决策树(信息熵、信息增益、信息增益率、基尼值和基尼指数、剪枝)
文章目录
-
-
-
- 一、概述
- 二、信息熵
- 三、信息增益
- 四、信息增益率
- 五、基尼值和基尼指数
- 六、剪枝
-
- 6.1 预剪枝
- 6.2 后剪枝
-
-
决策树(信息熵、信息增益、信息增益率、基尼值和基尼指数、剪枝)
一、概述
决策树(decision tree) 是一类常见的机器学习方法,是基于树结构来进行决策的,也称“判定树”。
一棵决策树包含一个根结点、若干个内部结点和若干个叶结点:
- 叶结点对应决策结果
- 其他每个结点则对应于一个属性测试
每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集。从根结点到每个叶结点的路径对应了一个判定测试序列。其基本流程遵循简单且直观的"分而治之" (divide-and-conquer) 策略。
决策树的生成是一个递归过程,有三种情形会导致递归返回:
- 当前结点包含的样本全属于同一类别,无需划分
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分—>把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别
- 当前结点包含的样本集合为空,不能划分—>把当前结点标记为叶结点,并将其类别设定为其父结点所含样本最多的类别
一棵仅有一层划分的决策树,亦称"决策树桩" (decision stump)。
二、信息熵
决策树生成中的关键问题:如何选择最优划分属性。
一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的"纯度" (purity) 越来越高。
"信息熵" (information entropy) 是度量样本集合纯度最常用的一种指标。假定当前样本集合中第k类样本所占的比例为 Pk (k = 1, 2,. . . , IYI) ,则的信息熵定义为:

信息熵的值越小,代表样本集合D的纯度越高。
三、信息增益
假定离散属性 a 有 V 个可能的取值{a1,a2,…,av},若使用 a 来对样本集 D 进行划分,则会产生 V 个分支结点。其中第 v 个分支结点包含了 D 中所有在属性 a 上取值为 av 的样本,记为 Dv。我们可计算出Dv的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 IDvI / IDI,即样本数越多的分支结点的影响越大,于是可计算出用属性 a 对样本集 D 进行划分所获得的"信息增益" (information gain) 定义为:

某个属性计算得到的信息增益越大,则意味着使用该属性来进行划分所获得的"纯度提升"越大。因此,可以用信息增益来进行决策树的划分属性选择。
著名的 ID3 决策树学习算法[Quinlan 1986] 就是以信息增益为准则来选择划分属性。
四、信息增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan 1993J 不直接使用信息增益,而是使用"信息增益率" (gain ratio) 来选择最优划分属性。信息增益率定义为:

IV(a) 称为属性a的"固有值" (intrinsic value)。属性a的可能取值数目越多,则 IV(a) 的值通常会越大。
需注意的是,增益率准则对可取值数目较少的属性有所偏好。因此 C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
五、基尼值和基尼指数
CART 决策树 [Breiman et al., 1984] 使用"基尼指数" (Gini index) 来选择划分属性。数据集 D 的纯度可用基尼值来度量,定义为:
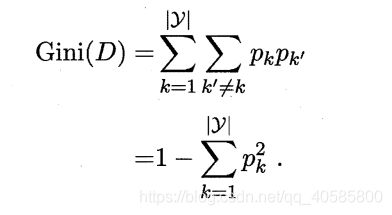
直观的讲, 基尼值 Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记不一致的概率。因此,基尼值 Gini(D) 越小,则数据集 D 的纯度越高。针对某一具体属性 a ,其基尼指数定义为:

在候选属性集合中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
六、剪枝
剪枝(pruning) 是决策树学习算法**对付"过拟合"**的主要手段。剪枝操作可以通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有**“预剪枝” (prepruning) 和"后剪枝"(post pruning)。**
6.1 预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
- 优点:预页剪枝使得决策树的很多分支都没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。
- 缺点:有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降。但在其基础上进行的后续划分却有可能导致性能显著提高。预剪枝基于"贪心"本质禁止这些分支展开,给预剪枝决策树带来了欠拟含的风险。
6.2 后剪枝
后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
后剪枝决策树通常比预剪枝决策树保留了更多的分支。
- 优点:后剪枝决策树的欠拟合风险很小,泛化能力往往优于预剪枝决策树。
- 缺点:后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。