transformers - huggingface中 bertseqclassification使用
学习目标:huggingface bert的使用
学习内容:
- data precessor等类的搭建 (预处理文本数据)
- pretrain模型的调用
- 模型的搭建(与pytorch结合使用)
- 训练过程
DataProcessor类
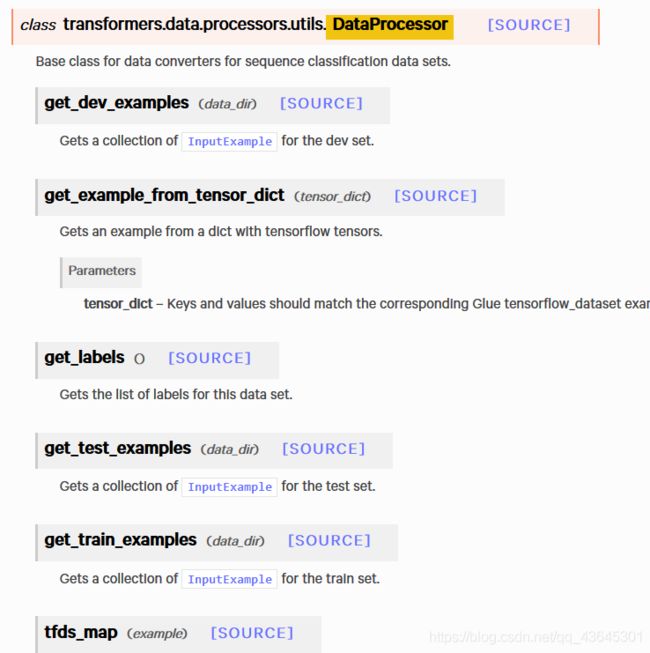 其中get_labels和几个get_examples需要注意,可能需要自己改写
其中get_labels和几个get_examples需要注意,可能需要自己改写
InputExample类
guid是唯一标识符 可以定义成下面这种形式
guid = f'{set_type}-{i}-{j}'#这里的f是python的字符串格式
label a 和label b是文本对,可用于问答文本匹配,labelb可选

InputFeatures类
由example转变过来,可以调用glue_convert_examples_to_features函数完成这一转化

glue_convert_examples_to_features
 输入example的列表
输入example的列表
返回feature类的列表
- 返回的fetatures列表长这样

from transformers import (
DataProcessor,
InputExample,
BertConfig,
BertTokenizer,
BertForSequenceClassification,
glue_convert_examples_to_features,
)
import torch.nn as nn
import torch
本次使用的bert模型是BertForSequenceClassification,其余的bert模型尚待探索
Dataprocessor代码示例
class Processor(DataProcessor):
def __init__(self):
super(DataProcessor,self).__init__()
"""实体链接数据处理"""
def get_train_examples(self, inputexample):
return self._create_examples(
lines,
labels,
set_type='train',
)
def get_test_examples(self, inputexample):
return self._create_examples(
lines,
labels,
set_type='test',
)
def get_labels(self):
return [0, 1]
def _create_examples(self, lines, labels,set_type):# 将
document_examples=[]
for i, document in enumerate(lines):
sentence_examples = []
for j,sentence in enumerate(document):
guid = f'{set_type}-{i}-{j}'
text_a = sentence
label = labels[i][j]
sentence_examples.append(InputExample(
guid=guid,
text_a=text_a,
label=label,
))
document_examples.append(sentence_examples)
return document_examples
def _create_features(self,document_examples):
features = []
for document_example in document_examples:
examples = document_example
document_features = glue_convert_examples_to_features(
examples,
tokenizer,
max_length=30,
label_list=get_labels(),
output_mode= 'classification'
)
features.append(document_features)
return features
def creat_train_dataloader(self,train_features):
dataloader =[]
for document_features in train_features:
input_ids = torch.LongTensor([f.input_ids for f in document_features])
attention_mask = torch.LongTensor([f.attention_mask for f in document_features])
token_type_ids = torch.LongTensor([f.token_type_ids for f in document_features])
labels = torch.LongTensor([f.label for f in document_features])
batch = [input_ids,attention_mask,token_type_ids,labels]
dataloader.append(batch)
return dataloader
def generate_dataloader(self,data):
train_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[0],data[1],'train'))))
valid_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[2],data[3],'valid'))))
test_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[4],data[5],'test'))))
return train_dataloader,valid_dataloader,test_dataloader
模型搭建
- 初始化模型和tokenizer
示例:
Bertmodel = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
‘bert-base-uncased’是最基础的预训练模型
- 与pytorch的网络相结合
class Bert_Model_Class(nn.Module):
def __init__(self):
super(Bert_Model_Class,self).__init__()
self.bert = Bertmodel
#self.config = BertConfig.from_json_file(PRETRAINED_PATH + 'bert_config.json')
bert的参数会自动传入pytorch的网络中去
*模型的前向传播
这里需要用到之前的features
feature.input_ids:可以获得input_ids
feature.attention_mask :可以获得attention_mask
feature.token_type_ids:可以获得token_type_ids
feature.label:可以获得label
需要注意是 glue_convert_examples_to_features 返回包含许多feature的一个列表,应该这样操作
[f.label for f in features]
[f.input_ids for f in features]
- 前向传播
def forward(self,input_ids,attention_masks,token_ids):
logits = self.bert(
input_ids=input_ids,
attention_mask=attention_masks,
token_type_ids=token_ids,
)[0]
return logits
再将得到的参数输入到bert模型中,得到结果,剩余的训练过程与pytorch的普通模型无差异。