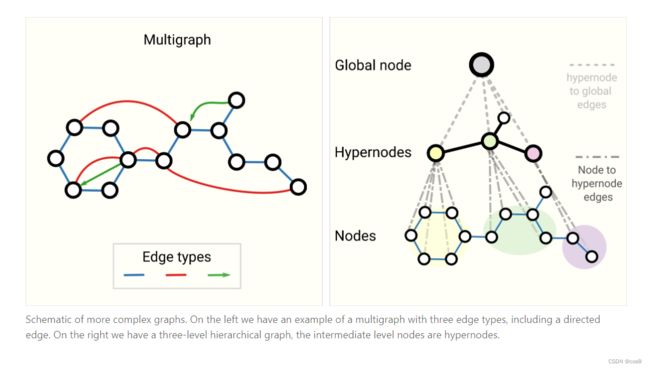
multigraph和分层图:
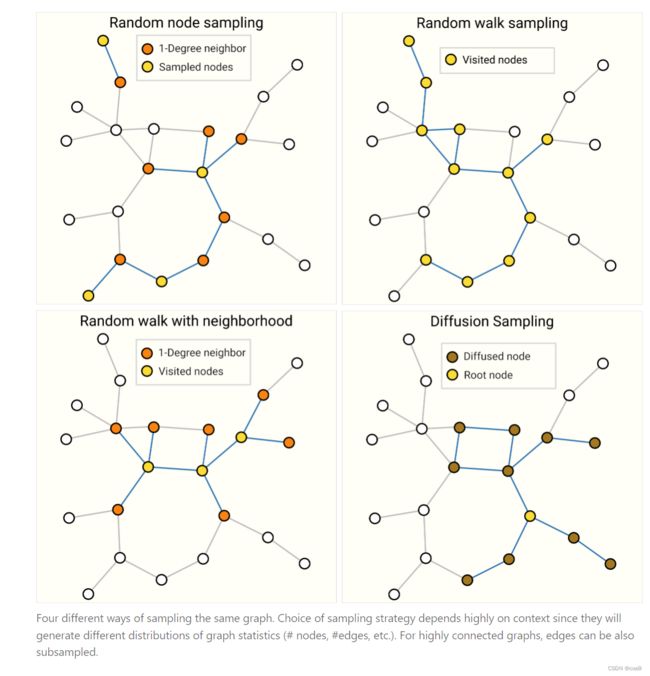
图采样和batch:
图采样介绍了随机采样、随机游走、随机游走+邻居采样、扩散采样。
batch就是采用和其他神经网络一样的做法,把大图切成小样本进行一些运算,但是每个节点邻居数不同,如何合并为一个规则的tensor是具有挑战性的问题。
Inductive biases:
CNN的假设是空间变换的不变性,RNN的假设是时序的连续性。对于GNN来说,假设是保持图的对称性(变换排列顺序,训练结果不变)
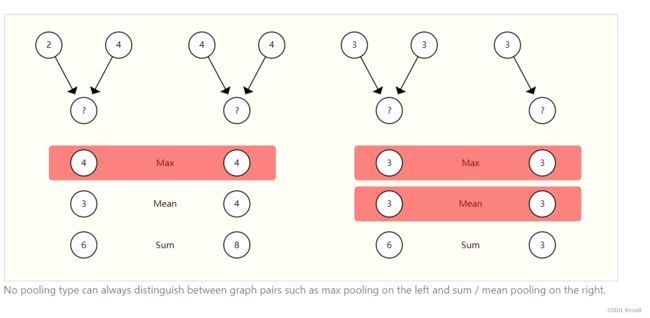
对比聚合操作:
sum max mean没有一种是非常理想的,不能一概而论,举了如下的例子:
GCN作为子图函数近似:
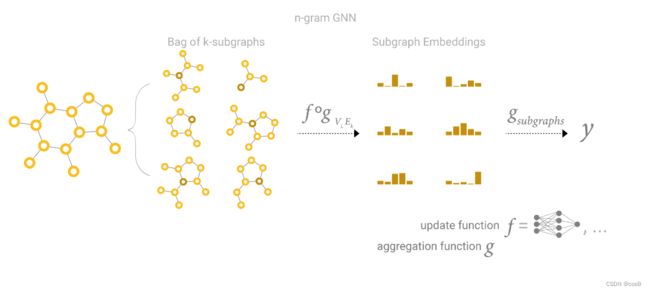
GCN如果是k层,每一层都往前看一个邻居,那么最后一个节点看到的是一个子图,这个子图大小是k,和节点的距离是k。这里我理解的就是,GCN有多少层,就看到了多少阶的邻居。
所以,GCN实际上是有N个子图,每个子图都是从原节点出发,往前走k步。
边和图对偶:
点和边做对偶,把边变成点,点变成边,邻接关系保持不变。
图卷积和矩阵乘法,矩阵乘法和图游走:
核心就是做图卷积等价于拿邻接矩阵做矩阵乘法。
PageRank就是在很大的图上做随机游走,实际上就是把邻接矩阵拿出来,不断和向量做乘法。
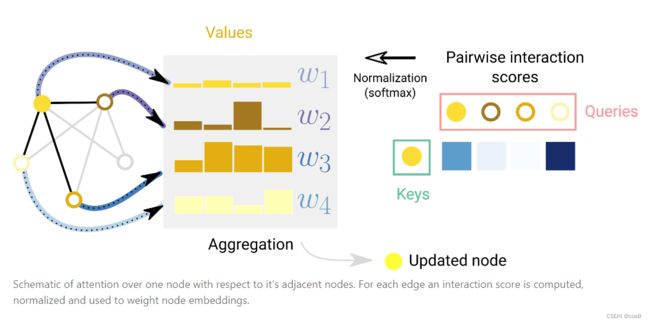
图注意力网络:
在GCN中,将邻居节点汇聚到某个节点上,实际上是没有加权的。其实图神经网络中也可以像CNN中的卷积核一样,在3x3窗口中带有基于空间位置的不同的权重。图上不需要空间位置,只需要通过注意力机制计算两个节点向量的关系强弱,按计算出来的权重来聚合。
图解释: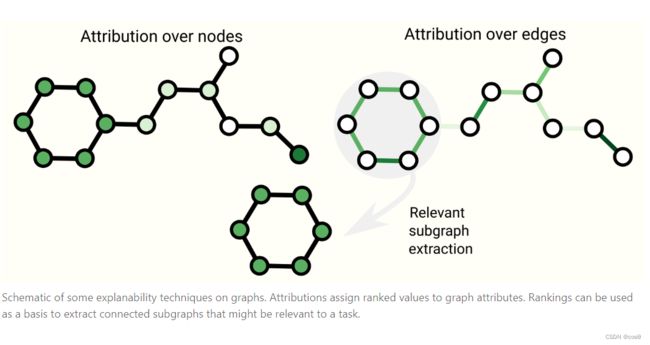
神经网络到底学到了什么东西,可以抓取子图来看学到了什么。
生成模型:
我们之前的模型是不改变图结构的,这里通过生成模型可以对图的拓扑结构进行有效建模。