1.2.深度卷积生成对抗网络(DCGAN)
第一节是只用了一个隐藏层,这节生成器和鉴定器都将使用卷积神经网络,看看会不会产生不一样的结果。
1.导入训练和训练模型所需的所有包,模块以及库。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import mnist
from keras.layers import Activation, BatchNormalization, Dense, Dropout, Flatten, Reshape
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.models import Sequential
from keras.optimizer_v2 import adam as Adam此节也是使用的mnist数据集,可以直接从keras.datasets中导入mnist数据集。
2.模型维度的输入
img_rows = 28
img_cols = 28
channels = 1
# 输入图像的维度
img_shape = (img_rows, img_cols, channels)
# 噪声向量Z的长度
z_dim = 1003.构造生成器
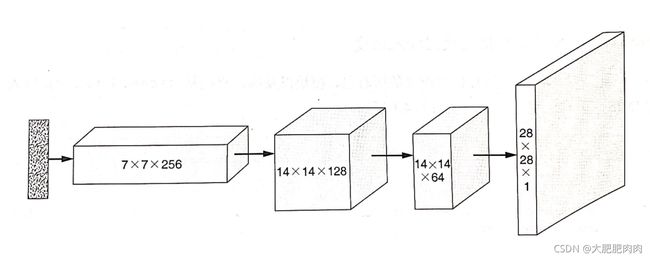
def build_generator(z_dim):
model = Sequential()
# 通过全连接层将输入重新调整大小7*7*256的张量
model.add(Dense(256 * 7 * 7, input_dim=z_dim))
model.add(Reshape((7, 7, 256)))
# 通过转置卷积层将7*7*256的张量转换为14*14*128的张量
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过转置卷积层将14*14*128的张量转换为14*14*64的张量
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过转置卷积层将14*14*64的张量转换为28*28*1的张量
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
# 带有tanh激活函数的的输出层
model.add(Activation('tanh'))
return model此处要注意我们并非获取图像再将其处理为向量,而是获取向量并调整其大小以使其变为图像,所以我们在此处要利用转置卷积
我们在之前遇到的都是使用卷积减小其输入的宽度和高度,同时增加其深度,而转置卷积用于增加宽度和高度,同时减小深度.
在卷积层之间增加批归一化的原因,是为了增加训练的稳定性(归一化是数据的缩放,使它具有零均值和单位方差,最重要的一点使得具有巨大尺度差异的特征之间的比较变得更加容易,进而使训练过程对特征的尺度不那么敏感)
4.构造鉴别器

def build_discriminator(img_shape):
model = Sequential()
# 通过卷积层将大小为28*28*1的张量转变为14*14*32的张量
model.add(Conv2D(32, kernel_size=3,strides=2, input_shape=img_shape,padding='same'))
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过卷积层将大小为14*14*32的张量转变为7*7*64的张量
model.add(
Conv2D(64,
kernel_size=3,
strides=2,
input_shape=img_shape,
padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 通过卷积层将7*7*64的张量转变为3*3*128的张量
model.add(
Conv2D(128,
kernel_size=3,
strides=2,
input_shape=img_shape,
padding='same'))
# 批归一化
model.add(BatchNormalization())
# Leaky ReLU 激活函数
model.add(LeakyReLU(alpha=0.01))
# 带有sigmoid激活函数的输出层
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model5.构建并运行DCGAN
def build_gan(generator, discriminator):
model = Sequential()
# 将生成器和鉴定器结合到一起
model.add(generator)
model.add(discriminator)
return model# 构建并编译鉴定器(使用了二元交叉熵作为损失函数,Adam的优化算法)
discriminator = build_discriminator(img_shape)
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam.Adam(),
metrics=['accuracy'])
# 构建生成器
generator = build_generator(img_shape, z_dim)
# 在生成器训练的时候,将鉴定器的参数固定
discriminator.trainable = False
#构建并编译固定的鉴定器的GAN模型,并训练生成器
gan = build_gan(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam.Adam())除了生成器和鉴定器的网络结构,其他实现和设置和前面那个GAN网络基本相同
6.训练DCGAN
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
# 导入mnist数据集
(X_train, _), (_, _) = mnist.load_data()
# 灰度像素值从[0,255]缩放到[-1, 1]
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
# 真实图像的标签都为1
real = np.ones((batch_size, 1))
# 假图像的标签都为0
fake = np.zeros((batch_size, 1))
for iteration in range(iterations):
# -------------------------
# 训练鉴定器
# -------------------------
# 抽取真实图像的一个批次
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 生成一批次的假图像
z = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(z)
# 训练鉴定器
d_loss_real = discriminator.train_on_batch(imgs, real)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成器
# ---------------------
# 生成一批次的假照片
z = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(z)
# 训练生成器
g_loss = gan.train_on_batch(z, real)
if (iteration + 1) % sample_interval == 0:
# 保存损失和准确率以便训练后绘图
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
# 输出训练过程
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" %
(iteration + 1, d_loss, 100.0 * accuracy, g_loss))
# 输出生成图像的采样
sample_images(generator)7.显示生成图像
def sample_images(generator, image_grid_rows=4, image_grid_columns=4):
# 样本的随机噪声(4*4张的合成图)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, z_dim))
# 从随机噪声中生成图像
gen_imgs = generator.predict(z)
# 将图像像素值重新缩放为[0,1]内
gen_imgs = 0.5 * gen_imgs + 0.5
# 建立图像网格
fig, axs = plt.subplots(image_grid_rows,
image_grid_columns,
figsize=(4, 4),
sharey=True,
sharex=True)
cnt = 0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
# 输出一个图像网格
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 18.运行模型
# 设置超参数
iterations = 20000
batch_size = 128
sample_interval = 1000
# 训练模型直到指定的迭代次数
train(iterations, batch_size, sample_interval)模型输出


