【论文笔记】Effective Policy Adjustment via Meta-Learning for Complex Manipulation Tasks
【论文笔记】Effective Policy Adjustment via Meta-Learning for Complex Manipulation Tasks
Abstract
本文提出的方法是将元强化学习的MAML算法与HER事后经验回放算法结合。
HER算法提升智能体在稀疏奖励环境下的探索能力
MAML元学习算法能够在新任务下通过快速调整参数,提升其在利用环境下能力
HER + MAML 方法可以加速新任务下策略的微调(神经网络组成的策略梯度RL);提升了成功率;
I. INTRODUCTION
The balance between exploration and exploitation is recognized as the critical issue for designing appropriate RL algorithms.
The complex manipulation tasks we put the focus on are the robotic manipulation tasks with sparse and binary rewards, such as pushing, sliding, picking objects by robot’s arm.
Reevaluating the transition trajectories according to both the target state and the state which has been achieved, the RL algorithms could adjust policy not only from the successful trajectories but also the failed ones.
从对目标状态和以遍历状态上的重新评估可以得出,RL算法可以从成功的轨迹中调整策略,也可以从失败的策略中调整。
converting single-goal to multi-goal will make the algorithm suffer from the high-dimensional goal space and the nonstationary policy evaluation while policy training.
从单目标优化转到多目标优化会使得算法存在高维度的目标空间和非静止的策略评估现象
Therefore, we are focused on the improvement of policy adjustment efficiency, making the multi-goal RL algorithm more efficient.
从策略调整效率上优化多目标问题,让多目标RL算法更加有效
learning quickly from limited experience and gradually adjusting while new experience has become available could be defined as a learn-to-learn framework (meta-learning)
Briefly, the learning goal of MAML could be summarized as enhancing the sensitivity of the original loss functions on the basis of present network parameters for learning the new data quickly.
MAML的学习目标是最大化原损失函数在各个新任务下的敏感度
Compared with HER and DDPG, simulation results on complex robotic manipulation tasks show that the proposed reinforcement learning algorithm could accelerate training efficiency of deep neural networks and promote a better performance on the final success rate.
II. RELATED WORK
DDPG 介绍
The actor network is defined as a policy network S : S → A S : S \rightarrow A S:S→A o to select action according to the current state, and the critic network is defined as a value network Q : R × A → S Q: R\times A \rightarrow S Q:R×A→S to evaluate the current policy.
To approximate the actor’s function Q S Q_{S} QS , the loss function of the critic network L c L_{c} Lc is defined as
L c = E ( Q ( s t , a t ) − y t ) 2 (1) L_{c}=E(Q(s_{t},a_{t})-y_{t})^{2}\tag{1} Lc=E(Q(st,at)−yt)2(1)
where
y t = r t + γ max a ′ ∈ A Q ( s t + 1 , a ′ ) (2) y_{t}=r_{t}+\gamma\max_{a^{\prime}\in A}Q(s_{t+1},a^{\prime})\tag{2} yt=rt+γa′∈AmaxQ(st+1,a′)(2)
and the transition tuples ( s t , a t , r t , s t + 1 ) (s_{t},a_{t},r_{t},s_{t+1}) (st,at,rt,st+1) are sampled from the replay buffer during each iteration.
The loss function L a L_{a} La of actor network is defined as
L a = − E s Q ( s t , π s ) (3) L_{a}=-E_{s}Q(s_{t},\pi_{s})\tag{3} La=−EsQ(st,πs)(3)
which is designed to train the actor network for maximizing the value of critic network.
Meta Learning 介绍
【元强化学习】经典meta-RL算法之MAML - 知乎 (zhihu.com)
III. METHOD
A. The Concept of Multi-goal RL
The complex tasks considered in this paper is an environment with a state space which is too large to be explored sufficiently.
复杂的环境在本文中定义为状态空间太大了以至于不能有效地探索
In other words, the complexity of tasks has a directly negative impact on the RL algorithm’s exploration performance.
To solve the exploration problem in the large state space with sparse and binary rewards, Hindsight Experience Replay (HER) could be performed well, which is an improved RL algorithm based on DDPG mentioned above.
However, for the transition trajectories recorded in the replay buffer are directly related to the external environment other than the target state (the agent’s goal), the present trajectory could be stored not only for the original target state but also other states.
在经验池中的轨迹直接与外部环境相关,但是与目标状态(智能体的目标)间接关联。
That is, the agent generates actions with the help of actor network or certain rules, instead of the transition results and the total transition trajectories depending on the environment. As a result, if the transition trajectories experience any other goals in the goal space, the transition trajectories could be recognized as a successful transition to the reached goals. By such an operation to adjust policies, the ability of exploration could be enhanced effectively at the start of the training procedure.
如果这个轨迹经理了目标空间中的一个,都可以被视为是成功的轨迹
通过这样增加目标空间的元素,增加目标增加成功的轨迹,训练过程初期的探索能被有效增强
In multi-goal RL, the actor network and the critic network are designed to take not only a state s ∈ S s\in S s∈S but also a goal g ∈ G g\in G g∈G as inputs for policy adjustment and policy evaluation.
Moreover, the reasonable assumption could be made that the state s obeys the mapping m : S → G m: S \rightarrow G m:S→G s.t. ∀ s ∈ S f m ( s ) ( s ) = 1 \text{s.t.} \ \forall_{s\in S}f_{m(s)}(s)=1 s.t. ∀s∈Sfm(s)(s)=1, indicating every goal is related to a specific state.
B. Multi-goal RL via Model-Agnostic Meta-Learning
Specifically, although HER could enhance the exploration ability of DDPG, the problem it brings is the high-dimensional goal space and the nonstationary extending of the replay buffer.
Model-Agnostic Meta-Learning (MAML) was proposed on the intuition that some internal representations are also useful for being transferred for other problem. In the proposed algorithm, the meta-learning training procedure is directly used for both the actor network training procedure and the critic network training procedure in HER algorithm.
把MAML元学习算法用于演员和评论家的训练中
During each iteration, the current actor network generates the action according to not only the current state but also the selected goal, which is sampled from the goal space, then the agent generates corresponding actions by the current actor network and changes its own states with a series of interactions.


IV. SIMULATION RESULTS
实验指标:成功率,灵敏度分析
A. Environments
For the robot joints are always controlled by closed-loop control, the force generated by joints could be reflected from the corresponding velocity.
由关节生成的力可以从相应的速度中反馈出来
During each iteration, the initial state and the target goal are randomly selected from the state space and the goal space respectively, and the observations are relative difference between the current state and the target state.
B. Performance for Complex Manipulation Tasks
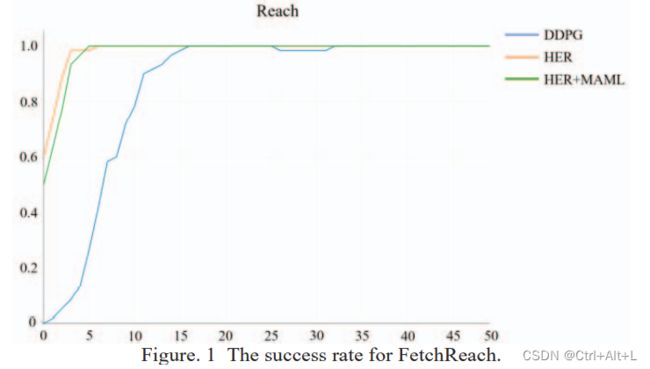
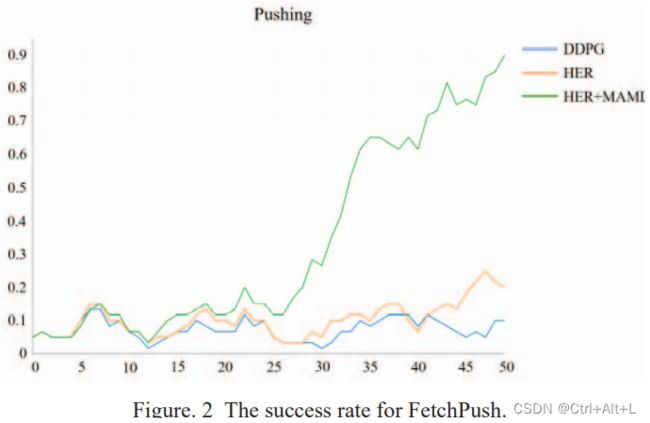
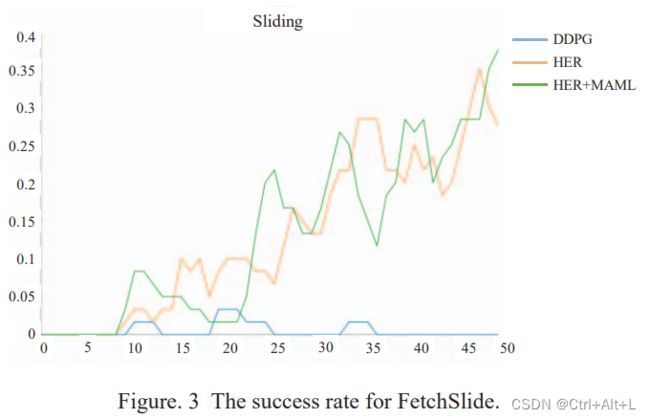

not only from the speed of training but also from the final success rate
C. Sensitivity Analysis
对数值k进行了分析
K, indicating the number of selected trajectories during each one gradient update.
K的意思是MAML元训练过程中,用于做 Support set 的轨迹条数

for the proposed algorithm of a large k is similar to the original HER algorithm, and a small k could not provide a stable gradient for total gradient calculation.