【Redis】Redis集群架构剖析(1):认识cluster
本文档主要是学习redis cluster的一下学习笔记和想法,通过这篇文章,希望你能了解redis的cluster是如何构建的,以及里面的数据结构是怎么样的。当然,也值得去思考redis的集群架构设计思路,这个其实对自己的分布式系统架构设计是由帮助的。
总所周知,Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。那么:
- 如何启动一个集群节点呢?
- 又如何创建一个集群呢?
- 创建好的集群,通过什么记录集群信息,又记录哪些信息呢?
- 一个新的节点又是如何加入一个集群的呢?
节点启动
一个集群由多个节点组成,为了形成一个集群,那这个节点启动的配置一定不一般。
通常我们启动redis,不考虑集群的话,正常都是直接用默认配置,用docker或者直接二进制起。但是要注意的是,如果想要将该节点加入某个集群,那么配置文件中的cluster-enabled必须设置为true,否则无法加入任意一个集群。启动时的内部逻辑大致如下:
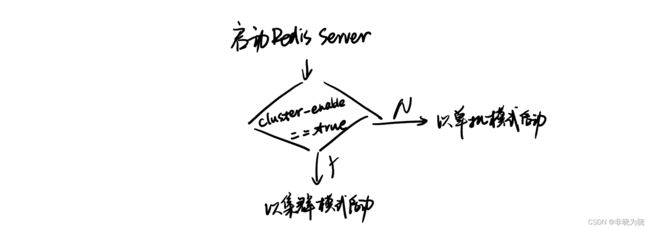
创建集群
从上一节我们得知一个Redis集群由多个节点(node)组成。一开始的时候,每个节点都是独立的,都处于一个只包含自己的集群当中。那么为了建立一个集群,那就需要把他们都连接起来。
连接节点的指令,可以通过CLUSTER MEET指令:
CLUSTER MEET <ip> <port>
向一个节点node发送CLUSTER MEET指令,目的是为了让node和指定的IP/PORT node握手。当握手成功时,node 节点就会把对应的节点加到当前所在集群中。
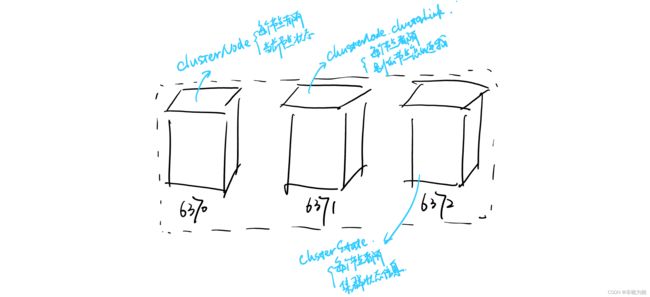
下图用3个redis节点作为例子,端口分别是6370、6371和6372,均在同一台服务器上部署(为了测试)

注意,这是一个节点一个节点添加到集群内的,也可以通过redis-cli create cluster指令来创建集群,可以参考另一篇redis的集群搭建,会详细介绍:
Redis集群docker部署
集群数据结构
了解了集群节点的启动和创建,那集群的信息是怎么存的呢?
在集群模式下会用到的数据,节点会将它们存在cluster.h/clusterNode结构、cluster.h/clusterLink结构,以及cluster.h/clusterState结构里面。
clusterNode
集群中的我是谁,我有什么证明
clusterNode结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP地址和端口号等等。
每个节点都会使用一个clusterNode结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态。
struct clusterNode{
// 创建节点的时间
mstime_t ctime;
// 节点的名字,由40个十六进制字符组成
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识
// 使用各种不同的标识值记录节点的角色(比如主节点或者从节点,或者上线下线)
int flags;
// 节点当前的配置纪元,用于实现故障转移
uint64_ configEpoch;
// 节点的IP地址
char ip[REDIS_IP_STR_LEN];
// 节点的端口
int port;
// 保存连接节点的有关信息
clusterLink *link;
//...
}
clusterLink
如果集群有一个节点想要访问我,怎么可以快速访问到我
clusterNode结构的link属性是一个clusterLink结构,该结构保存了连接节点所需的有关信息,比如套接字描述符,输入缓冲区和输出缓冲区:
typedef struct clusterLink{
// 连接的创建时间
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 输出缓冲区,保存着等待发送给其他节点的消息(message)
sds snduf;
// 输入缓冲区,保存着从其他节点收到的消息
sds rcvbuf;
// 与这个连接相关联的节点,如果没有的话就为NULL
struct clusterNode *node;
} clusterLink
redisClient结构中的套接字和缓冲区用于连接客户端的,而clusterLink结构中的是连接节点的
clusterState
集群里面还有谁,我要记住你们
同时每个节点都会保存一个clusterState结构,这个结构记录了当前节点的视角下,集群目前所处的状态,好比说集群现在有多少个节点,当前是下线还是上线:
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself;
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前状态:是在线还是下线
int state;
// 集群中至少处理着一个槽的节点的数量
int size
// 集群节点名单(包括mysql节点)
// 字典的键为节点的名字,字典的值为节点对应的cluserNode结构
dict *nodes;
// ...
} clusterState;
redis的集群数据结构其实是可以在自己的分布式架构借鉴的,当前节点信息,别人怎么联系我,当前集群拓扑,这三个数据结构里面存的东西就可以表示一个集群当前的节点状态信息。
节点加入集群
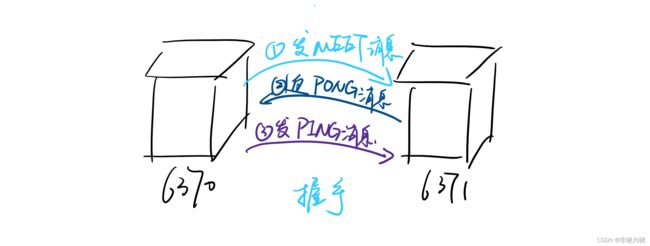
我们在第二节讲了用CLUSTER MEET这个指令来创建集群,在了解了集群数据结构之后,再来详细地剖析下,这个指令到底做了什么,上一节讲的数据结构又会填入哪些值,握手又是如何完成的。
假设现在6370节点对6371节点发起CLUSTER MEET指令:
- 6370会创建一个
clusterNode,并将这个clusterNode加到clusterState - 6370根据
CLUSTER MEET的IP和PORT,向6371节点发送一个MEET消息 - 6371如果收到
MEET消息,就会创建一个6370节点的clusterNode,并加到自己的clusterState里面 - 然后6371会向6370发送一个
PONG - 6370收到
PONG后,就认为6731收到MEET消息 - 之后6370会再向6371发送
PING - 6371收到6370的
PING之后,认为6370收到自己的PONG,此时握手完成 - 6370会将6371的节点信息通过Goosip协议传播给集群的其他节点,让其他节点也去和6371握手。过一段时间之后,集群的其他节点就都会认识6371
集群建好了
在前几节的步骤之下,集群已经创建好了。然后我们通过6370的视角,看一下现在的集群,根据第三节的数据结构,可以看到集群数据结构存的内容如下:
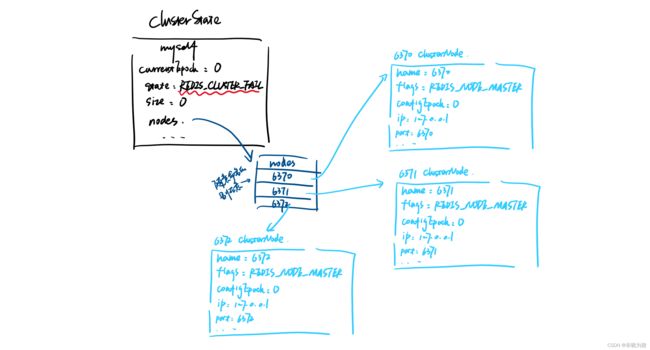
nodes里面是kv,key是node的名称(正常不是这样的),value就是对应的节点的clusterNode。如果是别的节点视角,那对应的就是myself节点改一下。
注意到的是clusterState数据结构里面的一个字段state,还是REDIS_CLUSTER_FAIL。这意味着,我们现在创建好了集群,但是这个集群状态不可用。为什么不可用呢?我们知道的是redis是一个kv数据库,要存的东西的,那谁存什么值我们似乎还没有分配好,这个会不会是集群不可用的原因呢?请待下回分解。
系列文章:
- 【Redis】Redis集群架构剖析(2):槽位
- 【Redis】Redis集群架构剖析(3):集群处理redis-cli指令
- 【Redis】Redis集群架构剖析(4):槽位迁移,重新分配
- 【Redis】Redis集群架构剖析(5):复制与故障转移