BOAT: Bilateral Local Attention Vision Transformer
BOAT Attention
论文标题:BOAT: Bilateral Local Attention Vision Transformer
论文地址:http://arxiv.org/pdf/2201.13027v1
开源代码:
百度实验室
Introduction
VIT采用全局自我注意,当patch的数量很大时,计算成本是昂贵的。为了提高效率,最近VIT采用了局部自注意机制,即在局部窗口内计算自注意。尽管基于窗口的局部自注意显著提高了效率,但它未能捕捉到图像平面上遥远但相似的patch之间的关系。
利用patch的特征将patch划分为多个簇,并在每个簇内计算自我注意。这种特征空间的局部注意有效地捕获了跨不同局部窗口的patch之间的连接,但仍然是相关的。提出了一种双侧局部注意VIT(BOAT),它将特征空间局部注意与图像空间局部注意相结合。进一步将BOAT与Swin和CSWin模型集成,并在几个基准数据集上的大量实验表明,BOAT-CSWin模型明显且始终地优于现有的最先进的CNN模型和传统的VIT。
Motivation
为了保持更高的特征图分辨率,一些方法利用图像空间局部关注。它们将一个图像划分为多个local window,每个local window都包含许多patches。自我注意操作只在同一local window内的patch上执行。这是一个合理的设计,因为一个patch很可能与同一local window中的其他patch相关联,但与其他窗口中的patch并不高度相关。因此,从不同窗口的patch之间修剪注意力可能不会显著降低性能。同时,基于窗口的自注意在整个图像上的计算成本远低于原始的自注意。
在这项工作中,重新思考local attention,并从更广泛的角度探索local window。具体地说,研究特征空间local attention,除了它的图像空间对应。feature-space local attention利用特征空间中的局部性,而不是计算图像空间中的 image-space counterpart。这是基于在特征空间中彼此接近的斑块特征向量在计算的自注意结果中往往有更多的相互影响。

feature-space local attention仅利用其特征空间最近邻计算特征向量上的自注意结果,同时将距离较远的特征向量的影响因子设为零。
这本质上定义了一个分段相似度函数,它将特征向量之间的相似度近似于零。与image-space local attention相比,feature-space local attention在VIT模型中很少得到利用。feature-space local attention计算的是在图像平面上可能彼此不接近的相关斑块之间的注意。因此,它是对image-space local attention的一种补偿,它可能会错过位于不同局部窗口中的补丁之间的有意义的连接。
在本文中,提出了一种新的VIT结构,双侧聚焦注意视觉变换器(BOAT),以利用特征空间和图像空间局部注意之间的互补性。网络结构的基本组成部分是双边局部注意块,由特征空间局部注意模块和图像空间局部注意模块组成。
Method
所提出的架构由一个patch embedding模块和一堆L个双边局部注意块组成。同时,我们利用了一个层次化的金字塔结构。

Patch embedding
遵循swin-transformer和SCwin Transformer的patch embedding设定,输入图像大小为 H × W H\times W H×W, 7 × 7 7\times 7 7×7的卷积,stride为4,获得 H 4 × W 4 \frac {H}{4}\times \frac {W}{4} 4H×4W个patches,每个token的维度为C。
Hierarchical pyramid structure
与swin Transformer一致,patch merging的作用一致,将每个block的输出下采样2倍,并扩展输出的维度,为上一层输出的2倍。详细可以看Swin的论文。
Bilateral Local Attention Block
由一个image-space local attention(Isla)模块、一个feature-space local attention(FSLA)模块、一个MLP模块和几个层归一化(LN)模块组成。

定义 T i n = { t i } i = 1 N \mathcal {T}_{in}=\lbrace t_{i}\rbrace_{i=1}^{N} Tin={ti}i=1N表示输入标记的集合,其中 t i ∈ R C t_{i}\in \R^{C} ti∈RC, C C C是通道数, N N N是token 数。输入token经过一个归一化层,然后是一个图像空间局部注意(Isla)模块,该模块有一个shortcut:
T I S L A = T i n + I S L A ( L N ( T i n ) ) \mathcal {T}_{ISLA}=\mathcal {T}_{in}+ISLA(LN(\mathcal {T}_{in})) TISLA=Tin+ISLA(LN(Tin))
这里的image space local window 也是跟swin Transformer中的non shift window一样的设置,都是将特征图分割为不同的window,在每一个window上做注意力计算。
FSLA模块计算在feature space中接近的tokens之间的自我注意,这是对ISLA模块的补充。
![]()
同时,通过只考虑特征空间中的局部注意,FSLA比原始的(全局的)自注意更有效。我们还向每个feature-space local attention层添加局部增强的位置编码来建立模型位置。
最后,将FSLA模块TFSLA的输出由另一个归一化层和一个MLP模块进行处理,生成一个双边局部注意块的输出
![]()
MLP模块由两个全连接层组成。第一个是将特征维度从 C C C增加到 r C rC rC,第二个是将特征维度从 r C rC rC减少到 C C C。默认情况下,设置 r = 4 r=4 r=4。
Feature-Space Local Attention
这里是本文的重点
与image-space local attention根据标记在图像平面上的空间位置对其进行分组不同,feature-space local attention试图根据标记的内容进行分组,即对特征进行分组。我们可以简单地对tokens特性执行Kmeans聚类来实现这个目标。然而,K-means聚类不能确保生成的集群大小相同,这使得在GPU平台上难以有效地并行实现,也可能对自我注意的整体有效性产生负面影响。
Balanced hierarchical clustering
为了克服K-means聚类的不平衡问题,提出了一种平衡层次聚类,它进行K级聚类。在每一层,它进行平衡的二元聚类,将一组标记平等地分割为两个集群。定义用 T i n = { t i } i = 1 N \mathcal {T}_{in}=\lbrace t_{i}\rbrace_{i=1}^{N} Tin={ti}i=1N来表示输入token的集合。在第一层中,它将 T T T中的 N N N个tokens分成两个子集,每个子集都有 N 2 \frac {N}{2} 2N个标记。在第k层,它将分配给上层同一子集的 N 2 k − 1 \frac {N}{2^{k}-1} 2k−1N标记分割为两个 N 2 \frac {N}{2} 2N大小的较小的子集。最后,在最终层上得到 2 k 2^{k} 2k均匀大小的子集, { T i } i = 1 2 k \lbrace \mathcal {T}_{i} \rbrace_{i=1}^{2^{k}} {Ti}i=12k,每个子集 ∣ T i ∣ |T_i| ∣Ti∣的大小等于 N 2 k \frac{N}{2^{k}} 2kN。
在这里,我们要求 N N N是可被 2 k 2^{k} 2k整除的条件,这在现有的VIT中可以很容易地得到满足。

Balanced binary clustering.
给定一组 2 m 2m 2mtokens$ \lbrace t_i \rbrace^{2m}_{i=1} , 平 衡 二 元 聚 类 将 其 分 为 两 组 , 每 组 的 大 小 为 ,平衡二元聚类将其分为两组,每组的大小为 ,平衡二元聚类将其分为两组,每组的大小为m 。 与 K − m e a n s 聚 类 类 似 , 我 们 的 平 衡 二 进 制 聚 类 依 赖 于 聚 类 质 心 。 为 了 确 定 每 个 样 本 的 聚 类 分 配 , K − m e a n s 聚 类 只 考 虑 样 本 与 所 有 质 心 之 间 的 距 离 。 二 分 平 衡 聚 类 进 一 步 要 求 所 产 生 的 两 个 集 群 具 有 相 同 的 大 小 。 将 两 个 簇 质 心 表 示 为 。与K-means聚类类似,我们的平衡二进制聚类依赖于聚类质心。为了确定每个样本的聚类分配,K-means聚类只考虑样本与所有质心之间的距离。二分平衡聚类进一步要求所产生的两个集群具有相同的大小。将两个簇质心表示为 。与K−means聚类类似,我们的平衡二进制聚类依赖于聚类质心。为了确定每个样本的聚类分配,K−means聚类只考虑样本与所有质心之间的距离。二分平衡聚类进一步要求所产生的两个集群具有相同的大小。将两个簇质心表示为c1 和 和 和c2 。 对 于 每 个 标 记 。对于每个标记 。对于每个标记t_i , 计 算 距 离 比 ,计算距离比 ,计算距离比r_i$,作为一个度量来确定其集群分配:
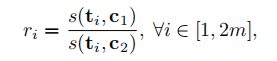
其中, s ( x 、 y ) s(x、y) s(x、y)表示 x x x和 y y y之间的余弦相似度。 2 m 2m 2mtokens的 { t i } i = 1 2 m \lbrace t_i \rbrace^{2m}_{i=1} {ti}i=12m按其距离比 { r i } i = 1 2 m \lbrace r_i \rbrace^{2m}_{i=1} {ri}i=12m的递减顺序排序。将排序列表前半部分的tokens赋给第一个集群 c 1 c1 c1,将排序列表后半部分的tokens赋给第二个集群 C 2 C2 C2,其中 C 1 C1 C1和 C 2 C2 C2的大小都为 m m m。来自每个簇的tokens的平均值被用来更新簇的质心。与K-means类似,平衡二元聚类以迭代的方式更新聚类质心和每个样本的类别。

`在上述平衡的二进制聚类中,由此产生的两个集群没有共享的标记,即 C 1 ∩ C 2 = ∅ C1∩C2=∅ C1∩C2=∅。非重叠设置的一个主要缺点是,位于排序列表中间部分的tokens在一个集群中有一些相关特征空间的特性,而其他特性在另一个集群中。无论最终将此令牌分配给哪个集群,该令牌与其部分特征空间邻居之间的连接都将被切断。
例如,在注意力计算过程中,排序列表的第m个位置的不能与第1个位置的令牌通信,因为它们被分配到不同的集群。
重叠平衡二进制聚类克服了这个缺点通过分配第一个 m + n m+n m+n个tokens排序列表中第一个集群,即 C ^ 1 = { t j i } i = 1 m + n \hat C1=\lbrace t_{ji} \rbrace_{i=1}^{m+n} C^1={tji}i=1m+n,最后m+n个tokens排序列表第二个集群,即 C ^ 1 = { t j i } i = 1 m − n + 1 \hat C1=\lbrace t_{ji} \rbrace_{i=1}^{m-n+1} C^1={tji}i=1m−n+1。因此,由此产生的两个集群有 2 n 2n 2n个共同的tokens,即 C ^ 1 ∩ C ^ 2 = { t j i } i = m − n + 1 m + n \hat C1∩\hat C2=\lbrace t_{ji}\rbrace^{m+n}_{i=m−n+1} C^1∩C^2={tji}i=m−n+1m+n。默认情况下,我们只在所提出的平衡层次聚类的最后一级采用重叠二进制聚类,而在其他层次上使用非重叠版本。我们在所有实验中设置n个=20进行重叠二值聚类。
Local attention within cluster.
通过上述引入的平衡层次聚类,将标记集合 T T T分组为 2 K 2^K 2K子集 { T i } i = 1 2 k \lbrace \mathcal {T}_i \rbrace^{2^k}_{i=1} {Ti}i=12k,其中 ∣ T i ∣ = N 2 k |\mathcal{T}_i|=\frac {N}{2^{k}} ∣Ti∣=2kN。标准自我注意(SA)在每个子集中执行:
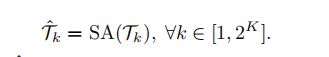
输出, T ^ \hat {\mathcal {T}} T^是所有参与的子集的联合:

根据transformer中的多头结构,设计了feature-space local attention。注意,在多头feature-space local attention中,我们实现的不仅仅是用于在等式中计算自注意作为标准Transformer,也用于执行平衡分层聚类。也就是说,平衡的层次聚类是在每个头部中独立执行的。因此,对于一个特定的tokens,在不同的头部中,它可能会对不同的tokens进行基于特征的局部注意。
Experiments
遵循与其他VIT同行相同的训练策略。我们使用ImageNet-1K的训练分割来训练我们的模型,使用224×224输入分辨率,并且没有外部数据。具体来说,我们训练300个epochs,训练310个cswin epochs,我们使用AdamW优化器与余弦学习速率调度器和一个线性预热过程。