论文阅读笔记 - CBAM: Convolutional Block Attention Module
论文阅读笔记 - CBAM: Convolutional Block Attention Module
- 摘要
- 简介
- 研究现状
-
- 网络设计
- attention 机制
-
- Residual Attention Network
- Squeeze-and-Excitation
- CBAM
-
- channel attention module
- spatial attention module
- 使用方法
- 代码实现
-
- channel attention
- spatial attention
- fusion
- 参考
论文原文 https://arxiv.org/abs/1807.06521
摘要
文章提出卷积块注意力模块,对于前馈神经网络来说,这是一个简单然而有效的注意力模型。给定一个中间层的特征图,CABM可以推断出一个空间维度上和通道维度上的注意力图,将注意力图与原特征图相乘得到改进后的特征图。CBAM是一个轻量的通用的模型,它可以运用到任何CNN里面,和CNN一起端到端地训练,只有一些微不足道的参数支出
简介
为了改进CNN的表现力,研究人员研究网络的3个重要因素:深度,宽度,基数。
从LeNet到ResNet,CNN变得越来越深,表现力也越来越强。VGG说明堆叠相同形状的块会得到不错的结果。和VGG类似,ResNet堆叠残差块来建立一个非常深的结构。GoogleNet说明卷积核的宽度也是提升模型效果的一个重要因素。有人在ResNet上作了实验,发现通过增加卷积核的宽度,28层的ResNet比没有增加宽度的1001层网络还要好(在cifar数据集,图像分类任务中)。有人提出了增加网络的基数,通过经验发现,增加网络的基数可以节省参数,而且相对于增加宽度和深度,增加网络的基数可以带来更好的表现力。
除了这些因素,attention也会影响模型的效果,attention可以告诉我们集中关注那些地方。我们的目标是利用attention机制去提高模型的表现力,关注重要的特征,抑制不重要的特征。文章提出了一种新的模型,Convolutional Block Attention Module,卷积块注意力模型。由于卷积操作是通过混合不同通道上,空间上的信息来提取信息特征,我们的模型在空间和通道维度上加重有用的信息,抑制无用的信息。文章模型的两个分支,channel-wize attention 学习 ‘what’,spatial-wize attention 学习’where‘。通过可视化方法Grad-CAM发现,使用了CBAM的模型可以可好的把关注点集中在目标物体上。我们推测性能的提升来源于更精确的attention和不相关类别之间的噪声的抑制
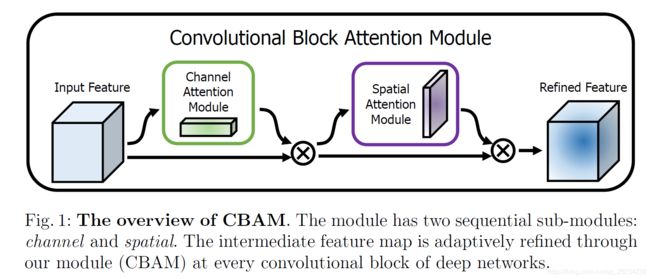
研究现状
网络设计
网络设计是很重要的,网络设计的越好,模型的效果越好。那么怎么去设计网络呢?一个简单的方式就是增加模型的深度,但是简单增加模型的深度会使得模型饱和,这是由于梯度回传造成的。Resnet通过使用残差连接改善了梯度回传问题,网络可以更深了,后面基于resnet又发展了许多模型,这里略过。
attention 机制
前人提出了许多attention 方式,比如
Residual Attention Network
https://arxiv.org/abs/1704.06904
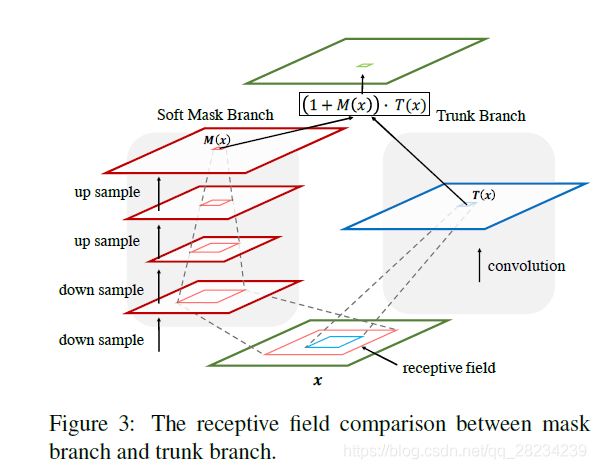
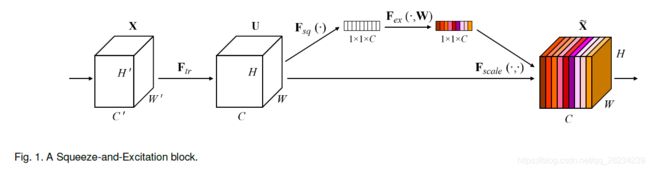
Squeeze-and-Excitation
https://arxiv.org/abs/1709.01507
CBAM
channel attention module
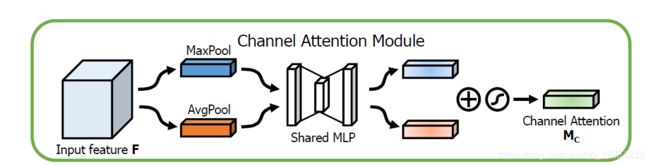
channel attention model 利用channels 之间的联系来寻找哪些channels 是更有意义的。
spatial attention module
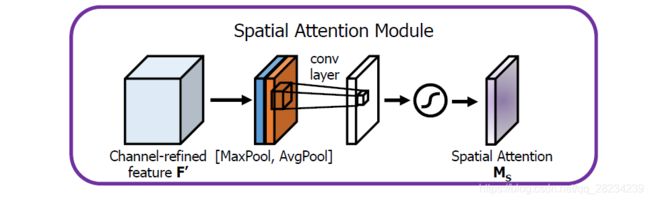
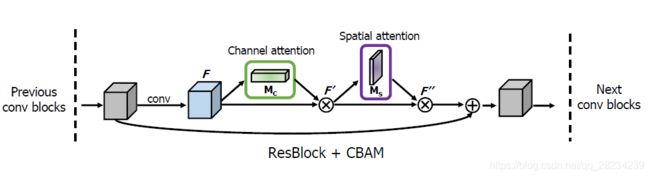
使用方法
夹在两层CNN之间。
代码实现
channel attention
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
spatial attention
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
fusion
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
参考
https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py