【 卷积神经网络CNN 数学原理分析与源码详解 深度学习 Pytorch笔记 B站刘二大人(9/10)】
卷积神经网络CNN 数学原理分析与源码详解 深度学习 Pytorch笔记 B站刘二大人(9/10)
本章主要进行卷积神经网络的相关数学原理和pytorch的对应模块进行推导分析
代码也是通过demo实现各个不同的模块如卷积环节和池化环节,通过输出模块前后的数据参数和中间变量对比数据变化,理解卷积神经网络的底层运算过程
具体的实战例子在下一章进行实现,复现经典的深度学习模型GoogleNet,并以minist数据集实现手写数字的识别
请走传送门:
【卷积神经网络CNN 实战案例 GoogleNet 实现手写数字识别 源码详解 深度学习 Pytorch笔记 B站刘二大人(9.5/10)】
数学原理分析
在定义中,卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一
爱中卷积层作用是保存降维前图像的空间信息,下采样减少数据量,降低运算需求
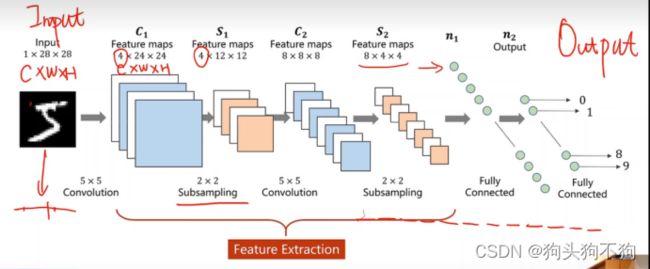
一般来说卷积神经网络大部分用于多层矩阵,大部分应用于图像处理领域
成像原理:RGB图层,图像采集器原理,光子收集器连接光敏电阻,光敏电阻值作为阵列,组成像素点。
相关知识点不在赘述,请自行了解CV(computer version)的相关知识
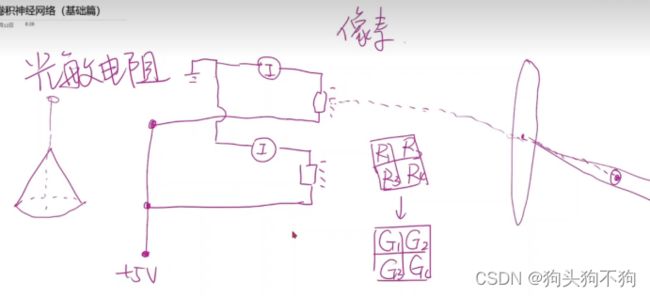
额外知识 缩略图和矢量图的不同
矢量图概念是通过:存储圆心,直径,边界,填充,因此不受像素值影响可同比放大,随放大的倍数重新进行绘制

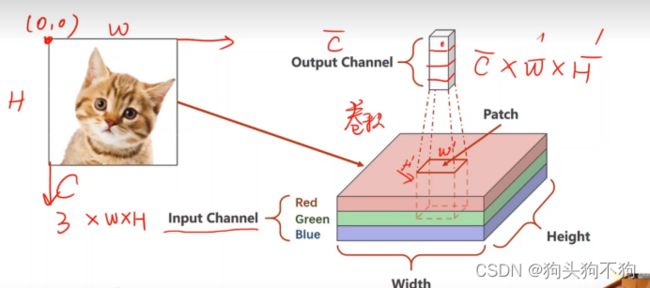
卷积过程
卷积的过程也可以对应在机器视觉中的掩模处理概念,即都是生成一个大小为(2n+1)×(2n+1){n =0 ,1, 2,,,,}大小的掩模矩阵,作为滑块从大小为图像(N × M)的边角处进行整体遍历,从而生成全新的(N-n)×(M-n)大小的图像
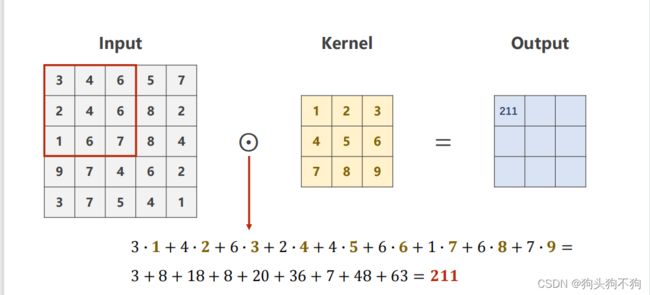
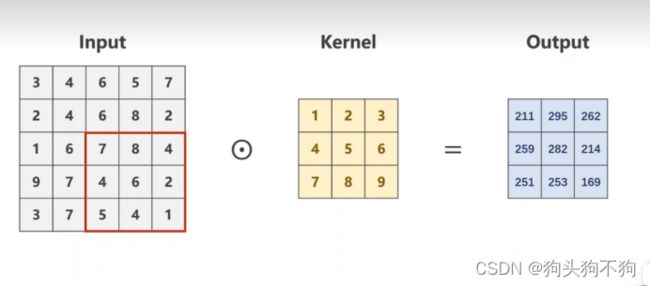
之所以像素边界会减小,是因为在进行滑块掩模运算时,掩模中各个元素与对应图像元素进行运算,将计算值赋值给对应全新像素点,这就意味边界的点无法进行正常的掩模卷积运算,如图
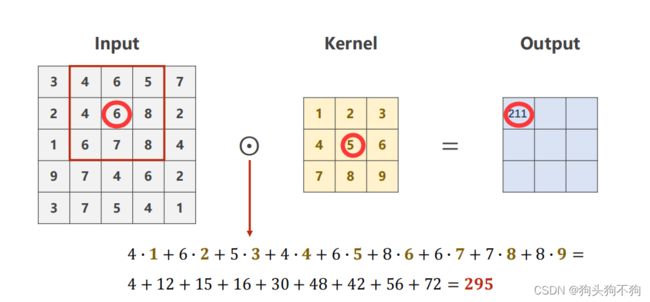
output的值受9+9个元素共同影响,该图只是表示运算的对关系,第n行的元素将对应新图像的第一行元素,更便于理解
多通道卷积过程:
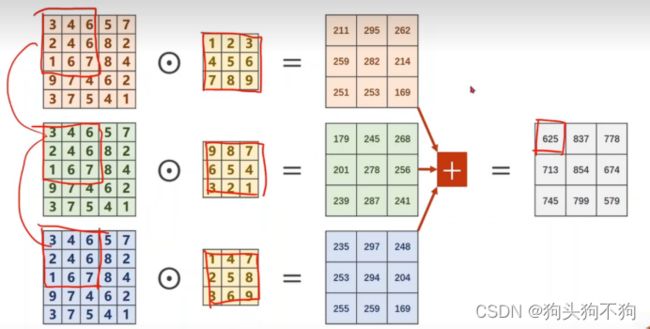
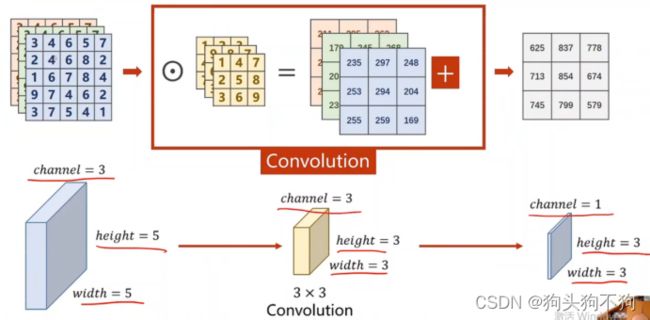
当输出为一维向量时,卷积核的通道数与输入数据的通道数是一样的
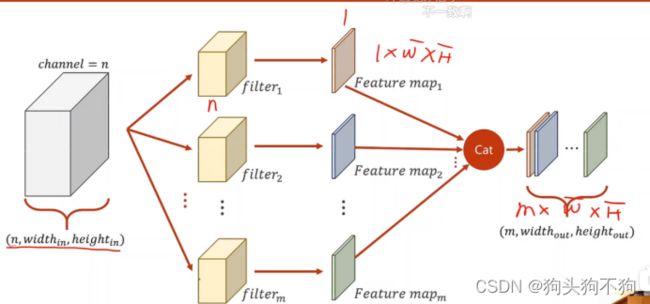
则当输入通道为n,输出通道为m时,可以确定卷积核的通道为m×n,至此在定义和构造的卷积核的时候可以构建4维张量 m×n×width×height

注意在tensor数据类型中的四个参数分别是(batch_size, channel,data_width, data_height),且调用的dim对应(0,1,2,3),在进行神经网络节点构造时一定要保证第1,第3,第4,即dim=0,2,3的参数必须相同
代码解读与实现
padding 边界填充
边界扩充:
padding = 1
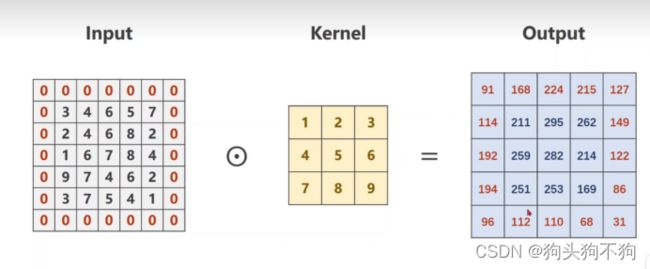
边界扩充的主要的意义在于使得输入图像和输出图像的size相同,因为在前文解读中已经分析过为什么输出图像会缺少n层边界,进行外部填充后可以保证输入输出图像的大小相同,这一点在部分节点中具有重要意义。
代码实现:

stride 步幅增加
stride = 2
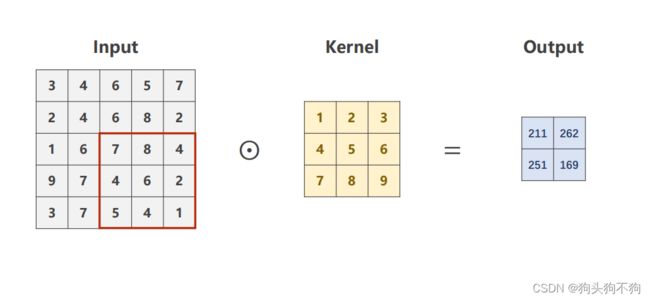
通过不步幅增加,即以2个元素为间隔进行卷积操作,此时导致输出矩阵为(N-2n)×(M-2n)
代码实现:

maxpooling 最大池化层
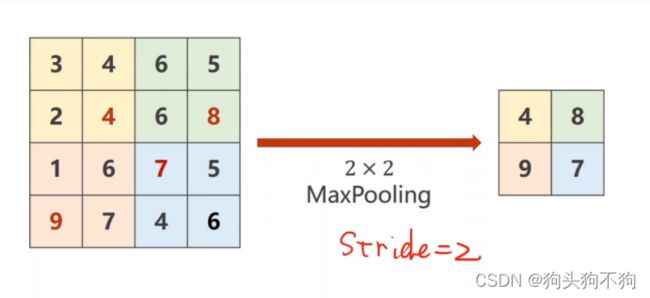
stride = 2,将图像分割为多个2×2的小区域,然后将其中的最大值作为输出的元素值,实现将输出图像的size减半,[width,height] -> [0.5×width,0.5×height]
代码结构构造
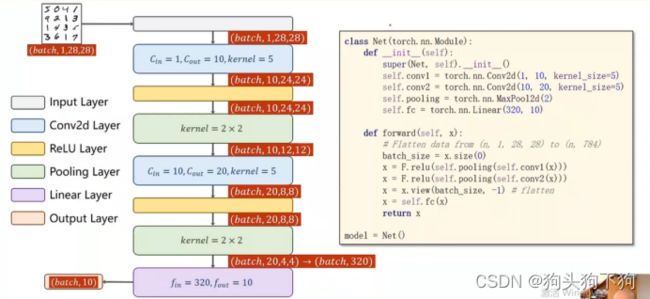
注意,途中的顺序和代码有出入,在结构图中先relu在池化,但是在实际代码中是先池化在relu,但是效果不变,view操作编程将输入转化为全连接网络的输入,由于使用交叉熵损失,最后一层不做激活
GPU如何显卡运算,迁移gpu运行:
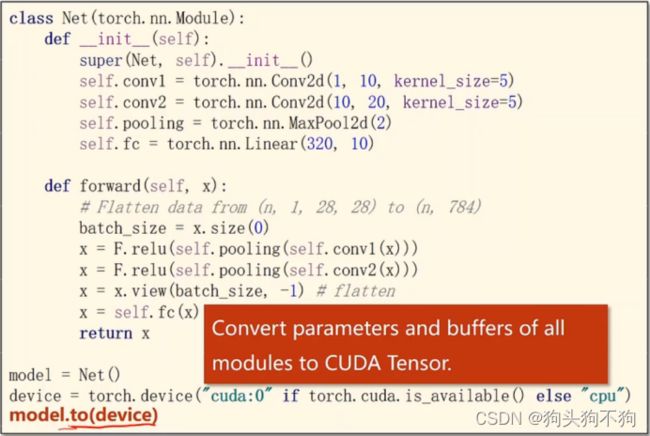
1.模型的gpu迁移,设计device,运用.to 运算都转换为cuda 的tensor类型
-
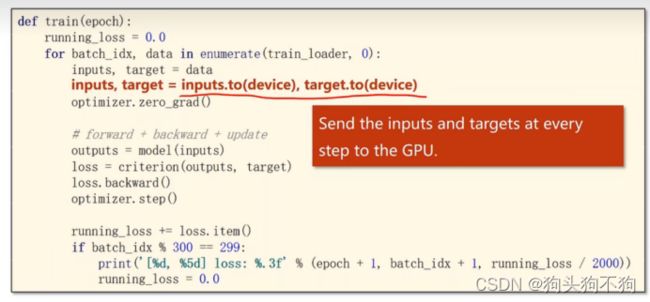
训练数据的GPU迁移,同样使用to运算
注意迁移inputs和target要和模型迁移的显卡是同一块显卡,同一device

-
测试数据的GPU迁移,与之前的操作相同
整体代码注释与实现
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 09日
通过torch模块实现CNN,basic代码主要用于理解torch中CNN各个模块的内参以及传输关系
"""
import torch
# ----------------------------观察参数和输入输出变化 -------------------------
in_channels, out_channels = 5, 10 #设置参数
width, height = 100, 100
kernel_size = 3
batch_size = 1
# CNN中的input类型包含四个参数
# 参数1表示单次训练的batch数,参数2表示输出的通道数,3,4表示图像的宽和高度
input =torch.randn(batch_size,
in_channels,
width,
height)
# 计算层设置 设置输入输出的通道数 和 掩模size
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
# 输出运算中输出的shape从而了解运算中的参数和size变换
print("input shape:", input.shape)
print("output shape:", output.shape)
print("conv_layer wight:", conv_layer.weight.shape)
# input shape: torch.Size([1, 5, 100, 100])
# output shape: torch.Size([1, 10, 98, 98])
# conv_layer wight: torch.Size([10, 5, 3, 3])
# ------------------------------------------------------------------------------------
# --------------- 为保证输出输出的图像size大小的相同,再Conv2d中设置了边界填充参数---------------
input = [3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1]
input = torch.Tensor(input).view(1, 1, 5, 5) # 通过tensor进行数据转换,转换为b=1,c=1,w=5, h=5 的矩阵
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False) # 设置边界填充为1,在3*3的掩模下保证了图像size不变
kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3) # 自己设计相关掩模
conv_layer.weight.data = kernel.data # 替换模块默认掩模
output = conv_layer(input)
print("output2 shape", output.shape)
print("output2:", output)
# ------------------------------------------------------------------------------------
# --------------- 为保证输出输出的图像size大小的相同,再Conv2d中设置了掩模运行间距---------------
input = [3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False) # 设置运行间距为2,输出的矩阵size-1
kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print("output3 shape", output.shape)
print("output3:", output)
# -----------------------------池化层------------------------------------
input = [3, 4, 6, 5,
2, 4, 6, 8,
1, 6, 7, 8,
9, 7, 4, 6,]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling_layer(input)
print("output4 shape", output.shape)
print("output", output)