从零开始,搭建CNN(卷积)神经网络识别Mnist手写体
运行环境
- Windows 10 专业版 x64
- Python 3.7.2
- tensorflow 1.9
- keras 2.2.4
导入工具包
-
神经网络线性堆叠框架
from keras.models import Sequential卷积神经网络拥有卷积层,池化层,展开层,全连接层等,该框架则是容纳各个网络层的东西,可以看做一个容器。
-
卷积层,池化层,激活层,展开层,全连接层,Dropout层
from keras.layers import Convolution2D,MaxPooling2D from keras.layers import Activation,Flatten,Dense,Dropout -
数据形态转换工具
from keras.utils import np_utils
搭建模型
-
加载数据集
#mnist数据集,含有60000个训练数据以及10000个测试数据,样本图片均为1~9的数字手写体 from keras.datasets import mnist (X_train,y_train),(X_test,y_test)=mnist.load_data()此处采用网络加载的方法,如果网络加载不可用或网络环境不太好,则可采用本地加载的方法。
- 本地加载
如图所示,按住Ctrl点击load_data。

将如图所示的load()改为本地mnist数据集所在的路径,根据自己的情况作修改,我是将mnist数据集放在Anaconda目录下的。
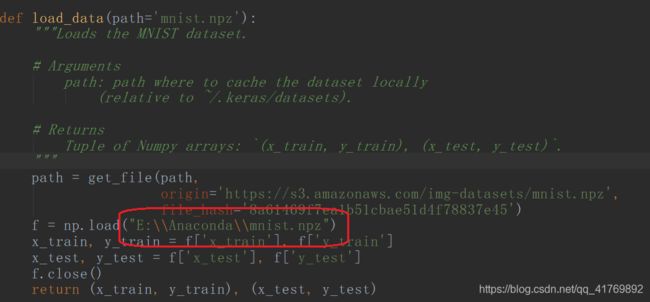
mnist数据集下载地址:https://s3.amazonaws.com/img-datasets/mnist.npz
也可以采用其他方式下载,不过注意的是下载文件的扩展名要为npz,已经解过压的数据集的导入方式是不同的。
- 本地加载
-
转换图片数据状态
X_train=X_train.reshape(X_train.shape[0],1,28,28) X_test=X_test.reshape(X_test.shape[0],1,28,28)原本的图片数据状态为:图片数量,图片宽度,图片高度
转换后为:图片数量,图片深度,图片宽度,图片高度
mnist数据集图片均为黑白图片,因此图片深度统一为1 -
转换图片数据类型并限制数据范围
X_train=X_train.astype('float32') X_test=X_test.astype('float32') X_train /=255 X_test /=255黑白图片每个像素点都代表了0–255之间的一个数字,此时图片在计算机里是一个二维矩阵,将矩阵中的每个元素转换为浮点型,为了便于分析计算,将矩阵中每个元素限制到0–1之间
-
转换标签的数据形态
Y_train=np_utils.to_categorical(y_train,10) Y_test=np_utils.to_categorical(y_test,10)每个图片对应一个标签,标签即是图片识别的结果。
一张标签对应一张图片,那么每个标签不外乎是0–9之间的数字,但这不是我们想要的。
我们要将标签转换为一个列表,比如:
0就是[1,0,0,0,0,0,0,0,0,0]
1就是[0,1,0,0,0,0,0,0,0,0]
2就是[0,0,1,0,0,0,0,0,0,0]
…
以此类推 -
创造模型框架
model=Sequential()相当于把容器放好,要往里面添加神经网络了。
-
添加第一个卷积层和激活层
model.add(Convolution2D(32,3,3,input_shape=(1,28,28))) model.add(Activation('relu'))32表示过滤器(卷积核)的个数,3 3 表示过滤器的宽和高
input_shape表示输入图片深度为1,宽为28,高为28
经过一次卷积后图片大小为 26,26 (原始图片未经处理,卷积后图片缩小)
激活层其实就是激活函数,最大的作用就是限制通过卷积核的结果(负数变为0,正数不变) -
添加第二个卷积层和激活层
model.add(Convolution2D(32,3,3)) model.add(Activation('relu'))经过两次卷积后图片大小为 24,24
input_shape可以省略,如果要写,注意宽和高是26 -
添加池化层,池化大小为2,2
model.add(MaxPooling2D(pool_size=(2,2)))池化层的作用简单理解就是将上面卷积得到的图片变小变模糊,但保留了主要特征,至少从肉眼观看不影响识别。
-
添加展开层
model.add(Flatten())展开图像像素点,即把图像从二维变为一维
-
添加全连接层
model.add(Dense(128,activation='relu'))128代表神经元的个数,此处可以随意设置
-
添加Dropout层,防止过拟合
model.add(Dropout(0.5)) -
再次添加全连接层
model.add(Dense(10,activation='softmax'))此处神经元的个数只能为10,因为该全连接层也是输出层,对应10个标签。
softmax代表非线性函数,输出的结果为“最初输入的图片,属于每个标签的概率” -
编译模型
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])目标:categorical_crossentropy(误差损失)尽可能小
为了完成目标,使用方法:adam
accuracy(准确率)来评估模型的预测效果 -
训练模型
model.fit(X_train,Y_train,batch_size=32,nb_epoch=10,validation_split=0.3)batch_size=32 一批处理32个样本
nb_epoch=10 有10个周期(训练时比较吃CPU,如果对电脑没把握可以减小训练周期)
validation_split=0.3 从训练样本中拿出30%作为交叉验证集,因此训练样本为42000个,在训练时有18000个样本参与测试 -
评估模型(用测试数据集测试准确度)
score=model.evaluate(X_test,Y_test) print(score)
到此,一个基本的CNN神经网络搭建完成,可以运行了
运行
ValueError: Negative dimension size caused by subtracting 3 from 1 for 'conv2d_1/convolution' (op: 'Conv2D') with input shapes: [?,1,28,28], [3,3,28,32].
如果出现该错误,则在程序最前面加上:
from keras import backend as K
K.set_image_dim_ordering('th')
运行截图

loss:误差损失(尽可能小)
acc:准确率
整个运行时间大概需要10分钟,即每个训练周期差不多1分钟,对电脑不自信的可以更改周期次数。
附:
from keras import backend as K
K.set_image_dim_ordering('th')
#导入网络的线性堆叠框架
from keras.models import Sequential
#导入卷积层,池化层
from keras.layers import Convolution2D,MaxPooling2D
#导入激活层,展开层,全连接层,Dropout层
from keras.layers import Activation,Flatten,Dense,Dropout
#导入数据形态转换工具
from keras.utils import np_utils
#加载数据集
#若网络加载异常,可采用本地文件加载,此处为网络加载
#mnist数据集,含有60000个训练数据以及10000个测试数据,样本图片均 为1~9的数字手写体
from keras.datasets import mnist
(X_train,y_train),(X_test,y_test)=mnist.load_data()
#转换图片数据形态 转换为 样本数量,图片深度,图片宽度,图片高度
X_train=X_train.reshape(X_train.shape[0],1,28,28)
X_test=X_test.reshape(X_test.shape[0],1,28,28)
#转换图片数据类型及限制数据范围 将数值范围从[0,255]标准化到[0,1]
X_train=X_train.astype('float32')
X_test=X_test.astype('float32')
X_train /=255
X_test /=255
#转换标签的数据形态
#0=[1,0,0,0,0,0,0,0,0,0]
#1=[0,1,0,0,0,0,0,0,0,0]
#...
Y_train=np_utils.to_categorical(y_train,10)
Y_test=np_utils.to_categorical(y_test,10)
#创造模型框架
model=Sequential()
#添加第一个卷积层和激活层
#32表示过滤器(卷积核)的个数,3 3 表示过滤器的宽和高
#input_shape表示输入图片深度为1,宽为28,高为28
#经过一次卷积后图片大小为 26,26 (原始图片未经处理,卷积后图片缩小)
model.add(Convolution2D(32,3,3,input_shape=(1,28,28)))
model.add(Activation('relu'))
#添加第二个卷积层和激活层
#经过两次卷积后图片大小为 24,24
model.add(Convolution2D(32,3,3))
model.add(Activation('relu'))
#添加池化层,池化大小为2,2
#经过池化处理后图片大小变为12,12
model.add(MaxPooling2D(pool_size=(2,2)))
#添加展开层,展开图像像素点
model.add(Flatten())
#添加全连接层
#128表示神经元个数,可随意设置
model.add(Dense(128,activation='relu'))
#防止过拟合
model.add(Dropout(0.5))
#再次添加全连接层
#此处也是输出层,神经元个数只能为10,对应10个标签
#softmax是非线性函数,输出的结果为“最初输入的图片,属于每个标签的概率”
model.add(Dense(10,activation='softmax'))
#编译模型
#目标:categorical_crossentropy(误差损失)尽可能小
#为了完成目标,使用方法:adam
#accuracy(准确率)来评估模型的预测效果
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#训练模型 batch_size=32 一批处理32个样本
#nb_epoch=10 有10个周期
#validation_split=0.3 从训练样本中拿出30%作为交叉验证集
#因此训练样本为42000个,在训练时有18000个样本参与测试
model.fit(X_train,Y_train,batch_size=32,nb_epoch=10,validation_split=0.3)
#评估模型(用测试数据集测试准确度)
score=model.evaluate(X_test,Y_test)
print(score)