【论文笔记】On the Connection between Local Attention and Dynamic Depth-wise Convolution
论文

论文标题:On the Connection between Local Attention and Dynamic Depth-wise Convolution
收录于:ICLR 2022 Spotlight
论文地址:https://arxiv.org/abs/2106.04263
项目地址:GitHub - Atten4Vis/DemystifyLocalViT: Official code for paper "On the Connection between Local Attention and Dynamic Depth-wise Convolution" ICLR 2022 Spotlight
参考博客:ICLR 2022 Spotlight: Transformer不比CNN强!Local Attention和动态Depth-wise卷积的前世今生 - 知乎(ICLR-2022)关于局部注意力和动态深度卷积之间的联系(附录)_顾道长生'的博客-CSDN博客
(ICLR-2022)关于局部注意力和动态深度卷积之间的联系_顾道长生'的博客-CSDN博客_局部注意力
【卷积 与 Attention 解析】Demystifying Local Vision Transformer - 知乎
摘要
Vision Transformer (ViT) 在视觉识别方面取得了最先进的性能,而变体 Local Vision Transformer 进一步改进。 Local Vision Transformer 中的主要组件,局部注意力,在小的局部窗口上分别执行注意力。将局部注意力重新表述为通道方式的局部连接层,并从稀疏连接和权重共享两种网络正则化方式以及动态权重计算来对其进行分析。作者指出,局部注意力类似于深度卷积及其在稀疏连接中的动态变体:通道之间没有连接,每个位置都连接到一个小的局部窗口内的位置。主要区别在于:(i)权重共享,depth-wise convolution 共享空间位置之间的连接权重(内核权重),attention 共享通道间的连接权重,以及(ii)动态权重计算方式,局部注意力是基于局部窗口中成对位置之间的点积,动态卷积基于对中心表示或全局池化表示进行的线性投影。
局部注意力和动态深度卷积之间的联系通过对Local Vision Transformer和(动态)深度卷积中权重共享和动态权重计算的消融研究进行了实验验证。凭实验观察到,基于深度卷积的模型和计算复杂度较低的动态变体在 ImageNet 分类、COCO 目标检测和 ADE 语义分割方面的表现与 Swin Transformer(Local Vision Transformer 的一个实例)相当或略好。
前言
Vision Transformer在 ImageNet 分类中显示出可观的性能。改进的变体 Local Vision Transformer采用局部注意力机制,将图像空间划分为一组小窗口,并且同时将注意力转移到窗口上。局部注意力极大地提高了内存和计算效率,并使下游任务的扩展更容易和更有效,例如目标检测和语义分割。
作者利用网络正则化方案、控制模型复杂性的稀疏连接、放宽增加训练数据规模和减少模型参数的要求的权重共享,以及增加的动态权重预测模型能力,研究局部注意力机制。将局部注意力重新表述为具有动态连接权重的通道方式空间局部连接层。主要性能总结如下。 (i) 稀疏连接:没有跨通道连接,每个输出位置只连接到局部窗口内的输入位置。 (ii) 权重共享:连接权重在通道之间或每组通道内共享。 (iii) 动态权重:根据每个图像实例动态预测连接权重。
将局部注意力与深度卷积及其动态变体联系起来,这些变体也是具有可选动态连接权重的通道空间局部连接层。它们在稀疏连接上是相似的。主要区别在于(i)权重共享,depth-wise convolution 共享空间位置之间的连接权重(内核权重),attention 共享通道间的连接权重,以及(ii)动态权重计算方式,局部注意力是基于局部窗口中成对位置之间的点积,动态卷积基于对中心表示或全局池化表示进行的线性投影。
作者进一步提出了连接的实验验证。以最近开发的 Local Vision Transformer Swin Transformer为例,研究在与 Swin Transformer 相同的训练设置下局部注意力和(动态)深度卷积的实验性能。用(动态)深度卷积层替换局部注意力层,保持整体结构不变。
结果表明,基于(动态)深度卷积的方法在 ImageNet 分类和两个下游任务 COCO 目标检测和 ADE 语义分割方面实现了相当或略高的性能,并且(动态)深度卷积需要更低的计算复杂度。消融研究表明权重共享和动态权重提高了模型的能力。具体来说,(i) 对于 Swin Transformer,跨通道的权重共享主要有利于降低参数(注意力权重)复杂度,基于注意力的动态权重方案有利于学习特定于实例的权重和block-translation等价表示; (ii) 对于深度卷积,跨位置的权重共享有利于降低参数复杂度以及学习平移等效表示,并且基于线性投影的动态权重方案学习特定于实例的权重。
Local Attention
Local Attention本质上是在一个2D Local Window内进行特征聚合,其每个位置的聚合权重可以通过KQV之间计算Attention Similarity得到(主要包括dot-production, scaling, softmax),是一个无参数的、动态计算的局部特征计算模块。
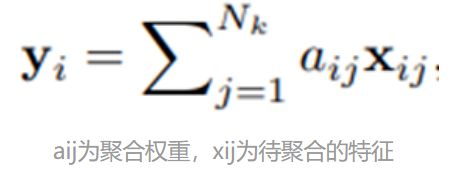
本文早期版本(Demystifying Local Vision Transformer)分析了Local Attention三个强大的设计原则:
(1) 稀疏连接——指一些输出变量和一些输入变量之间没有相互连接。它有效地减少了模型的复杂度而不减少输入输出变量个数。在Local Attention当中,稀疏连接体现在两个方面:一是Local Attention在图像空间上,每一个输出值仅与局部的Local Window内的输入相连接,与ViT的全像素(token)连接不同。二是Local Attention在通道上,每一个输出通道仅与一个输入通道连接,没有交叉连接,不同于group convolution与normal convolution。
(2) 权重共享——意味着有一些连接的权重是相同且共享的,它降低了模型的参数量,同时不需要增加训练数据即可增强模型。在模型中,一个权重被共享使用可以被认为针对该权重的训练样本增加,有助于模型的优化。在Local Attention中,权重共享通过multi-head self-attention来实现,再把通道分成head(group),在同一个head内共享使用一组聚合权重,降低聚合权重的参数量(非模型参数量)。
(3) 动态权重——指根据不同样本的特征,动态地产生连接权重。它能够增加模型的容量。如果把连接权重看作是隐层变量,那么这种动态权重可以看作是增加模型容量的二阶操作。Local Attention的动态权重体现在每一个连接的聚合权重都是根据样本特征使用基于dot-product的方式计算得到的。
通过以上三个模型设计原则,Local Attention表现出优异的效果。然而,这些特性也天然存在于CNN结构当中,尤其是(Dynamic)Depth-wise卷积。
Depth-wise 卷积和 Local Attention的关联性
逐步拆解Local Attention的操作,可以发现在稀疏连接、权重共享、动态权重三个维度上,都与“历史霸主”CNN结构中的(Dynamic)Depth-wise卷积很相似。Depth-wise卷积可谓是一个被长期使用又被渐渐遗忘在历史长河中的结构,那么其在模型设计上又有哪些准则呢?
(1) 稀疏连接。不难发现,Depth-wise卷积的稀疏连接特性与Local Attention完全相同,在图像空间上局部链接,在通道上稀疏连接。
(2) 权重共享。权重共享的概念最初就诞生于卷积操作之中,Depth-wise卷积同样得益于权重共享操作,但与Local Attention略有不同,Depth-wise卷积在图像空间上共享权重,每一个空间位置都是用相同权重的卷积核来进行特征聚合,而在通道上,每一个通道会使用独立的聚合权重。
(3) 动态权重。动态权重的设计原则在原始的Depth-wise卷积中并没有被使用,然而,动态卷积作为一个被广泛研究的领域,可以轻易地将动态特性引入Depth-wise卷积中,形成特征依赖的聚合权重。
尽管在权重共享上两者的共享方式不同,但经过实验发现,以Local MLP(去掉dynamic特性的local attention)为例,在通道和空间维度上共享权重的影响并不大,在任何一个维度共享权重,均可以降低模型的参数量,帮助模型优化。而在动态权重上,虽然两者不同,但Depth-wise卷积仍然可以轻易具备动态特性。
Local Attention与Depth-wise卷积的关联
Local Attention
Vision Transformer通过重复注意力层和随后的逐点 MLP(逐点卷积)形成网络。局部 Vision Transformer,如Swin Transformer和HaloNet,采用局部注意力层,将空间划分为一组小窗口并进行注意力操作每个窗口内同时进行,以提高内存和计算效率。


稀疏连接、权重共享、动态权重
简要介绍了两种正则化形式,稀疏连接和权重共享,以及动态权重,以及它们的好处。将使用这三种形式来分析局部注意力并将其连接到动态深度卷积。
稀疏连通性意味着一层中的一些输出神经元(变量)和一些输入神经元之间没有连接。它在不减少神经元数量的情况下降低了模型复杂度,例如(隐藏)表示的大小。
权重共享表示某些连接权重是相等的。它减少了模型参数的数量并增加了网络大小,而无需相应增加训练数据。
动态权重是指为每个实例学习专门的连接权重。它通常旨在增加模型容量。如果将学习到的连接权重视为隐藏变量,则动态权重可以被视为引入增加网络能力的二阶操作。
分析 LOCAL ATTENTION
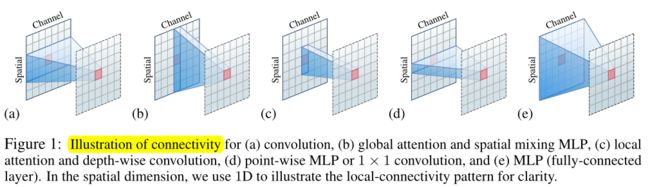 图 1:(a) 卷积、(b) 全局注意力和空间混合 MLP、(c)局部注意力和深度卷积、(d) 逐点 MLP 或1 × 1卷积 、(e) MLP(全连接层)。在空间维度上,为了清楚起见,使用一维来说明局部连接模式。
图 1:(a) 卷积、(b) 全局注意力和空间混合 MLP、(c)局部注意力和深度卷积、(d) 逐点 MLP 或1 × 1卷积 、(e) MLP(全连接层)。在空间维度上,为了清楚起见,使用一维来说明局部连接模式。
局部注意力是一个通道方式的空间局部连接层,具有动态权重计算,并讨论了它的属性。图 1 (c) 说明了连接模式。



与DYNAMIC DEPTH-WISE CONVOLUTION的关联


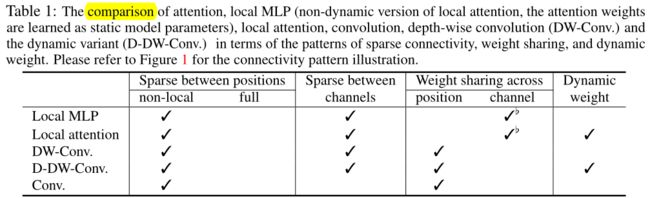
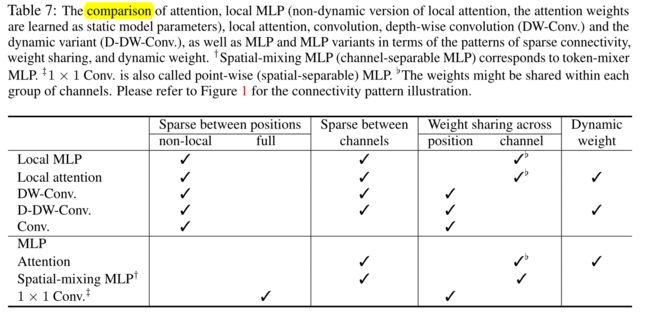
作者描述了(动态)深度卷积和局部注意力之间的异同。图 1 (c)说明了连接模式,表 1 显示了局部注意力和深度卷积以及各种其他模块之间的属性。
相似点。深度卷积类似于稀疏连接中的局部注意力。没有跨通道的连接。每个位置仅连接到每个通道的小局部窗口中的位置。
不同点。一个主要区别在于权重共享:深度卷积在空间位置之间共享连接权重,而局部注意力在通道之间或每组通道内共享权重。局部注意力使用适当的跨通道权重共享来获得更好的性能。深度卷积受益于跨位置的权重共享,以降低参数复杂度并提高网络能力。
第二个区别是深度卷积的连接权重是静态的并且作为模型参数学习,而局部注意力的连接权重是动态的并且从每个实例预测。深度卷积的动态变体也受益于动态权重。
另一个区别在于窗口表示。局部注意力通过使用丢失空间顺序信息的集合形式来表示窗口中的位置。它使用位置嵌入隐含地探索空间顺序信息,或使用学习的所谓的相对位置嵌入显式探索空间顺序信息。深度卷积利用向量形式:聚合局部窗口内的表示,权重由相对位置索引(参见公式 6);保持不同窗口位置之间的空间对应关系,从而明确地探索空间顺序信息。
实验
实验细节&结果
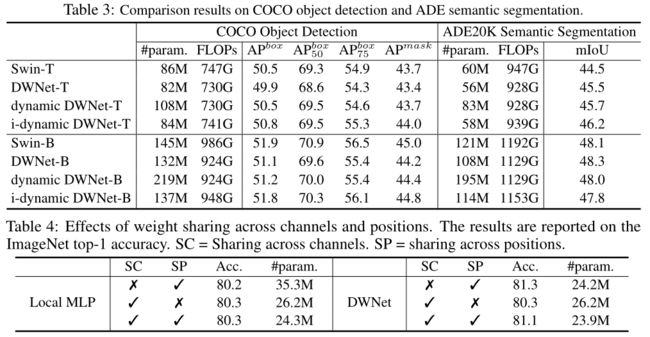
实验细节。以Swin Transformer为例,按照Swin-T和Swin-B两个网络的结构,构建两个基于深度卷积的网络:DWNet-T和DWNet-B,以及两个动态版本Dynamic DWNet 和 i-Dynamic DWNet。简单将Swin Transformer中的局部注意力替换为相同窗口大小的深度卷积,其中值上的线性投影用1*1卷积替代。卷积网络加入BN和ReLU取代LN。
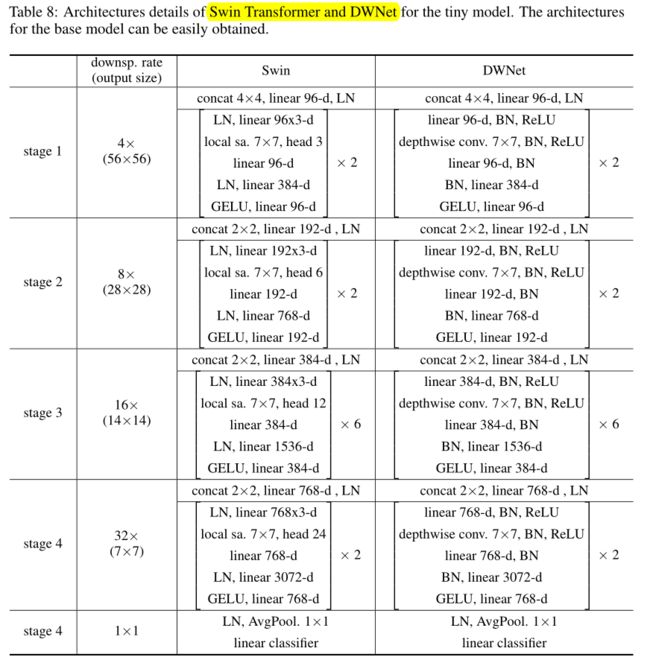
图像分类、目标检查、语义分割 结果。
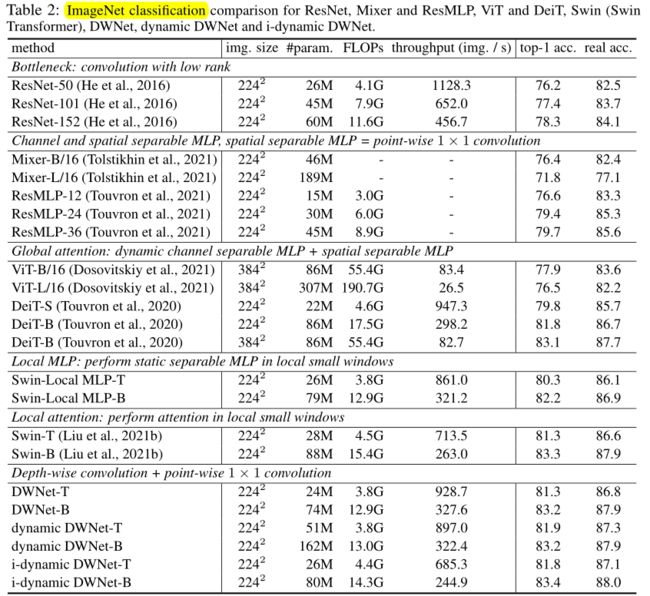
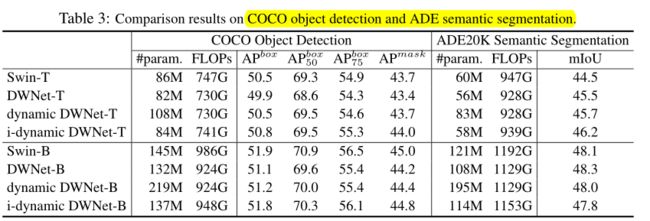
Depth-wise卷积的表现力。
两种动态DW卷积:
(1)D-DW-Conv。第一种动态DW卷积,采用了和普通DW卷积相同的权重共享方式——图像空间共享卷积核和通道间独立卷积核。并使用了Global Average Pooling来处理输入特性,然后通过FC Layer来动态地预测出动态卷积核。
(2)I-D-DW-Conv。第二种动态DW卷积,采用了和Local Attention相同的权重共享方式,每个像素(token)采用独立的聚合权重,而在通道head(group)中共享权重。称为Inhomogeneous Dynamic DW卷积。
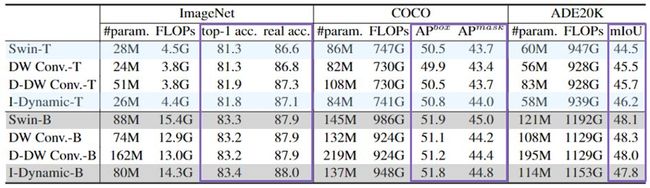
通道与空间上权重共享的影响。
实证分析
局部和通道可分离的连接已被证明有助于视觉识别。表2中的经验结果也验证了这一点,例如,局部注意比全局注意(局部连接)表现更好,深度卷积比卷积(通道可分离连接)表现更好。以微小模型为例,给出了权重分担和动态权重的实证结果。
 (A)局部MLP-静态权重和(B)局部注意-动态权重的影响
(A)局部MLP-静态权重和(B)局部注意-动态权重的影响
权重共享。研究对于局部注意和局部MLP(学习每个窗口中的权重作为模型参数而不是跨窗口共享),每个组中共享权重的通道数量(每个阶段的注意力头部的数量相应地改变)对性能的影响。图2显示了(A)局部MLP-静态权重和(B)局部注意-动态权重的影响。可以看出,对于局部关注,每组中太多和太少的通道表现相似,但不会导致最好的结果。对于局部MLP,加权显著地减少了模型参数。这表明,在不同通道之间进行适当的权重共享对局部注意力和局部MLP都有帮助。
进一步研究局部MLP和DWNet权重共享模式的结合效果。对于局部MLP,跨位置的权重共享意味着局部MLP中不同空间块的连接权重被共享。对于卷积,在局部注意方面,跨通道权重共享的方案类似于多头方式。表4中的结果表明:(i)对于局部MLP,跨通道共享权重会减少模型参数,而跨空间块共享不会有太大影响;(ii)对于深度卷积,跨通道共享权重不会有很大影响,但跨位置共享权重会显著提高性能。
局部MLP和DWNet的窗口采样方案不同:局部MLP采用Swin Transformer的方法对窗口进行稀疏采样,以降低较高的存储开销,而DWNet对窗口进行密集采样。局部MLP中位置之间的权重共享不足以学习平移等价表示,这解释了为什么具有跨通道和位置的权重共享的局部MLP的性能低于在通道之间具有额外权重共享的深度卷积。
动态权重。研究局部注意中的动态权重如何影响效果。从表2可以看出,局部MLP实现了静态版本,tiny和base模型分别为80.3%和82.2%,低于动态版本Swin,分别为81.3%和83.3%。这意味着动态权重是有帮助的。动态加权对深度卷积的改善也被观察到(表2)。
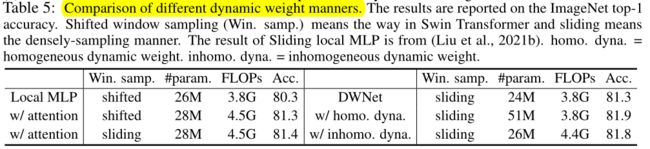
进一步研究注意方案和线性投影方案对动态权重计算的影响。表5中的观察结果包括:移位窗口采样和滑动窗口采样的注意机制表现相似;非均匀动态权重计算方法优于注意机制(81.8vs81.4)。后一种现象的原因包括:对于注意机制,表征只是块的平移不变性,而非其他的平移不变性(for the attention mechanism the representation is only block translation equivalent other than any translation equivalent);基于线性投影的动态权重方案(窗口的矢量表示)比基于注意力的方案(窗口的集合表示)学习更好的权重。对于大型模型和检测任务,这种影响被消除了。
集合表示。局部注意将窗口中的位置表示为具有丢失的空间顺序信息的集合。Swin Transformer学习相对位置嵌入,其中窗口中的位置实际上被描述为保持空间顺序信息的矢量。在(Liu et al.,2021b)中报道,去除相对位置嵌入会导致1.2%的精度下降,表明空间顺序信息是重要的。
结论
局部注意和动态深度卷积之间的关系总结如下:
- 与动态深度卷积一样,局部注意受益于两种稀疏连接形式:局部连接和跨通道无连接。
- 局部注意的跨通道加权有助于降低参数(注意权重)的复杂度,略有提高性能;深度卷积的跨位置加权有助于降低参数复杂度,学习平移等价表征,从而提高性能。
- 基于注意力的局部注意动态权重计算有利于学习图像相关权值和块平移等价表征,基于线性投影的齐次动态深度卷积动态权重计算有利于学习图像相关权值。
附录
详见(ICLR-2022)关于局部注意力和动态深度卷积之间的联系(附录)_顾道长生'的博客-CSDN博客
文章构建一个Relation Graph来阐述模型结构设计中产生的一些设计原则上的演进过程:
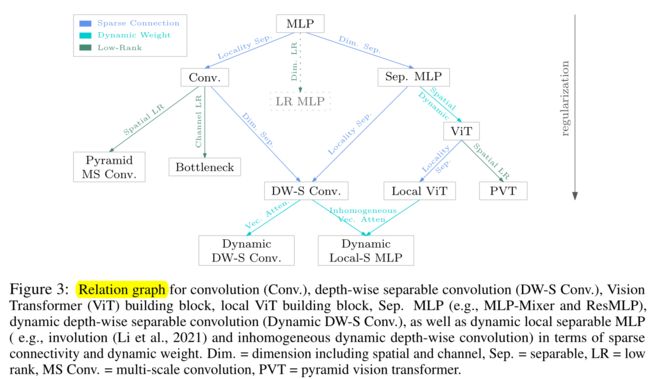 图中ViT和Local ViT指结构中的Attention结构,PVT为低秩形式下的金字塔结构Transformer,Dim. Sep.表示通道维度上稀疏化,Locality Sep.表示空间位置连接稀疏化,LR表示低秩,MS Conv.表示多尺度卷积。
图中ViT和Local ViT指结构中的Attention结构,PVT为低秩形式下的金字塔结构Transformer,Dim. Sep.表示通道维度上稀疏化,Locality Sep.表示空间位置连接稀疏化,LR表示低秩,MS Conv.表示多尺度卷积。
关系图中,从上到下呈现了依次增强的正则化方式或引入动态权重,随着正则化及动态权重的增加,网络的人为先验也随之增加。这种形式带来了优化上的好处,使得网络更容易训练并得到更好的结果,现有实验结果也同样验证了此项结论。最终这种稀疏化与动态性上的演进,会走向基于Depth-wise卷积的动态卷积,结合现代Large kernel的训练原则,将能够实现更好的表现效果。
代码
DynamicDWConv
# https://github.com/Atten4Vis/DemystifyLocalViT/blob/master/models/dwnet.py
# 声明:self.conv = DynamicDWConv(dim, kernel_size=window_size, stride=1, padding=window_size // 2, groups=dim)
# 调用:x = self.conv(x)
class DynamicDWConv(nn.Module):
def __init__(self, dim, kernel_size, bias=True, stride=1, padding=1, groups=1, reduction=4):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.groups = groups
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv1 = nn.Conv2d(dim, dim // reduction, 1, bias=False)
self.bn = nn.BatchNorm2d(dim // reduction)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(dim // reduction, dim * kernel_size * kernel_size, 1)
if bias:
self.bias = nn.Parameter(torch.zeros(dim))
else:
self.bias = None
def forward(self, x):
b, c, h, w = x.shape
weight = self.conv2(self.relu(self.bn(self.conv1(self.pool(x)))))
weight = weight.view(b * self.dim, 1, self.kernel_size, self.kernel_size)
x = F.conv2d(x.reshape(1, -1, h, w), weight, self.bias.repeat(b), stride=self.stride, padding=self.padding, groups=b * self.groups)
x = x.view(b, c, x.shape[-2], x.shape[-1])
return xIDynamicDWConv
# https://github.com/Atten4Vis/DemystifyLocalViT/blob/master/models/idynamic.py
# 声明:self.conv = IDynamicDWConv(dim, window_size, heads)
# 调用:x = self.conv(x)
class _idynamic(Function):
@staticmethod
def forward(ctx, input, weight, stride, padding, dilation):
assert input.dim() == 4 and input.is_cuda
assert weight.dim() == 6 and weight.is_cuda
batch_size, channels, height, width = input.size()
kernel_h, kernel_w = weight.size()[2:4]
output_h = int((height + 2 * padding[0] - (dilation[0] * (kernel_h - 1) + 1)) / stride[0] + 1)
output_w = int((width + 2 * padding[1] - (dilation[1] * (kernel_w - 1) + 1)) / stride[1] + 1)
output = input.new(batch_size, channels, output_h, output_w)
n = output.numel()
with torch.cuda.device_of(input):
f = load_kernel('idynamic_forward_kernel', _idynamic_kernel, Dtype=Dtype(input), nthreads=n,
num=batch_size, channels=channels, groups=weight.size()[1],
bottom_height=height, bottom_width=width,
top_height=output_h, top_width=output_w,
kernel_h=kernel_h, kernel_w=kernel_w,
stride_h=stride[0], stride_w=stride[1],
dilation_h=dilation[0], dilation_w=dilation[1],
pad_h=padding[0], pad_w=padding[1])
f(block=(CUDA_NUM_THREADS,1,1),
grid=(GET_BLOCKS(n),1,1),
args=[input.data_ptr(), weight.data_ptr(), output.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
ctx.save_for_backward(input, weight)
ctx.stride, ctx.padding, ctx.dilation = stride, padding, dilation
return output
@staticmethod
def backward(ctx, grad_output):
assert grad_output.is_cuda
if not grad_output.is_contiguous():
grad_output.contiguous()
input, weight = ctx.saved_tensors
stride, padding, dilation = ctx.stride, ctx.padding, ctx.dilation
batch_size, channels, height, width = input.size()
kernel_h, kernel_w = weight.size()[2:4]
output_h, output_w = grad_output.size()[2:]
grad_input, grad_weight = None, None
opt = dict(Dtype=Dtype(grad_output),
num=batch_size, channels=channels, groups=weight.size()[1],
bottom_height=height, bottom_width=width,
top_height=output_h, top_width=output_w,
kernel_h=kernel_h, kernel_w=kernel_w,
stride_h=stride[0], stride_w=stride[1],
dilation_h=dilation[0], dilation_w=dilation[1],
pad_h=padding[0], pad_w=padding[1])
with torch.cuda.device_of(input):
if ctx.needs_input_grad[0]:
grad_input = input.new(input.size())
n = grad_input.numel()
opt['nthreads'] = n
f = load_kernel('idynamic_backward_grad_input_kernel',
_idynamic_kernel_backward_grad_input, **opt)
f(block=(CUDA_NUM_THREADS,1,1),
grid=(GET_BLOCKS(n),1,1),
args=[grad_output.data_ptr(), weight.data_ptr(), grad_input.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
if ctx.needs_input_grad[1]:
grad_weight = weight.new(weight.size())
n = grad_weight.numel()
opt['nthreads'] = n
f = load_kernel('idynamic_backward_grad_weight_kernel',
_idynamic_kernel_backward_grad_weight, **opt)
f(block=(CUDA_NUM_THREADS,1,1),
grid=(GET_BLOCKS(n),1,1),
args=[grad_output.data_ptr(), input.data_ptr(), grad_weight.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
return grad_input, grad_weight, None, None, None
def _idynamic_cuda(input, weight, bias=None, stride=1, padding=0, dilation=1):
""" idynamic kernel
"""
assert input.size(0) == weight.size(0)
assert input.size(-2)//stride == weight.size(-2)
assert input.size(-1)//stride == weight.size(-1)
if input.is_cuda:
out = _idynamic.apply(input, weight, _pair(stride), _pair(padding), _pair(dilation))
if bias is not None:
out += bias.view(1,-1,1,1)
else:
raise NotImplementedError
return out
class IDynamicDWConv(nn.Module):
def __init__(self,
channels,
kernel_size,
group_channels):
super(IDynamicDWConv, self).__init__()
self.kernel_size = kernel_size
self.channels = channels
reduction_ratio = 4
self.group_channels = group_channels
self.groups = self.channels // self.group_channels
self.conv1 = nn.Sequential(
nn.Conv2d(channels, channels // reduction_ratio, 1),
nn.BatchNorm2d(channels // reduction_ratio),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(channels // reduction_ratio, kernel_size**2 * self.groups, 1)
)
def forward(self, x):
weight = self.conv2(self.conv1(x))
b, c, h, w = weight.shape
weight = weight.view(b, self.groups, self.kernel_size, self.kernel_size, h, w)
out = _idynamic_cuda(x, weight, stride=1, padding=(self.kernel_size-1)//2)
return