指纹识别中的深度学习技术
在模式识别领域,指纹识别是少有的、依赖传统技术就能够取得很高识别率的子领域。早在20世纪70年代,当时的自动指纹识别技术就已经能帮助警方破案了。可能因为传统技术太成功了,深度学习在指纹识别领域的应用起步较晚。不过随着深度学习的蓬勃发展,研究者逐渐基于深度学习技术实现指纹识别的各个模块,取得了越来越好的性能。本文不打算罗列所有利用深度学习的指纹识别论文,只介绍本人比较熟悉、有代表性的论文。
1、指纹特征提取
指纹的特征可以分为从粗到细的三个级别。第1级:脊线方向场和频率图(奇异点是方向场的特殊点);第2级:脊线骨架图(细节点是脊线的特殊点);第3级:脊线的内外轮廓(汗孔即内轮廓)。近年来研究者提出了多种基于深度学习的指纹特征提取方法。
1.1 方向场估计
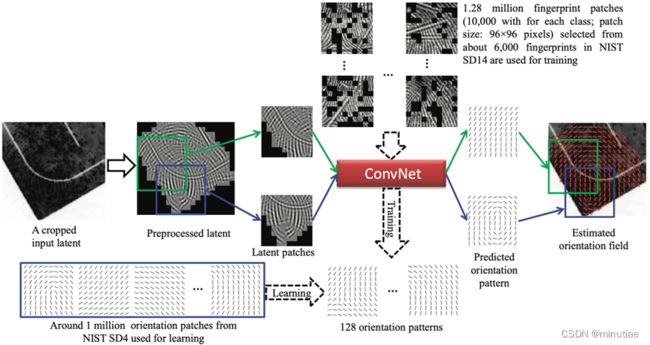
Cao和Jain(2015)将指纹图像块的方向场估计视为分类问题,提出了一种基于卷积神经网络(ConvNet)的现场指纹方向场估计方法。给定从现场图像提取的图像块,它们的方向块由经过训练的ConvNet预测并拼接在一起,以形成整个现场指纹的方向场。
具体来说,首先利用传统算法从NIST SD4数据库中获得块大小为16×16像素的所有方向场。该数据库包含五种指纹类型中每种指纹的约400个滚动指纹。从这些方向场中选择大小为10×10的方向块。然后采用快速K均值聚类方法将这些方向块聚类为128个方向模式(部分见下图)。

从另一个更大的滚动指纹数据库NIST SD14中,选择大量大小为160×160像素的指纹块,通过计算与每个方向模式的方向相似性,将其分配给相应的方向模式。对于每个方向模式,一共收集了1万个指纹块,用于128类ConvNet分类网络的训练(结构如下图)。为了模拟现场指纹,还在这些图像块上叠加线条等噪声,得到更多的训练样本。
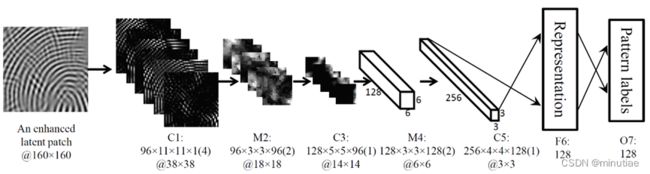
给定现场图像,该方法估计方向场的流程如下(见下图):(1)采用预处理步骤去除大尺度背景噪声,增强脊线结构;(2)将预处理的图像划分为重叠的图像块,并将每个块送到训练好的ConvNet以预测其方向模式;(3)将所有预测方向模式拼接在一起,形成整个方向场。
1.2 姿态估计
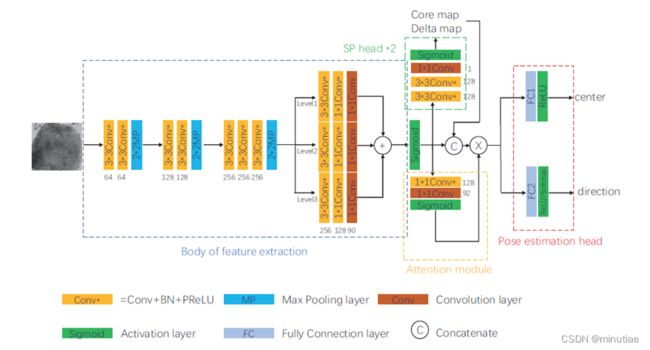
Yin等人(2021)在分析传统的指纹姿态和指纹奇异点提取算法的基础上,设计了一个统一的深度网络进行指纹姿态与奇异点的联合提取,网络结构如下图所示。网络包含四个部分,分别是特征提取骨架、奇异点估计模块、注意力机制模块和姿态回归模块。特征提取模块包含三层卷积模块和一个空洞卷积金字塔,用于提取底层特征。奇异点估计模块分别提取中心奇异点和三角奇异点的概率热力图。注意力机制模块用于在特征层中计算出对姿态估计有意义的区域。姿态回归模块最终通过全连接层对指纹的中心位置和角度进行输出。
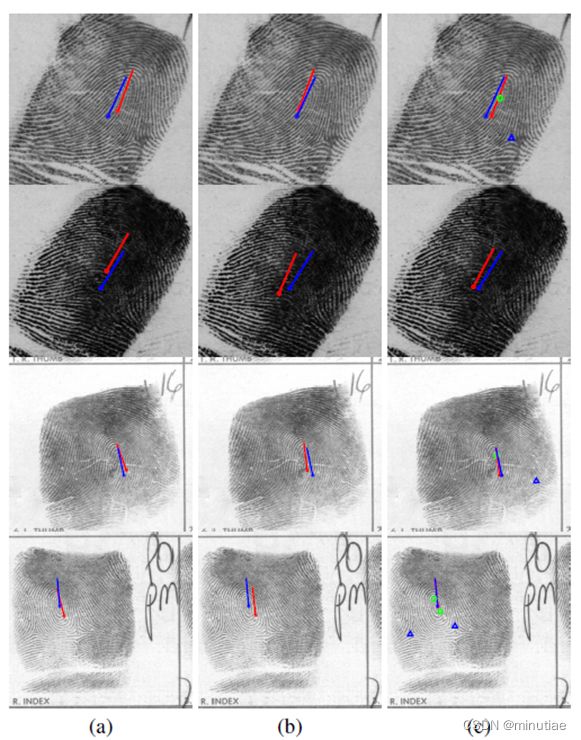
作者使用了NIST SD4的2000个库指纹及其手标奇异点和姿态对网络进行训练。针对现场指纹,则使用了海鑫现场指纹库的200个现场指纹进行再次训练。每个指纹在训练过程中会进行随机的平移和旋转变换进行数据增广。作者在NIST SD4、NIST SD14滚动指纹库、FVC2004 DB1A平面指纹库和NIST SD27现场指纹库上进行了测试,通过比较手标细节点对位置差异和基于姿态的索引结果进行姿态的结果比较。下图的案例表明该方法均优于已有的姿态估计算法,并且能够同时输出中心和三角奇异点的位置。
1.3 脊线和细节点提取
脊线和细节点是密切相关的特征,因此将它们的提取合并讨论。这里具体描述两种方法(Tang等人,2017;Dabouei等人,2018)。
1.3.1 FingerNet
Tang等人(2017)结合指纹领域知识和深度学习的表示能力来设计细节点提取的深度卷积网络。首先将传统的指纹处理流程包括方向估计、分割、增强和细节点提取,转换为具有固定权重的卷积网络(如下图所示)。
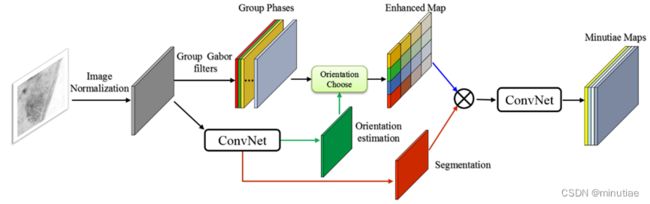
然后扩展为权重可学习的FingerNet网络(下图)以增强其表示能力。FingerNet网络是完全可导的,可以从大量数据中学习网络权重。首先,针对输入指纹图像,采用像素级归一化来固定输入图像的均值和方差。之后的整个网络分为三个部分:方向场估计和分割、增强、以及细节点提取。
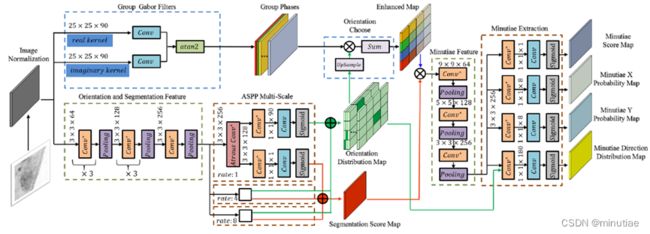
方向场和分割模块的骨干是VGG网络,它由几个卷积-BN-pReLU块和最大池化层组成。在基本特征提取后,采用空洞空间金字塔池化(ASPP)层获取多尺度信息。空洞卷积的比例为 1、4 和 8。随后,对各尺度的特征图进行平行方向回归,直接预测每个输入像素90个离散角度的概率,得到方向分布图。并进行分割图回归,以预测每个输入像素为感兴趣区域的概率,得到分割得分图。
Gabor增强直接作为增强模块。其中,脊线频率取固定值,脊线方向离散化为90个离散角,对应于方向分布图。将相位组乘以上采样的方向分布图,即可获得最终的增强指纹图像。具体来说,Gabor滤波器的参数是可设置的,并在训练过程中进行微调。
增强的指纹图像被发送到细节点提取模块。该模块的主干也是VGG网络,后接ASPP层。特征提取后,细节点提取部分输出四种不同的图以满足网络要求。第一幅图是细节点得分图,它表示每个8×8块包含细节点的概率。第二幅和第三幅图是细节点的X/Y概率图,用于通过8个离散位置分类任务进行精确定位。最后一幅图是细节点方向分布图,它表示细节点方向,类似于方向分布图。
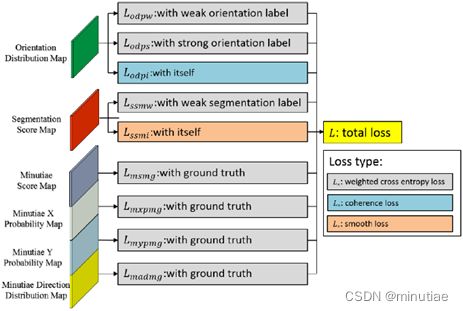
每个输出的损失函数如下图所示。由指纹专家标注的细节点被用作真值。由于方向场和分割图没有真值,因此由细节点和匹配的档案指纹分别生成弱标签和强标签。弱方向标签是传统方法提取的对齐档案指纹的方向场。强方向标签是细节点方向。最后,通过扩张细节点集合的凸包得到现场指纹的弱分割标签。
作者在NIST SD27和FVC2004数据库上进行了实验。在NIST SD27上,提取的细节点和真值之间的位置和角度平均误差分别为4.4像素和5.0°。在FVC2004上,位置和角度的平均误差分别为3.4像素和6.4°。下图显示了一个示例,其中包含FingerNet提取的方向场,增强的前景区域和细节点。

此外,作者还进行了识别实验,以测试指纹匹配是否可以受益于FingerNet。结果表明,由于细节点提取得更好,FingerNet的识别率优于其他方法。例如,和VeriFinger细节点提取方法相比,FingerNet的rank-1识别率高出约19%。
1.3.2 条件生成对抗网络
Dabouei等人(2018)提出了一种基于条件生成对抗网络(cGAN)的直接现场指纹重建模型。作者对cGAN进行了两种修改,以使其适应现场指纹重建的任务。首先,强制模型在脊线图上生成三个附加图,以确保在生成过程中考虑方向和频率信息,并防止模型填充大面积缺失区域并产生虚假细节点。其次,开发了一种感知ID保留方法,强制生成器在重构过程中保留ID信息。作者使用合成的现场指纹数据库,训练深度网络预测输入现场图像的缺失信息。
该模型由三个网络组成:生成器、指纹感知ID信息(PIDI)提取器和鉴别器(见下图)。该生成器是一个U-net网络,它获取输入的现场指纹并同时生成脊线、频率图、方向图和分割图。重建误差是生成的各图与其各自真值误差的加权和。在此之后,生成的图与输入的现场指纹连接,为鉴别器提供条件。真值图是从原始的干净指纹中提取的,这些指纹首先被扭曲以模拟现场图像。在训练阶段,这些图用于为鉴别器提供监督。
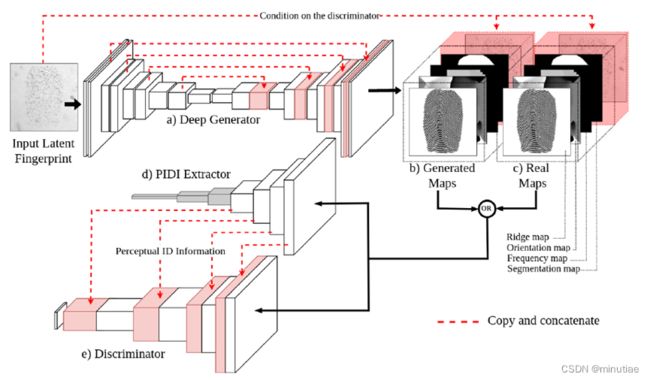
指纹PIDI提取器是来自深度孪生指纹验证器的一支,该验证器使用对比损失进行训练。它被训练为指纹验证器,以提取生成图的感知ID信息(PIDI)。提取的PIDI是验证器模块前四个卷积层的输出特征图,并连接到判别器的相应层,以强调判别器决策上的ID信息。
鉴别器是一个深度CNN,它将大小为256×256×5的生成器的条件输出映射到大小为16×16×1的判别矩阵。相应的现场指纹连接到生成的或真值图以充当条件。指纹验证器获得的PIDI也会传递给鉴别器。
作者在IIIT-Delhi MOLF数据库上进行了实验。现场与活体指纹匹配的rank-50准确度为70.89%,现场与现场指纹匹配的rank-10准确度为88.02%。此外,使用NFIQ测量重建指纹的质量表明,与原始现场图像相比,生成指纹的质量明显升高。
1.4 汗孔检测
2、指纹匹配
2.1 细节点描述子
细节点描述子是细节点匹配的非常重要的组成部分。过去,细节点描述子通常是根据经验设计的。其中,精心设计的描述子(如MCC)在活体指纹和油墨指纹的匹配方面表现相当不错。然而,在现场指纹匹配中,由于缺乏细节点和自动提取细节点的可靠性低,这些描述子的性能会大大降低。Cao和Jain (2019)建议使用ConvNet进行细节点描述子的提取。
该细节点描述子是从不同比例和位置的14个图像块中学习的(如下图所示)。对于从同一细节点提取的每个图像块,训练一个ConvNet以获得特征向量,最后将14个 ConvNet输出的14个特征向量中的一个子集连接成一个细节点描述子。

训练细节点图像是从密歇根州警方指纹数据库中提取的。该数据库包含1311人的十指指纹,每个手指至少有10个滚动指纹。每个不同细节点都被视为一个类,并且仅保留具有8个以上样本的类。在这种情况下,每个ConvNet都被训练为多类分类器。在测试时,每个卷积网的最后一个全连接层的输出被视为输入图像块的特征向量。
2.2 指纹定长表示
将指纹表示为像人脸、虹膜那样的定长向量,是非常吸引人的想法。但是这条路很难走。自FingerCode(Jain等人,2000)以来,这个方向一直没有大的进展。受益于良好的深度网络设计和大规模训练数据,Engelsma等人(2021)提出的DeepPrint将指纹定长表示的研究向前推进了一大步。
DeepPrint有三个主要模块。第一个是对齐模块,采用空间转换网络将指纹对齐到同一坐标系中。然后将对齐的指纹图像送到基本网络,其输出再送到两个分支。第一个分支直接用于特征提取和损失计算,该纹理特征与脊线方向和频率高度相关。第二个分支是自定义网络,捕捉细节点特征。有两个损失函数,一个是细节点的重建损失,另一个是分类损失。作者使用2.1节提到的密歇根州警方指纹数据库进行网络训练。
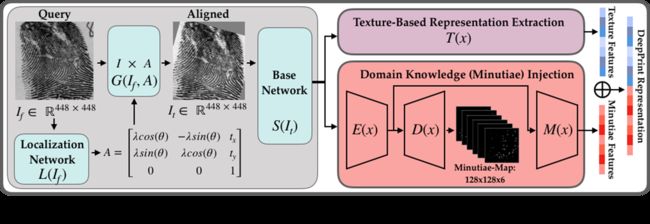
纹理表示和细节点表示的特征长度均为96。因此,最终指纹表示是这两个表示的串联,一个192维的特征向量。 在串联之前,将这两种表示形式归一化为单位长度以消除范数的影响。 对于匹配,使用余弦距离来计算两个指纹表示之间的相似性。下图的两个例子,左指纹对是一对匹配指纹,但被细节点匹配算法错误拒绝了。右指纹对是一对不匹配指纹,但被细节点匹配算法错误接受了。DeepPrint给出的匹配分数能正确辨别这两个例子,表明DeepPrint对湿指纹和皮肤变形比较鲁棒,并且能够学习到有鉴别力的特征。

2.3 指纹配准
2.4 指纹稠密配准
稠密指纹配准方法的精度受到指纹自相似性、噪声和扭曲的挑战。基于图像相关的稠密配准方法使用图像相关系数,容易受到这些挑战的影响;基于相位解调的稠密配准方法容易受到指纹扭曲变形和噪声的影响,其中相位解包裹方法也受到误差累积的限制。
Cui等人(2021)首次将深度学习运用于指纹稠密配准,通过训练端到端网络,从指纹对中直接估计变形场。算法分为基于细节点的初始配准和基于网络的精配准两步。输入指纹首先根据匹配的细节点计算出空域变形进行粗配准,然后通过网络得到稠密的变形场进行精配准。
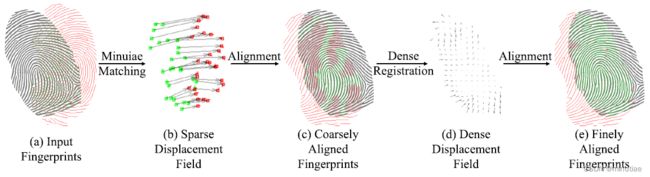
该网络结构参考光流估计网络,由两个并行的特征提取网络和一个编码-解码网络构成。网络是端到端训练的,输入两个粗配准的指纹,输出对应的变形场。为了生成网络的训练数据,作者利用清华扭曲指纹视频,通过视频追踪的方式得到扭曲变形场,再将变形场应用于现场指纹和低质量指纹,这样得到了大量指纹对作为训练数据。
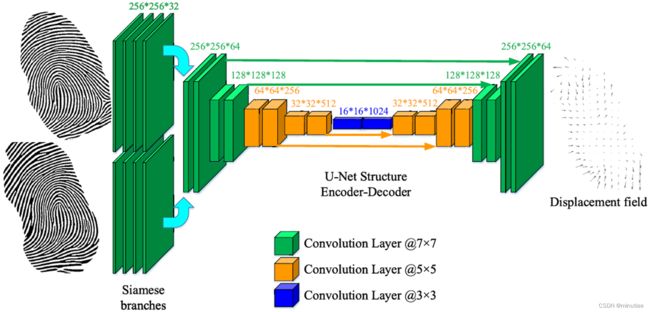
通过在FVC2004、清华扭曲指纹库(TDF)、现场指纹库NIST-27上的配准和匹配实验表明,该稠密配准算法在配准误差和匹配误差上都优于之前的方法。由于利用了GPU的并行计算能力,该算法速度远快于之前的串行指纹配准算法。
2.5 指纹扭曲自校正
皮肤扭曲是指纹匹配中长期存在的挑战,它会导致错误的不匹配。以往的研究表明,通过对扭曲指纹进行估计扭曲场,然后将其校正为正常指纹,可以提高识别率。
Guan等人(2022)认为,之前的扭曲自校正方法(Si等人,2015;Gu等人,2018)基于扭曲场的主成分表示,有限的主成分模板只能粗略估计变形模式,这并不准确,而且对手指姿态非常敏感,难以有效处理多角度、复杂扭曲的指纹。作者提出了一种利用基于自参考信息的深度学习网络,直接估计失真指纹的稠密扭曲场,并加以修正。该方案使用了端到端的深度学习网络,不要求指纹姿态的绝对正确,因此对多姿态指纹鲁棒,另一方面,使用了稠密估计而非现有的基于主成分分析的低维表示,对扭曲的表达能力更强,估计的扭曲细节上更准确。网络通过多尺度空洞卷积和包含上下文信息的通道注意力模块加强网络对邻域信息的参考能力,并优化了变形场真值的表述方式,以确保真值去除刚性变换分量,只保留弹性扭曲部分。
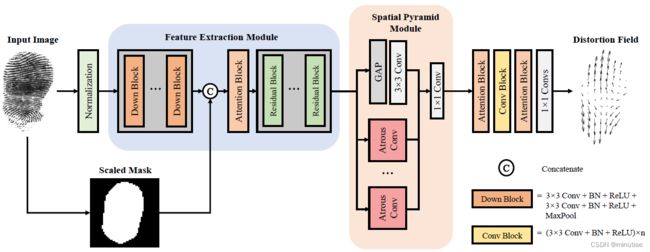
作者收集了480个指纹扭曲视频,包括许多不同姿势和不同扭曲类型的指纹。在该数据库和公开扭曲指纹数据库TDF上进行了实验,以测量变形估计精度、匹配性能、模型复杂度和推理效率。实验结果表明该方法优于已有的基于主成分分析的指纹扭曲矫正算法。
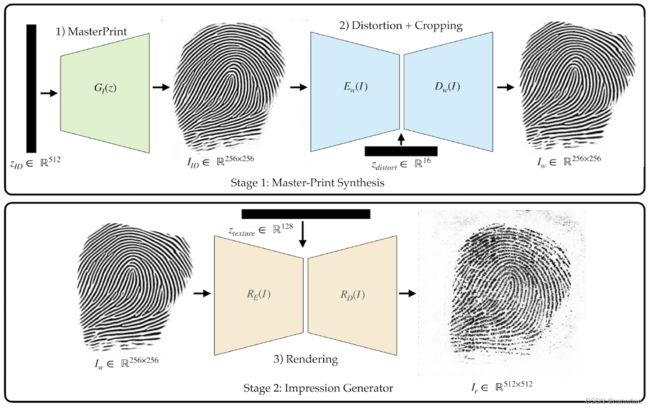
3、指纹合成
参考文献
- Cao, K., & Jain, A. K. (2015). Latent orientation field estimation via convolutional neural network. In 2015 International Conference on Biometrics (ICB) (pp. 349-356). IEEE.
- Cao, K., & Jain, A. K. (2019). Automated latent fingerprint recognition. IEEE transactions on pattern analysis and machine intelligence, 41(4), 788-800.
- Dabouei, A., Kazemi, H., Iranmanesh, S. M., Dawson, J., & Nasrabadi, N. M. (2018). ID preserving generative adversarial network for partial latent fingerprint reconstruction. In 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS) (pp. 1-10). IEEE.
- Engelsma, J. J., Cao, K., & Jain, A. K. (2021). Learning a fixed-length fingerprint representation. IEEE transactions on pattern analysis and machine intelligence, 43(6), 1981-1997.
- Engelsma, J. J., Grosz, S. A., & Jain, A. K. (2023). PrintsGAN: synthetic fingerprint generator. IEEE transactions on pattern analysis and machine intelligence.
- Feng, J., & Jain, A. K. (2011). Fingerprint reconstruction: from minutiae to phase. IEEE transactions on pattern analysis and machine intelligence, 33(2), 209-223.
- Gu, S., Feng, J., Lu, J., & Zhou, J. (2018). Efficient rectification of distorted fingerprints. IEEE Transactions on Information Forensics and Security, 13(1), 156-169.
- Guan, X., Duan, Y., Feng, J., & Zhou, J. (2022). Direct Regression of Distortion Field from a Single Fingerprint Image. In 2022 IEEE International Joint Conference on Biometrics (IJCB).
- Jain, A. K., Prabhakar, S., Hong, L., & Pankanti, S. (2000). Filterbank-based fingerprint matching. IEEE transactions on Image Processing, 9(5), 846-859.
- Si, X., Feng, J., Zhou, J., & Luo, Y. (2015). Detection and rectification of distorted fingerprints. IEEE transactions on pattern analysis and machine intelligence, 37(3), 555-568.
- Tang, Y., Gao, F., Feng, J., & Liu, Y. (2017). FingerNet: An unified deep network for fingerprint minutiae extraction. In 2017 IEEE International Joint Conference on Biometrics (IJCB) (pp. 108-116). IEEE.
- Yin, Q., Feng, J., Lu, J., & Zhou, J. (2021). Joint estimation of pose and singular points of fingerprints. IEEE Transactions on Information Forensics and Security, 16, 1467-1479.