多智能体强化学习入门QMIX
多智能体强化学习入门QMIX
引言
Qmix是多智能体强化学习中比较经典的算法之一,在VDN的基础上做了一些改进,与VDN相比,在各个agent之间有着较大差异的环境中,表现的更好。
1. IQL与VDN
IQL(Independent Q_Learning),是一种比较暴力的解决问题的方法,每个agent都各自为政,自己学习自己的,没有一个共同的目标。导致算法最终很难收敛。但是在实际一些问题中有不错的表现。
VDN(Value-Decomposition Networks For CooperativeMulti-Agent Learning),每个agent都有自己的动作价值函数 Q a Q_a Qa,通过各自的价值函数的 a r g m a x Q a argmaxQ_a argmaxQa,选取动作。 Q t o t = ∑ i = 1 n Q i Q_{tot}=\sum_{i=1}^nQ_i Qtot=∑i=1nQi,主要将系统的联合 Q t o t Q_{tot} Qtot近似成为多个单智能体的 Q a Q_a Qa函数的和。因为VDN的联合函数的求和形式表现力有限,在有复杂组合的环境中,表现的很差。例如非线性环境。
2. Qmix
2.1 Qmix的算法思想
QMIX的主要目的:找到一个完全去中心化的策略,并没有像VDN一样完全分解,为了保持策略一致性,我们只需要是全局的 Q t o t Q_{tot} Qtot的执行与 a r g m a x Q a argmaxQa argmaxQa上的执行的结果相同:

图1. 去中心化思想
要达到这个效果只需要满足 Q t o t Q_{tot} Qtot对于任何一个 Q a Q_a Qa都是单调递增的:

图2. 保持单调性
不难看出,当 ∂ Q t o t ∂ Q a = 1 \frac {\partial Q_{tot}}{\partial Q_a}=1 ∂Qa∂Qtot=1的时候就是VDN,VDN是QMIX的一种特殊情况。
2.2 Qmix的网络结构
QMIX的模型由两大部分组成(三个网络组成),一个是agent network,输出单智能体的 Q i Q_i Qi的函数,mixing network则是以 Q i Q_i Qi作为输入,输出为联合 Q t o t Q_{tot} Qtot。为了保证单调性,mixing network的网络参数权重和偏置通过hypernetworks网络计算得出,并且hypernetworks输出的网络权重都必须大于0,对偏置没有要求。

图3. QMIX网络结构
3. 算法流程
-
初始化网络eval_agent_network,eval_mixing_network这两个网络,分别将这两个网络的参数复制给target_agent_network,targent_mixing_network.初始化buffer D D D,容量为 M M M,总迭代轮数 T T T,target_agent_network,targent_mixing_network两个网络参数更新频率 p p p。
-
f o r for for t = 1 t=1 t=1 t o to to T T T d o do do
1)初始化环境
2)获取环境的 S S S,每个agent的观察值 O O O,每个agent的 a v a i l avail avail a c t i o n action action,奖励 R R R。
3) f o r for for s t e p = 1 step=1 step=1 t o to to e p i s o d e episode episode_ l i m i t limit limit
a)每个agent通过eval_agent_network获取每个动作的 Q Q Q值,eval_agent_network中有GRU循环层,需要记录每个agnet的隐藏层,作为下次GRU隐藏的输入。(一一对应)
b)通过计算出的Q值选择动作。(1,通过最大的 Q Q Q值进行选取动作,有小几率采取随机动作。2,将 Q Q Q值再进行一次softmax,随机采样(sample)动作)
c)将 S S S, S n e x t S_{next} Snext,每个agent的观察值 O O O,每个agent的 a v a i l avail avail a c t i o n action action,每个agent的 n e x t next next a v a i l avail avail a c t i o n action action,奖励 R R R,选择的动作 u u u,env是否结束 t e r m i n a t e d terminated terminated,存入经验池 D D D。
d) i f if if l e n ( D ) len(D) len(D) > = >= >= M M M
e)随机从 D D D中采样一些数据,但是数据必须是不同的episode中的相同transition。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络传入每个episode的同一个位置的transition。
f)通过DQN相同的方式更新参数:
L ( θ ) = ∑ i = 1 b [ ( y i t o t − Q t o t ( τ , u , s ; θ ) ) 2 ] L(\theta)=\sum_{i=1}^b[(y_i^{tot}-Q_{tot}(\tau,u,s;\theta))^2] L(θ)=∑i=1b[(yitot−Qtot(τ,u,s;θ))2]
g) i f if if t e r m i n a t e d terminated terminated == T r u e True True a n d and and s t e p step step < = <= <= e p i s o d e episode episode_ l i m i t limit limit
h) f o r for for k = s t e p k=step k=step t o to to e p i s o d e episode episode_ l i m i t limit limit
i)将不足的数据用0进行填充,保证数据的一致性。
j) S , a v a i l a c t i o n = S n e x t , n e x t a v a i l a c t i o n S,avail\space\space action = S_{next},next \space avail \space action S,avail action=Snext,next avail action
k) i f if if t t t % p = = 0 p==0 p==0
l)将eval_agent_network,eval_mixing_network网络参数复制给target_agent_network,targent_mixing_network
4. 结果分析
关于QMIX的实验结果,paper中先用一个比较简单的tabular的游戏two-step game来证明了QMIX相较于VDN,更容易找到最优解,而VDN则会陷入局部最优解(具体内容有兴趣的读者可以查阅论文第5节)。 作者在星际争霸2的多个任务下也进行了实验测试,如下图所示:
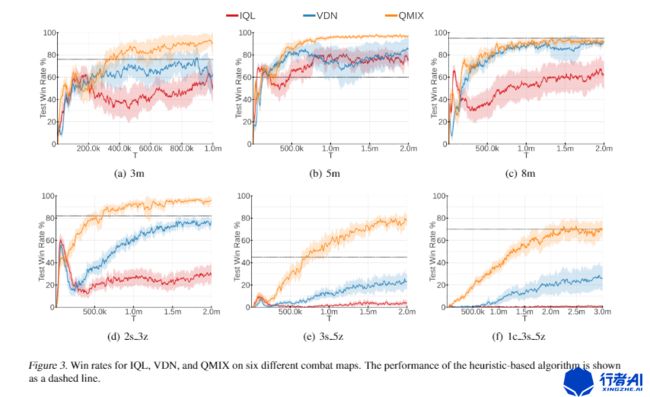
图4. QMIX和VDN,IQL在smac
在paper中还提到了QMIX要比VDN更好的使联合动作的优势更加突出,下图中,a表示VDN,b表示QMIX,agent1和agent2在学习之后,VDN中A和B的联合最优动作的价值为6.51,而QMIX的联合最优动作的价值为8.0。可以看出QMIX体现出的优势联合动作的价值更大。

图5. VDN和QMIX优势比较
5. 关键代码
5.1 网络结构
agent_network,采用循环神经网络GRU,上一回合输出的隐藏做为当前回合的输入。
class RNN(nn.Module):
# Because all the agents share the same network, input_shape=obs_shape+n_actions+n_agents
def __init__(self, input_shape, args):
super(RNN, self).__init__()
self.args = args
self.fc1 = nn.Linear(input_shape, args.rnn_hidden_dim)
self.rnn = nn.GRUCell(args.rnn_hidden_dim, args.rnn_hidden_dim)
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.n_actions)
def forward(self, obs, hidden_state):
x = f.relu(self.fc1(obs))
# print(hidden_state.shape,"xxxxx")
h_in = hidden_state.reshape(-1, self.args.rnn_hidden_dim)
# print(h_in.shape,"uuu")
h = self.rnn(x, h_in)
q = self.fc2(h)
print(q)
print(h)
return q, h
class QMixNet(nn.Module):
def __init__(self, args):
super(QMixNet, self).__init__()
self.args = args
# 因为生成的hyper_w1需要是一个矩阵,而pytorch神经网络只能输出一个向量,
# 所以就先输出长度为需要的 矩阵行*矩阵列 的向量,然后再转化成矩阵
# args.n_agents是使用hyper_w1作为参数的网络的输入维度,args.qmix_hidden_dim是网络隐藏层参数个数
# 从而经过hyper_w1得到(经验条数,args.n_agents * args.qmix_hidden_dim)的矩阵
if args.two_hyper_layers:
self.hyper_w1 = nn.Sequential(nn.Linear(args.state_shape, args.hyper_hidden_dim),
nn.ReLU(),
nn.Linear(args.hyper_hidden_dim, args.n_agents * args.qmix_hidden_dim))
# 经过hyper_w2得到(经验条数, 1)的矩阵
self.hyper_w2 = nn.Sequential(nn.Linear(args.state_shape, args.hyper_hidden_dim),
nn.ReLU(),
nn.Linear(args.hyper_hidden_dim, args.qmix_hidden_dim))
else:
self.hyper_w1 = nn.Linear(args.state_shape, args.n_agents * args.qmix_hidden_dim)
# 经过hyper_w2得到(经验条数, 1)的矩阵
self.hyper_w2 = nn.Linear(args.state_shape, args.qmix_hidden_dim * 1)
# hyper_w1得到的(经验条数,args.qmix_hidden_dim)矩阵需要同样维度的hyper_b1
self.hyper_b1 = nn.Linear(args.state_shape, args.qmix_hidden_dim)
# hyper_w2得到的(经验条数,1)的矩阵需要同样维度的hyper_b1
self.hyper_b2 =nn.Sequential(nn.Linear(args.state_shape, args.qmix_hidden_dim),
nn.ReLU(),
nn.Linear(args.qmix_hidden_dim, 1)
)
def forward(self, q_values, states): # states的shape为(episode_num, max_episode_len, state_shape)
# 传入的q_values是三维的,shape为(episode_num, max_episode_len, n_agents)
episode_num = q_values.size(0)
q_values = q_values.view(-1, 1, self.args.n_agents) # (episode_num * max_episode_len, 1, n_agents) = (1920,1,5)
states = states.reshape(-1, self.args.state_shape) # (episode_num * max_episode_len, state_shape)
w1 = torch.abs(self.hyper_w1(states)) # (1920, 160)
b1 = self.hyper_b1(states) # (1920, 32)
w1 = w1.view(-1, self.args.n_agents, self.args.qmix_hidden_dim) # (1920, 5, 32)
b1 = b1.view(-1, 1, self.args.qmix_hidden_dim) # (1920, 1, 32)
hidden = F.elu(torch.bmm(q_values, w1) + b1) # (1920, 1, 32)
w2 = torch.abs(self.hyper_w2(states)) # (1920, 32)
b2 = self.hyper_b2(states) # (1920, 1)
w2 = w2.view(-1, self.args.qmix_hidden_dim, 1) # (1920, 32, 1)
b2 = b2.view(-1, 1, 1) # (1920, 1, 1)
q_total = torch.bmm(hidden, w2) + b2 # (1920, 1, 1)
q_total = q_total.view(episode_num, -1, 1) # (32, 60, 1)
return q_total
5.2 动作选择
这里采用的是epsilon的方式更新,有一定的几率随机选取动作。另一种方式,将Q值再进行一次softmax,然后采样获取动作。
def choose_action(self, obs, last_action, agent_num, avail_actions, epsilon, maven_z=None, evaluate=False):
inputs = obs.copy()
avail_actions_ind = np.nonzero(avail_actions)[0] # index of actions which can be choose
# transform agent_num to onehot vector
agent_id = np.zeros(self.n_agents)
agent_id[agent_num] = 1.
if self.args.last_action:
inputs = np.hstack((inputs, last_action))
if self.args.reuse_network:
inputs = np.hstack((inputs, agent_id))
# print("input:", inputs, last_action, agent_id)
# print("hidden:", self.policy.eval_hidden.shape)
hidden_state = self.policy.eval_hidden[:, agent_num, :]
# transform the shape of inputs from (42,) to (1,42)
inputs = torch.tensor(inputs, dtype=torch.float32).unsqueeze(0)
avail_actions = torch.tensor(avail_actions, dtype=torch.float32).unsqueeze(0)
if self.args.cuda:
inputs = inputs.cuda()
hidden_state = hidden_state.cuda()
# get q value
q_value, self.policy.eval_hidden[:, agent_num, :] = self.policy.eval_rnn(inputs, hidden_state)
# choose action from q value
q_value[avail_actions == 0.0] = - float("inf")
if np.random.uniform() < epsilon:
action = np.random.choice(avail_actions_ind) # action是一个整数
else:
action = torch.argmax(q_value)
return action
5.3 learn更新网络参数
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition 3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络传入每个episode的同一个位置的transition。
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
episode_num = batch['o'].shape[0]
self.init_hidden(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'u':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
s, s_next, u, r, avail_u, avail_u_next, terminated = batch['s'], batch['s_next'], batch['u'], \
batch['r'], batch['avail_u'], batch['avail_u_next'],\
batch['terminated']
mask = 1 - batch["padded"].float() # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数,max_episode_len, n_agents,n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len)
if self.args.cuda:
s = s.cuda()
u = u.cuda()
r = r.cuda()
s_next = s_next.cuda()
terminated = terminated.cuda()
mask = mask.cuda()
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
q_evals = torch.gather(q_evals, dim=3, index=u).squeeze(3)
# 得到target_q
q_targets[avail_u_next == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
q_total_eval = self.eval_qmix_net(q_evals, s)
q_total_target = self.target_qmix_net(q_targets, s_next)
targets = r + self.args.gamma * q_total_target * (1 - terminated)
td_error = (q_total_eval - targets.detach())
masked_td_error = mask * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
self.target_qmix_net.load_state_dict(self.eval_qmix_net.state_dict())
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['o'][:, transition_idx], \
batch['o_next'][:, transition_idx], batch['u_onehot'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['o'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda()
inputs_next = inputs_next.cuda()
self.eval_hidden = self.eval_hidden.cuda()
self.target_hidden = self.target_hidden.cuda()
q_eval, self.eval_hidden = self.eval_rnn(inputs, self.eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_hidden = self.target_rnn(inputs_next, self.target_hidden)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数,max_episode_len,n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
5.4 代码总结
MARL的代码相对来说要比single RL的代码要复杂的多,笔者还是建议读者看懂原理之后,自己手敲一遍,敲一遍之后会对一个算法的理解程度大大的提升。
6. 资料
1.QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning