pytorch的基本语法
一、数据类型
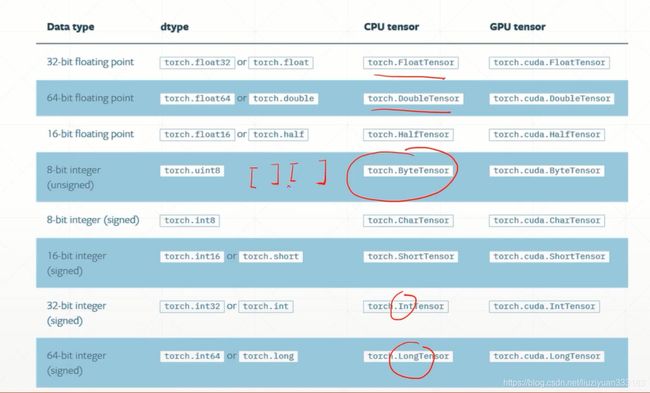
1、基本数据类型
| python | pytorch |
|---|---|
| int | IntTensor |
| float | FloatTensor |
| Int array | IntTensor … |
| String | – |
pytorch 没有内键支持string类型
2、判断数据类型
isinstance(a,torch.FloatTensor) —— 判断a的数据类型是不是torch.FloatTensor
type(a) —— 查看a的数据类型
data = data.cuda() —— 将变量放在cuda上,在查看数据类型会发生变化
3、标量
a = torch.tensor(1.) —— 维度为0的标量
a.shape —— 输出: torch.Size([])
len(a.shape) —— 输出0
a.size() —— 成员函数
4、张量
b = torch.tensor([1.1,2.2])
b = torch.FloatTensor(1) —— 长度为1
b = torch.FloatTensor(2) —— 长度为2
b = torch.from_numpy(data) —— data为numpy
注意1: dim指的是行和列;size/shape指的是b的形状;tensor指的是b
b.shape —— 返回形状; b.numel() —— 返回所有维度相乘的值; b.dim() —— 返回维度
5、tensor创建
未初始化创建
a = torch.tensor([2.,3.2])
a = torch.Tensor(此处输入的是shape),a = torch.Tensor(2,3)
a = torch.FloatTensor(此处输入的也是shape)
pytorch 默认是torch.FloatTensor
torch.set_default_tensor_type(torch.DoubleTensor) —— 把默认类型变成torch.DoubleTensor
二、初始化
rand —— 随机分布
随机初始化:torch.rand(3,3) —— 随机生成3行3列【0,1】之间的数字
torch.rand_like(a) —— 输入一个tensor,随机生成和a的size相似的tensor
torch.randint(1,10,[3,3]) —— 1是最小值,10是最大值,[3,3]是输入的size
randn —— 正态分布
torch.randn(3,3) —— 生成N(0,1)的正态分布
指定分布
torch.normal(mean = torch.full([10],0), std=torch.arrage(1,0,-0.1)) —— 生成维度为1,长度为10
torch.full([2,3],7) —— 生成全部为7的2行3列
torch.full([],7) —— 生成维度为0的标量,tensor(7.)
torch.full([1],7) —— 生成维度为1的tensor,tensor([7.])
torch.full([2],7) —— [7.,7.]
生成等差数列
torch.arrange(0,10] —— tensor([0,1,2,3,4,5,6,7,8,9])
torch.arrage(0,10,2) —— tensor([0,2,4,6,8]),2表示的是阶梯值
生成等分数列(这里的steps表示的是数量值)
torch.linspace(0,10,steps=4) —— tensor([0.0000,3.3333,6.6667,10.0000])
torch.linspace(0,10,steps=10) —— tensor([0.0000,1.1111,2.2222,3.3333,4.4444,5.5556,6.6667,7.7778,8.8889,10.0000])
生成ones/zeros/eye(对角)
torch.ones(3,3) —— 给的是shape
torch.zeros(3,3) —— 给的是shape,输出的是矩阵
torch.eye(3,4) —— 生成对角元素是1.,其它元素为0.的对角矩阵
torch.eye(3) —— 表示生成3*3的对角矩阵
随机打散
idx = torch.randperm(2)
idx —— 打散一次
a[idx] —— 将打散后的坐标赋给a这个tensor
三、索引与切片
a[:,:,:]与python一样的规则
a[ 0: 28:2] 每隔2个进行采样
a.index_select(1,[0,2]) —— 第一个参数表示在第几个维度上,第二个参数表示取几个数
四、维度变化
view/reshape
这两个函数在目前的版本完全通用
a = torch.rand(4,1,28,28)
a.view(4,28*28)
squeeze/unsqueeze
unsqueeze
a.shape —— torch.Size([4,1,28,28])
a.unsqueeze(0).shape —— torch.Size([1,4,1,28,28]),输入在哪个维度之前增加
a.unsqueeze(-1).shape —— torch.Size([4,1,28,28,1])
a.unsqueeze(4).shape —— torch.Size([4,1,28,28,1])
squeeze
b.shape —— torch.Size([1,32,1,1])
不给参数的话,会把维度为1的全挤压掉
b.squeeze().shape —— torch.Size([32])
b.squeeze(0).shape —— torch.Size([32,1,1])
expand/repeat(维度扩展)
expand:broadcasting
要求原来的维度和要扩展维度的维度是一样的
a = torch.rand(4,32,14,14)
b.shape —— torch.Size([1,32,1,1] )
b.expand(4,32,14,14).shape —— torch.Size([4,32,14,14])
b.expand(4,33,14,14) —— 会报错
repeat:memory copied
b.shape —— torch.Size([1,32,1,1])
b.repeat(4,32,1,1).shape —— torch.Size([4,1024,1,1]) ,repeat输入的数字表示要拷贝的次数
transpos/permute
a = torch.randn(3,4)
a.t() —— torch.Size(4,3) 只能用于2D操作
a.shape —— [4,3,32,32]
a.transpose(1,3).shape —— torch.Size([4,28,28,3])
b = torch.rand(4,3,28,32)
b.transpose(1,3).shape —— torch.Size([4,32,28,3])
b.permute(0,2,3,1).shape —— torch.Size([4,28,32,3])
五、自动扩展
broadcast
六、拼接与拆分
cat
a = torch.rand(4, 32, 8)
b = torch.rand(5, 32, 8)
torch.cat([a,b], dim = 0).shape —— torch.Size([9,32,8]) ,dim=0表示在第0个维度进行拼接,dim=1表示在第一个维度进行拼接
stack
a1=torch.rand(4,3,16,32)
a2=torch.rand(4,3,16,32)
torch.cat([a1,a2], dim=2).shape —— torch.Size([4,3,32,32])
如果是用stack如下:
torch.stack([a1,a2], dim=2).shape —— torch.Size([4,3,2,16,32])
split
按长度拆分,长度一样给固定值,长度不一样给一个list
c:[3,32,8]
a,b = c.split([2,1],dim=0)
a:[2,32,8] b:[1,32,8]
chunk
按数量拆分
c:[2,32,8]
a,b = c.chunk(2,dim=0)—— a:[1,32,8] b:[1,32,8]
七、基本运算
add/minus/multiply/divide
torch.add(a,b)
torch.sub(a,b)
matmul
torch.matmul(a,b) —— 表示a,b按矩阵的方式相乘
a*b —— 表示a和b相对应的元素相乘
多维使用matmul,仅对最后两维进行操作
pow
pow(a,3) 表示a的三次方
sqrt/rsqrt
aa.sqrt() 表示aa开平方
aa2 表示aa的平方
aa0.5 表示aa的开根号
round
a = torch.tensor(3.14)
a.round() 表示四舍五入
clamp
裁剪
grad.clamp(10) —— 把10裁掉
grad.clamp(0,10) ——保留0到10之间的值
八、统计方法
norm
a.norm(1)
a.norm(2)
mean sum
如果想要在指定维度得到最大最小值,需要给定维度
prod
max,min,argmin,argmax
argmin,argmax 返回的是最大值最小值的索引
a.argmax(dim=1) 表示在第一个维度返回最大值的索引号
kthvalue,topk
a.topk(2,dim=1,largest = True) 得到概率最大的前2个数,largest = False表示得到最小值,不设置表示得到最大值
a.kthvalue(8,dim=1) 表示得到第8个小的值,注意只能设置为最小值
九、保存模型
加载模型
net.load_state_dict(torch.load(‘ckpt.mdl’))
保存模型
torch.save(net.state_dict(),‘ckpt.mdl’)
十、定义Flatten类
为什么要定义Flatten类?
因为F.relu()是函数,不能放在nn.Sequential()里,nn.Sequential()只能放类,所以自己封装一个Flatten类,同理Reshape也需要自己封装
class Flatten(nn.Module):
def __init__(self):
super(Flatten,self).__init__()
def forward(self,input):
return input.view(input.size(0),-1)
十一、将参数加到模型里去
这样的话当调用nn.parameter()就可以得到所有的参数
就可以自动的被SGD优化
class MyLinear(nn.Module):
def __init__(self, inp,outp):
super(MyLinear,self).__init__()
# requires_grad = True,默认就会设置为true
self.w = nn.Parameter(torch.randn(outp,inp))
self.b = nn.Parameter(torch.randn(outp))
def forward(self,x):
x = x @ self.w.t() + self.b
return x