【CV】yolov3 RuntimeError: CUDA error: device-side assert triggered
YOLOv3训练自己数据集时报错
在使用YOLOv3(github地址:https://github.com/eriklindernoren/PyTorch-YOLOv3)训练自己的数据集时遇到了
RuntimeError: CUDA error: device-side assert triggered
的报错,在网上找了好久,大部分遇到的错误是类别数量不匹配导致的CUDA error或者有遇到相同错误的并没有给出具体的解答。
/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
Traceback (most recent call last):
File "train.py", line 105, in <module>
loss, outputs = model(imgs, targets)
File "/lib/python3.7/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/PyTorch-YOLOv3/models.py", line 260, in forward
x, layer_loss = module[0](x, targets, img_dim)
File "lib/python3.7/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/PyTorch-YOLOv3/models.py", line 188, in forward
ignore_thres=self.ignore_thres,
File "/PyTorch-YOLOv3/utils/utils.py", line 301, in build_targets
obj_mask[b, best_n, gj, gi] = 1
RuntimeError: CUDA error: device-side assert triggered
(dengjie) smartcity@smartcity-X780-G30:/media/smartcity/E6AA1145AA1113A1/dengjie/paper/PyTorch-YOLOv3$
从以上报错来看,关键信息是
Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
......
File "/PyTorch-YOLOv3/utils/utils.py", line 301, in build_targets
obj_mask[b, best_n, gj, gi] = 1
RuntimeError: CUDA error: device-side assert triggered
说明是有数据超出了边界值,并且最终报错的位置是出在utils.py 文件里的build_targets 函数中。
YOLOv3标注格式
训练自己的数据集只需获取训练集的图片位置信息以及每张图片的标注信息,json文件实际上是用不到的。具体格式如下:
图片位置信息: label txt文件
label txt文件
txt中包含的信息:
16 0.328250 0.769577 0.463156 0.242207
1 0.128828 0.375258 0.249063 0.733333
0 0.476187 0.289613 0.028781 0.138099
0 0.521430 0.258251 0.021172 0.060869
0 0.569492 0.285235 0.024547 0.122254
0 0.746734 0.295869 0.049469 0.098357
0 0.444961 0.298779 0.023953 0.110047
0 0.450773 0.271209 0.018266 0.056925
第一列为类别标签,其他四列分别为归一化后的中心点坐标和宽高信息。
解决方法
以上报错的问题是出在标注的数据上。在翻阅YOLOv3原作者github issue时发现很多人都遇到了同样的问题,在其中一条issue下终于找到了解决方法,链接如下:
https://github.com/eriklindernoren/PyTorch-YOLOv3/issues/157
解决方法:
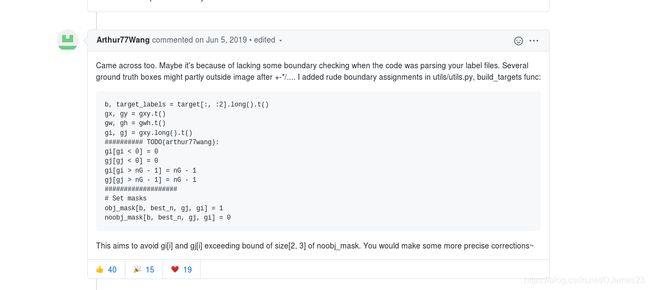
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t()
#print('gj,gi', gj,gi)
# add by github issue,fix the error of RuntimeError: CUDA error: device-side assert triggered,gt box may cross the boundry
# /pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:60: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0],
# thread: [9,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
gi[gi<0] = 0
gj[gj<0] = 0
gi[gi > nG - 1] = nG - 1
gj[gj > nG - 1] = nG - 1
# Set masks
obj_mask[b, best_n, gj, gi] = 1
noobj_mask[b, best_n, gj, gi] = 0
# Set noobj mask to zero where iou exceeds ignore threshold
for i, anchor_ious in enumerate(ious.t()):
#print('11111',i)
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
加上以上几行代码后就可以运行了(不容易。。。)
另外,可以参考另一份yolov3的代码,作者修改了一些bug:
https://github.com/ujsyehao/yolov3-multigpu
另一个报错
但是。。。我又遇到了另一个错误!
Total loss 16.112184524536133
---- ETA 0:17:35.771242
Traceback (most recent call last):
File "train.py", line 101, in <module>
for batch_i, (_, imgs, targets) in enumerate(dataloader):
File "/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 838, in _next_data
return self._process_data(data)
File "/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data
data.reraise()
File "/lib/python3.7/site-packages/torch/_utils.py", line 394, in reraise
raise self.exc_type(msg)
ValueError: Caught ValueError in DataLoader worker process 3.
Original Traceback (most recent call last):
File "/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/PyTorch-YOLOv3/utils/datasets.py", line 109, in __getitem__
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
ValueError: cannot reshape array of size 53 into shape (5)
关键信息如下:
ValueError: Caught ValueError in DataLoader worker process 3.
ValueError: cannot reshape array of size 53 into shape (5)
第一条报错是迭代DataLoader时出现的,应该多线程进程出错了。第二条报错推测是某个label txt文件中格式乱掉了,将所有写成了一整行才会有这个错误。但这里并没有给出具体是哪个文件出错了,我们也不能一条一条的检查。
解决方法
1.首先将train文件中的num_workers改为0
dataset = ListDataset(train_path, augment=True, multiscale=opt.multiscale_training)
# num_workers=opt.n_cpu,
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=0, #opt.n_cpu,
pin_memory=True,
collate_fn=dataset.collate_fn,
)
optimizer = torch.optim.Adam(model.parameters())
并在datasets.py文件中的ListDataset打印读取的txt文件信息,包括文件名和对应的尺寸:
label_path = self.label_files[index % len(self.img_files)].rstrip().rstrip('\n')
# print(label_path)
targets = None
if os.path.exists(label_path):
print(label_path,np.loadtxt(label_path).shape)
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
print(boxes.shape)
# Extract coordinates for unpadded + unscaled image
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
此时的报错信息如下:
/media/smartcity/E6AA1145AA1113A1/dengjie/datasets/crowdhuman/labels/train_all/Image/273275,f73d8000feba4a38.txt (53,)
Traceback (most recent call last):
File "train.py", line 102, in <module>
for batch_i, (_, imgs, targets) in enumerate(dataloader):
File "/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 385, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/PyTorch-YOLOv3/utils/datasets.py", line 109, in __getitem__
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
ValueError: cannot reshape array of size 53 into shape (5)
可以看到log已经将出现错误的txt文件打印出来了,是273275,f73d8000feba4a38.txt (53,)
2.查看该文件,发现果然出错了

这里没有分行导致尺寸不对无法reshape,再去检查生成txt文件的python代码发现有个判断索引值写错了,将其纠正生成正确格式的标注信息,就可以正常开始训练了。
折腾了两天才解决。另外github issue是个好地方,大家遇到问题可以多去找找,加油(ง •̀_•́)ง