GAN 与人体姿态生成
GAN 与人体姿态生成
持续更新中…
Pose Guided Person Image Generation
概述
这篇文章主要解决的是人体姿态迁移的问题。具体就是给定一张原始图片和一个新的姿势,这个姿势使用关键点来表示的,网络的目的就是将原始图片的姿势转换到目标姿势。
方法
这篇文章将姿态迁移的任务分为了两个阶段,采用了 coarse-to-fine 的策略:首先生成比较模糊的图片,但是姿势已经是目标姿势的图片,然后再使用另一个网络对纹理颜色等内容进行还原。整体的网络结构如下:

第一步:姿态融合
在第一部里面,作者将一张原始图片 I A I_A IA 和一个姿态图片 P B P_B PB 同时放进一个神经网络里面,进行姿态融合,最终会得到一张变成了目标姿态的模糊图片。
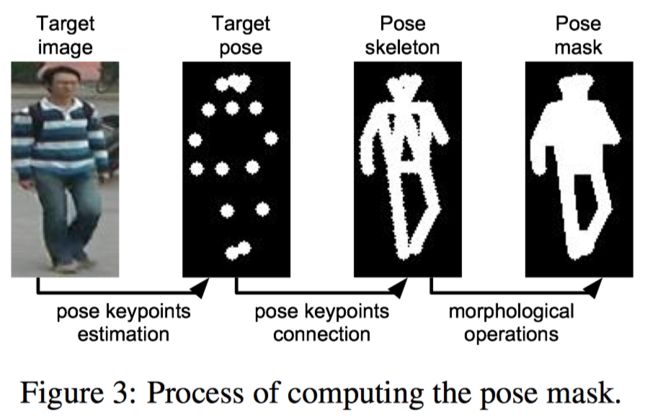
姿态的表示使用的是关键点,通过一个姿态估计网络输出人体姿态的 18 个关键点。作者将这 18 个关键点编码成 18 个热点图。每个图表示一个关键点,即在关键的位置用一个半径为 4 个像素的点来表示这个关键点。作者将原始图片和这个热点图拼接在一起送入第一步的姿态融合网络。
这个网络采用了 U-Net 的结构,相对应的网络层之间添加了 skip connection. 同时还是用了残差块 (Residual blocks) 来提高生成的效果。为了比较生成的图片 I ^ B 1 \hat{I}_{B1} I^B1 和目标图片 I B I_{B} IB,作者使用了 L 1 L_1 L1 损失。考虑到对于第一个网络来说生成背景可能会比较困难,所以提出了一种带 pose mask 的 L 1 L1 L1 损失,具体的表达式如下:
L G 1 = ∥ ( G 1 ( I A , I B ) − I B ) ⊙ ( 1 + M B ) ∥ 1 \mathcal{L}_{G1}=\Vert (G1(I_A,I_B)-I_B)\odot(1+M_B)\Vert_1 LG1=∥(G1(IA,IB)−IB)⊙(1+MB)∥1
在 pose mask M B M_B MB 里面前景置为 1,背景置为 0.
pose mask 的获得方法如下:
第二步:图像细化
在第一阶段已经通过模型已经生成了粗略的图片,在姿势和基本的颜色上面已经和目标图片接近了。在第二阶段,作者想要通过模型生成在第一阶段没有获得的那些细节。作者以条件 DCGAN 做为他们模型的基础,将第一阶段生成的图片作为条件输入。
考虑到在第一阶段已经生成了和目标图片在结构上很相似的图片了,所以第二阶段的生成器 G2 的目标就是一个输入和目标图片差异的图 (appearance difference map),有点类似于残差的思想。这个 difference map 也是通过一个 U-Net 结构的网络得到的。这个网络使用初步的结果 I ^ B 1 \hat{I}_{B1} I^B1 和条件图像 I A I_A IA 作为输入。相较于直接得到目标图像,使用 difference map 能够加快模型的收敛,因为模型只需要专注于初步生成的图像里面缺少了什么东西,特别是在第一阶段的时候模型已经生成了较为合理的结果。
第二阶段使用了判别损失。在传统的 GAN 里面,判别器是在真的图片和(由噪声)生成的假图片之间判断。但是在本文的网络里面,生成器是将条件图片 I A I_A IA 而不是随机噪声作为输入。因此,真实的图片不仅仅是那些自然的图片而且还要满足特定的要求。否则生成器 G2 会错误的直接输出 I A I_A IA 而不是去细化第一阶段产生的粗略图片 I ^ B 1 \hat{I}_{B1} I^B1,因为 I A I_A IA 本身就是真实的图片。为了解决这个问题,作者将 G2 的输出和条件图片配对,让判别器 D 去辨认图片对的真假,例如 ( I ^ B 2 , I A ) (\hat{I}_{B2}, I_A) (I^B2,IA) VS ( I B , I A ) (I_B, I_A) (IB,IA). 这个配对的输入能够鼓励 D 去学习 I ^ B 2 \hat{I}_{B2} I^B2 和 I B I_B IB 之间的区别,而不是仅仅去判别生成图片和自然图片。因此文章中对判别器 D 和 生成器 G2 的损失函数分别为:
L a d v D = L b c e ( D ( I A , I B ) , 1 ) + L b c e ( D ( I A , G 2 ( I A , I ^ B 1 ) ) , 0 ) \mathcal{L}^D_{adv}=\mathcal{L}_{bce}(D(I_A,I_B), 1)+\mathcal{L}_{bce}(D(I_A, G2(I_A,\hat{I}_{B1})),0) LadvD=Lbce(D(IA,IB),1)+Lbce(D(IA,G2(IA,I^B1)),0)
L a d v G = L b c e ( D ( I A , G 2 ( I A , I ^ B 1 ) ) , 1 ) \mathcal{L}^G_{adv}=\mathcal{L}_{bce}(D(I_A, G2(I_A,\hat{I}_{B1})),1) LadvG=Lbce(D(IA,G2(IA,I^B1)),1)
其中 L b c e \mathcal{L}_{bce} Lbce 表示二分类的交叉熵损失。为了让生成器 G2 能够更加注意目标人体的外貌而不是图片的背景,作者还使用了和第一阶段一样的 macked L1 损失,因此 G2 完整的损失函数如下:
L G 2 = L a d v G + λ ∥ ( G 2 ( I A , I ^ B 1 ) − I B ) ⊙ ( 1 + M B ) ∥ 1 \mathcal{L}_{G2}=\mathcal{L}^G_{adv}+\lambda\Vert (G2(I_A,\hat{I}_{B1})-I_B)\odot(1+M_B)\Vert_1 LG2=LadvG+λ∥(G2(IA,I^B1)−IB)⊙(1+MB)∥1
其中 λ \lambda λ 是 L1 损失的权重。它能够控制生成图片在低频部分有多接近目标图片。当 λ \lambda λ 较小的时候,判别损失主导训练,而且生成器更有可能生成新的物体;当 λ \lambda λ 较大的时候,L1 损失主导训练,这会使得整个模型生成模糊的图片。
Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks
概述
这篇文章提出了使用 ProGAN 生成高分辨率的动漫全真图像的方法,并且使用 Unity 3D 提供了一个姿势和对应图片的数据集。
方法
网络结构
这篇文章的作者借鉴了 ProGAN 的结构提出了 PSGAN (Progressive Structure-conditional GANs) 结构,网络的结构如下:

PSGAN 能够生成分辨率高达 1024 × 1024 1024\times1024 1024×1024 的全身图片。作者的主要改进就是通过逐步的添加身体姿势的条件来学习图片的生成。如上面的结构图所示,PSGAN 在每一次增加图片的分辨率的时候都会将身体的结构作为条件输入。上面的结构图中白色的方块表示能够学习卷积层,而灰色的方块表示不能学习的下采样层。不同于之前的 PG2,PSGAN 的输入是一个潜在变量,能够通过改变潜在变量的值来控制生成图片的服饰。训练过程与 ProGAN 的训练过程一致,通过多级训练依次提高生成图片的分辨率。
数据集
除了提出了 PSGAN,作者还使用 Unity 3D 生成了一个图片和姿势对应的数据集。这个数据集中包含了动漫人物的一系列动作以及这些的动作的身体结构 (使用 20 个关键点表示),这些动漫人物还有不同的服装样式。