应用 Tensorflow 进行花卉识别(flower_recognition)
数据获取:Kaggle上下载【Flowers Recognition | Kaggle】
数据预处理:
#训练集
train_data=tf.keras.utils.image_dataset_from_directory(
train_dir, #存放数据的目录
labels='inferred', #按照目录结构推断
label_mode='int',
validation_split=0.2,
subset='training', #返回为training数据
seed=128,
shuffle=True,
color_mode='rgb',
batch_size=16,
image_size=(150,150)
)
#验证集
validation_data=tf.keras.utils.image_dataset_from_directory(
train_dir,
labels='inferred',
label_mode='int',
validation_split=0.2,
subset='validation',
seed=128,
shuffle=True,
color_mode='rgb',
batch_size=16,
image_size=(150,150)
)
#测试集
test_data=tf.keras.utils.image_dataset_from_directory(
test_dir,
labels='inferred',
label_mode='int',
shuffle=True,
color_mode='rgb',
batch_size=16,
image_size=(150,150)
)查看生成的train_data中的前16张图片
#查看生成的train_data中的前16张图片
class_names=train_data.class_names
print(class_names)
plt.figure(figsize=(20,15))
for image,label in train_data.take(1):#BatchDataset类型数据返回最多一个批次为包含图像数组和标签的元组,图像数组shape=(16,64,64,3),标签(16,1)
print(image.shape)
print(label.shape)
for i in range(16):
ax=plt.subplot(4,4,i+1)
plt.imshow(image[i].numpy().astype("uint8"))
plt.axis('off')
plt.title(class_names[label[i]])
开始训练:
可使用Dropout、BatchNormalization、数据增强等方法抑制过拟合
#开始训练
model=tf.keras.Sequential([
#data_augmentation,
tf.keras.layers.Rescaling(1/255),
tf.keras.layers.Conv2D(64,(3,3),padding='same',activation='relu',input_shape=(150,150,3)),
tf.keras.layers.MaxPooling2D(2,2),
# tf.keras.layers.Dropout(rate=0.3),
tf.keras.layers.Conv2D(128,(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64,activation='relu'),
# tf.keras.layers.Dropout(rate=0.3),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(5,activation='softmax')
])
model.compile(loss=tf.losses.sparse_categorical_crossentropy,optimizer=tf.optimizers.RMSprop(learning_rate=0.001),metrics=['acc'])
model.build(input_shape=(3414,150,150,3))
model.summary()
模型训练
#模型训练
import datetime
start_time=datetime.datetime.now()# 开始训练
history=model.fit(train_data,epochs=20,validation_data=validation_data)
end_time=datetime.datetime.now() #结束训练
cost_time=end_time-start_time #训练时长
print(f'训练时长={cost_time}')模型结果可视化:
#查看模型精度
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
x=range(len(acc))
fig,ax=plt.subplots(1,2,figsize=(15,7))
ax1=ax[0]
ax2=ax[1]
ax1.plot(x,acc,'b',label='acc')
ax1.plot(x,val_acc,'r',label='val_acc')
ax1.set_xlabel('epoch')
ax1.set_ylabel('acc/val_acc')
ax1.set_title('acc and val_acc')
ax1.legend()
ax2.plot(x,loss,'r',label='loss')
ax2.plot(x,val_loss,'y',linestyle='--',label='val_loss')
ax2.set_xlabel('epoch')
ax2.set_ylabel('loss/val_loss')
ax2.set_title('loss and val_loss')
ax2.legend()
plt.show()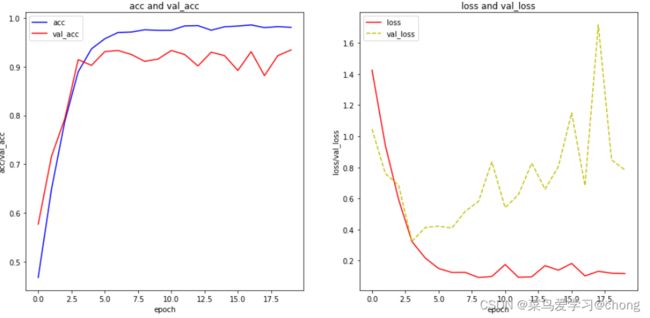
可以看出验证集精度低于训练集,模型存在过拟合,后续可继续改进网络,增强其泛化能力。