计算机视觉大型攻略 —— CUDA(2)执行模型
Professional CUDA C Programming[1]是一本不错的入门书籍,虽说命名为"Professional",但实际上非常适合入门阅读。他几乎涵盖了所有理论部分和编程技巧,更重要的是每一章都有完整的实例程序。只不过对于入门来讲,这本书有点太厚了,行文有些啰嗦。准备写几篇文章提取一下关键章节的关键部分。
上一篇写了如何写一个简单的CUDA程序。为了进一步优化程序性能,我们经常会调整Block数量和Thread数量,不断的寻找最优的组合。这一篇探讨的是最优组合背后的故事,为什么有些组合可以达到更好的性能。理解CUDA的执行模型,有助于进一步并行化线程,提高程序性能。
这一篇算是对[1]中第三章CUDA Execution Model的总结。
参考文献:
[1] PROFESSIONAL CUDA C Programming. John Cheng, Max Grossman, Ty McKercher.
[2] CUDA C PROGRAMMING GUIDE
执行模型(Execution Model)通常指的是某种计算架构中如何执行指令。理解执行模型有助于进一步优化CUDA程序。该模型与GPU硬件架构息息相关。
GPU架构
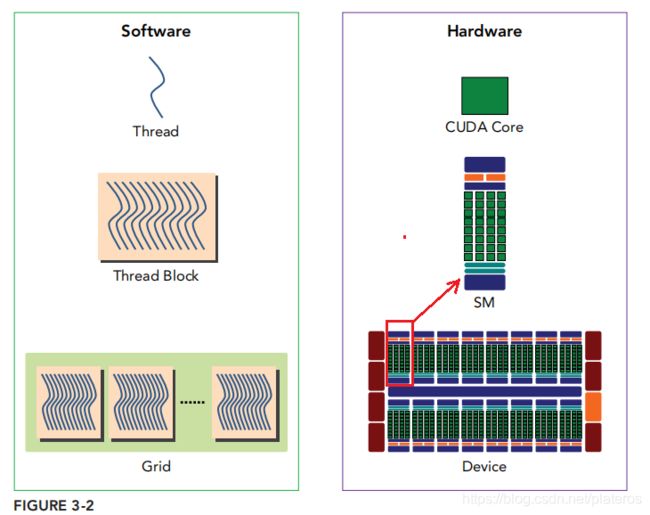
上图引自[1]第三章。左边是软件视角中的程序,右边是硬件视角中的程序。从软件角度来说,上图从下往上看,一个Kernel函数(即一个Grid)有许多Thread Block组成,一个Thread Block又有许多线程组成。从硬件的角度来说,Kernel函数在GPU上执行,GPU由一组SM(streaming multiprocessor,多核流处理区)组成,一个完整的Block分配给一个SM,Block中的thread,由SM中的CUDA core执行。SM可以看成一个独立的作战单元,通常来讲高效的GPU拥有更多数量的SM,同时每个SM的架构均相同。
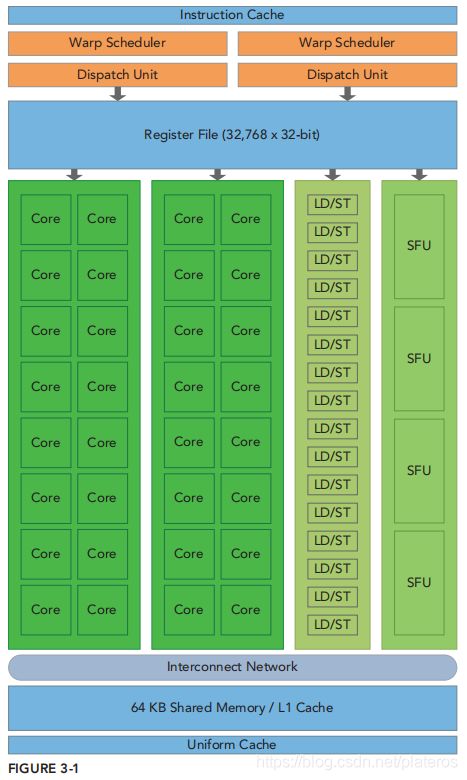
Streaming Multiprocessor
一个SM的基本组成部分
- CUDA core
- 共享内存(Shared Memory)和L1 Cache
- 寄存器
- Load/Save Units
- Special Function Units
- Warp Scheduler
下图是Fermi架构上的SM的图示,虽然与当下主流架构Pascal,Volta相比有不少区别,但是基本组成部分大体一致。
CUDA执行模型
Block分配
Kernel线程被我们分成了线程block,线程以block为单位分配给了不同的SM执行。通常一个SM上会分配多个block,一个block内的所有线程只能在该SM上执行。
下面这个动画为是cuda runtime 对Block分配的一个示意。

- cuda runtime维护Kernel函数的block等待队列。
- 当SM上有空闲资源时,就会分配一个新的Block。
- Block一旦被分配给了某个SM,就会在那里一直驻留,直到执行完毕。
Block分配给SM后,SM为其分配资源,这些Block称为active block。SM资源越多,能够分配到的Block越多。同一时刻SM的Block数主要受到如下几个资源的限制,
- SM的共享内存
- SM的寄存器
- SM支持的最大线程数
- SM支持的最大Block数
- 。。。等
举例说明这几个资源对SM中block数的影响。假设GPU为Kepler架构,那么每个SM有如下资源,
- 支持最大的线程数为2048(64 warps)。
- 一个block最大线程数为1024(32 warps)。
- 32位寄存器 64K个。
- 共享内存:48KB。
设计一个Kernel,
如果每个线程使用32个寄存器,一个block使用24KB共享内存。那么一个SM上可以分配2个block,即2048个线程(64个warp)。此时SM上所有线程均得到使用。Occupancy = 64/64 =100%
如果每个线程使用64个寄存器,一个block用了48KB的内存,那么就只能分配1个block,即1024个线程。此时SM上实际使用的线程就只有一半了。 Occupancy = 32/64 = 50%
Occupancy的定义和由来会在Warp调度部分给出。
Warp调度

线程block分配给SM后,SM将该block内的所有线程进一步划分为Warp, 每个Warp含32个线程。CUDA采用SIMT(Single Instruction multiple Thread,单指令多线程)的架构, Warp为最小调度单元,一个warp内所有线程同一时刻执行相同的指令。

上图是Fermi架构下的SM的执行过程。SM有两个warp调度器和两个指令分配单元。两个warp调度器分别从两个warp中执行一个指令,分别交给16个CUDA core执行。
Active block内的Warp称为active warps. 他们可以进一步分为三种,
- Selected warp
- Stalled warp
- Eligible warp
SM上的Warp调度器每个时钟周期都会调度warp执行,这些执行态的warp被称作selected warp。等待调度的warp称为eligible warp。有些warp由于种种原因不能被调度(如所需资源尚未准备好),称为Stalled warp。
Stalled warp通常是,
- 等待读取Device内存指令(比如对Global 内存的访问需要400-800时钟周期)
- 等待运算指令(约10-20时钟周期)
当执行中的warp进入Stalled态(调用了访存/运算指令),warp调度器会立刻选取eligible warp替代他们,等这些Stalled态的warp完成了这些指令后,他们再一次进入Eligible状态,等待调度。此时我们隐藏了这些需要额外耗时的指令带来的延(Latency Hiding)。
虽然这会导致warp频繁切换,但并不会存在传统CPU进行线程上下文切换所产生的性能问题,这是因为active block上所有warp的资源都是已经分配好了的。
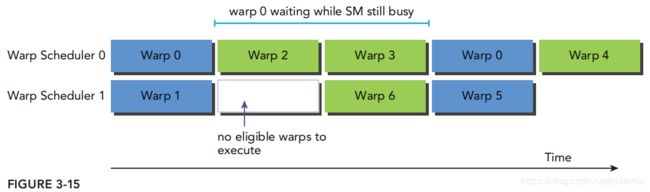
如上图,warp调度器0,Warp0在执行过程中进入了Stalled状态(比如正在访问设备全局内存),调度器会立刻调度Warp2, warp3。因此Warp2, Warp3隐藏了Warp0的指令延迟。
再来看warp调度器1的情况。Warp1进入Stalled状态,而此时并没有eligible warp,因此只能空等。这就降低了程序性能。
因此active block越多(意味着warp越多),SM上的计算资源就利用得越充分。[1]采用Little/s Law来衡量SM上所需的Warp数。在实际应用中,我们只要尽量保证warp足够多就好了。
我们使用occupancy来衡量一个SM的计算资源的使用情况。
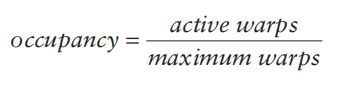
Active block内的warp称作active warps。maximum warps是一个SM支持的最大warp数。回忆Block分配末尾给出的例子,第一种情况的Occupany为100%,第二种情况为50%。
Warp分配原则
一个block被分为32个线程为一组的许多warp,如何知道哪些线程属于哪个warp?
CUDA按照"自然"的数字顺序划分Warp。
block里的线程在逻辑上可以配置为最多3维的空间(threadIdx.x, threadIdx.y, threadIdx.z)。对于一维划分来说,自然而然的就可以按照threadIdx.x的值来组织warp。即按照threadIdx.x的顺序,每32个组成一个warp。而对于二维或三维,只需先将二维或三维的索引,转成一维,再按顺序组织成Warp。
warp0: threadID 0, threadID 1, threadID 2 , ... , threadID 31
warp1: threadID 32, threadID 33, threadID 34 , ... , threadID 63
warp2: threadID 64, threadID 65, threadID 66 , ... , threadID 95
...
二维划分下,
threadID = threadIdx.y*blockDim.x + threadIdx.x
三维划分下
threadID = threadIdx.z*blockDim.y*blockDim.x + threadIdx.y*blockDim.x + threadIdx.x每个Block的warp数,

一个Warp内的线程只能是同一个Block的线程。如果Block内的线程数不是Warp Size(32)的整数倍,那么最后一个warp中会分配额外的线程补齐。

上图举了一个例子。假设一个Block有80个线程,SM会分配3个warp,这意味着硬件实际分配了96个线程,而只有80个线程是有效的。这样造成了硬件资源的浪费。因此,通常都需要将Block内的线程设计为WarpSize(32)的整数倍。
Warp Divergence
再来看一个Warp内的情况。与传统的SIMD不同,Nvidia SIMT架构允许一个Warp中的线程拥有独立的执行路径,这就导致了Warp内线程分叉的情况(Warp divergence),即Warp中的线程,由于控制变量的不同,走向了不同的分支。
if(cond)
{
.... //thread 0
}
else
{
.... //thread 1
}这种不同的代码分支会影响到程序的执行效率。这是因为在一个warp中,每个线程的执行的指令是一致的,GPU不会同时执行if和else内的语句,只能将其if和else按顺序都执行一遍,只不过不满足条件的线程被标记为inactive。上面的例子,Warp内的所有线程执行if分支时,thread 1的状态会被标记为inactive,执行else分支时,thread 0被标记为inactive,程序的执行时间=if分支+else分支。很明显引入了额外的程序执行时间。

如上图,Warp Divergence产生的stall execution浪费了硬件资源。[1]中给出了简单的例子simpleDivergence.cu。对比了几种具体实现的性能。
__global__ void mathKernel1(float *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if (tid % 2 == 0) {
a = 100.0f;
} else {
b = 200.0f;
}
c[tid] = a + b;
}
__global__ void mathKernel2(void) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if ((tid / warpSize) % 2 == 0) {
a = 100.0f;
} else {
b = 200.0f;
}
c[tid] = a + b;
}上面的代码将线程分为两类,执行不同的分支。
mathKernel1,按照线程号tid分类。这就导致了一个Warp内,奇数ID和偶数ID进入了不同分支,导致了Warp Divergence。
mathKernel2,按照Warp ID分类(tid/warpSize)。这保证了同一个Warp内所有线程使用同一分支。
另外,在一些简单的代码段中(如上面这个代码),我们不需要特别担心warp divergence,这是因为CUDA编译器使用了分支预测指令来优化程序分支。不过这些优化仅仅对简单代码有效(指令数小于一个阈值),对复杂的代码还是要使用nvprof检查一下。
线程同步
SIMT保证了Warp内线程的绝对同步,然而不同Warp的线程之间的执行顺序是任意的。CUDA提供了同一Block内,不同线程之间同步的能力。我们可以使用__syncthreads()函数同步同一Block内的线程。这个函数会阻塞,直到Block内的所有线程都执行到了这里。
Block内的函数还可以使用共享内存和寄存器来共享数据。下一篇会写共享内存的使用。
Nvidia没有提供不同Block线程之间的同步机制。因此,同步这些线程需要进行全局同步,即Kernel执行完后,调用cudaDeviceSynchronize()函数同步。
[1]中最后以求和的例子给出了针对更具体的优化手段。等写完内存模型后再单独总结一下。