NeurIPS2020 Generalized Focal Loss论文翻译
NeurIPS2020 Generalized Focal Loss论文翻译
-
-
- 摘要
- 1. 介绍
- 2.相关工作
- 3. 方法
- 4.实验
- 5.结论
- 参考
-
论文地址: Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
作者解读: https://zhuanlan.zhihu.com/p/147691786
摘要
one-stage检测器基本将目标检测制定为密集分类和定位(即边框回归)。分类通常由Focal loss优化,边框定位一般用狄拉克δ函数来学习。one-stage检测器的最新趋势是引入一个单独的预测分支来估计定位质量,预测的定位质量通过促进分类来提高检测性能。本文对上述三个基本要素的表示进行了研究:质量估计,分类和定位。在现有的实践中发现了两个问题,(1)训练和推理在质量估计和分类上的使用不一致(例如,单独训练但在测试中组合使用),(2)在复杂场景中经常出现模糊和不确定性时,用于定位的狄拉克δ函数不够灵活。为了解决这些问题,我们为这些元素设计新的表示。具体来说,我们将质量估计合并到类预测向量中,形成定位质量和分类的联合表示,并使用一个向量来表示边框位置的任意分布。改进的表示方法消除了不一致的风险,准确地描述了真实数据灵活的分布,但包含连续的标签,这超出了 Focal Loss的能力范围。我们提出了 Generalized Focal Loss (GFL),它将Focal Loss从它的离散形式推广到连续的版本来成功优化。在 COCO test-dev上,采用相同的骨干网络和训练设置,GFL使用ResNet-101骨干网络实现了45.0%的mAP,超过了SOTA的SAPD (43.5%) 和ATSS (43.6%),并拥有更高或可比的推理速度。值得注意的是,我们最好的模型可以实现48.2%的单模型单尺度AP,在单个2080Ti GPU上每秒10帧。代码和预先训练的模型可以在https://github.com/implus/GFocal获得。
1. 介绍
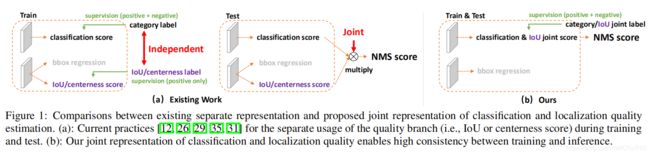
近年来,密集探测器逐渐引领了物体探测的潮流,同时,对边界框的表示及其定位质量估计的关注也带来了令人鼓舞的进步。特别地,边框表示被建模为简单的Dirac delta分布[10,18,32,26,31],多年来被广泛使用。在FCOS[26]中,预测一个额外的定位质量(如IoU评分[29]或centerness评分[26])会带来检测精度的持续提高,当质量估计与分类置信度结合(通常是相乘)作为推理期间的非最大抑制(NMS)最终得分[12,11,26,29,35]的排序过程。尽管他们很成功,但我们在实践中发现了下列的问题:
训练和推理对定位质量估计和分类得分的使用不一致:
- 在最近的密集探测器中,定位质量估计和分类得分通常单独训练,但在推理的时候又组合在一起使用(例如,相乘)[26, 29] (Fig. 1(a));
- 目前对定位质量估计的监督只针对正样本[12,11,26,29,35],这是不可靠的,因为负样本可能有机会得到无法控制的更高质量的预测 (Fig. 2(a));
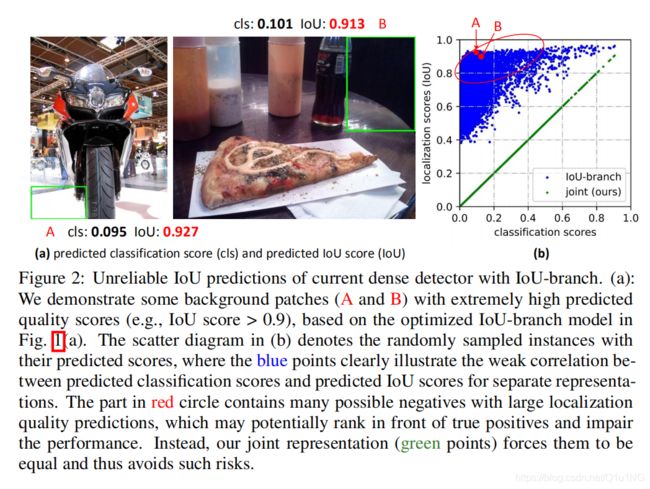
这两个因素导致了训练和测试之间的差距,并且有可能会降低检测性能,例如,在NMS中,具有随机高得分的负样本可以排在预测质量较低的正样本前面。
不灵活的边框表示: 广泛使用的边框表示可以看作是目标框坐标的Dirac delta 分布[7,23,8,1,18,26,13,31]。然而,它没有考虑数据集的模糊性和不确定性(在Fig. 3中查看不清楚边界的统计图)。虽然最近的一些研究[10,4]将边框建模为高斯分布,但它太简单了以至于不能捕捉边界框位置的真实分布。实际上,真实的分布更加随意和灵活[10],而不像高斯函数的对称。
为了解决上述问题,我们为边框和定位质量设计了一个新的表示。
- 对于定位质量的表示: 我们建议将其与分类得分合并为一个统一的表示:一种分类的向量,其在真实标签类别索引上的值表示其对应的定位质量(通常为本文中预测边框与对应的真实标签框之间的IoU得分)。按照这种方式,我们将分类得分和iou得分联合为一个共同单一的变量(记为“分类联合表示”),以端到端的方式训练,同时在推理过程中直接使用(Fig. 1(b)。因此,他消除了训练与测试时候的不一致(Fig. 1(b))并使得定位质量与分类之间的相关性最强(Fig. 2(b))。更多的,负样本将被监督为0质量得分,因此,整体质量预测变得更加可信和可靠。这对于密集目标探测器尤其有利,因为它们对整个图像中定期采样的所有候选对象进行排序。
- 对于边框表示: 我们提出通过直接学习连续空间上离散化的概率分布来表示边框定位任意的分布(在此论文中称为"General distribution通用的分布"),而不引入任何其他更好的先验(如高斯[10,4])。因此,我们可以获得更可靠更精确的边框估计,同时注意到其各种潜在分布(参见Fig. 3中的预测分布和补充材料)。

改进后的表示就给优化带来了挑战,传统的密集检测器,分类分支采用Focal loss(FL)[18]优化。通过重构标准交叉熵损失,FL可以成功地解决类不平衡问题。然而,对于提议的分类- iou联合表示代表的情况,除了仍然存在的不平衡风险之外,对于使用连续的IoU标签(0 ~ 1)作为监督,我们面临一个新问题,因为原来的FL目前只支持离散的{1,0}类别标签。我们通过扩展FL从离散版本到连续变体,成功的解决了这个问题,我们称它为Generalized Focal Loss (GFL)。与FL不同,GFL考虑了一种更通常的情况,即全局优化解能够以任意期望的连续值为目标,而不是离散值。更具体地说,在这篇论文中,GFL可细化为Quality Focal Loss(QFL)和Distribution Focal Loss(DFL),为了分别优化改进的这两个表示: - QFL专注于难样本的稀疏集,同时在相应的类别上产生连续的0 ~ 1质量估计;
- DFL使得网络在任意灵活分布的条件下,快速专注于学习目标边框连续位置周围值的概率。
我们验证了GFL的三个好处:
- 它弥补了训练和测试之间的差距,在one-stage检测器的辅助质量估计,使得更简单,联合和有效的表示分类和定位质量;
- 很好地模拟了边框的灵活底层分布,提供了更多信息和更准确的边框位置;
- one-stage检测器的性能可以在不引入额外开销的情况下得到持续提升。
在COCO test-dev上,GFL使用ResNet-101作为骨干网络实现了 45.0%的AP,超过了SOTA方法
SAPD (43.5%) 和ATSS (43.6%)。我们最好的模型可以实现48.2%的单模型单尺度AP,在单个2080Ti GPU上每秒10帧。
2.相关工作
定位质量的表示: 现有的实践,如Fitness NMS [27], IoU-Net [12], MSR-CNN[11]、FCOS[26]和IoU-aware[29]利用单独的分支以IoU或centerness score的形式进行定位质量估计。如第1节所述,这种单独的提法导致了训练和测试之间的不一致,以及不可靠的质量预测。和额外加一个分支不同的是,PISA [2] 和IoU-balance [28]根据各自的定位质量对分类损失赋予不同的权重,来增强分类得分和定位质量的联系。然而,由于加权策略不改变分类损失目标的最优性,因此其效益是隐性的和有限的。
边框的表示: Dirac delta分布[7,23,8,1,18,26,13,31]支配着过去几年的边框的表示。最近采用高斯假设[10,4]通过引入预测方差来学习不确定性。不幸的是,现有的表示要么过于严格要么过于简化,不能反映真实数据复杂的低层分布。在这篇论文里,我们进一步放宽了假设,直接学习更加随意、灵活的,通用的边界框分布,同时更有用和准确。
3. 方法
在这个章节,我们首先回顾原始的Focal Loss(FL)[18]学习密集分类得分的one-stage检测器。然后我们详细介绍了改进之后的定位质量和边框的表示,可以通过提出的 Quality Focal Loss (QFL) 和 Distribution Focal Loss (DFL)成功的优化。最后,我们归纳QFL和DFL的公式统一化为Generalized Focal Loss(GFL),作为FL的一个灵活扩展,以促进未来进一步的提升和普遍的了解。
Focal Loss (FL): 原始的FL的提出是为了解决one-stage目标检测在训练时存在的前景和背景极度不平衡的场景。FL的一种典型形式如下(为了简单起见,我们忽略了原论文[18]中的αt):
![]()
其中,y∈{1,0}表示标签类,p∈[0,1]表示标签y = 1的类的估计概率。γ是可调的聚焦参数。特别地,FL由一个标准的交叉熵部分 -log(pt)和一个动态可调的缩放系数 部分(1- pt)γ,(1- pt)γ自动降低简单示例的权重,使模型快速聚焦于困难示例。
Quality Focal Loss (QFL): 解决上述培训和测试阶段之间的不一致问题,我们提出一个定位质量(例如,iou分数)和分类得分的联合表示(简称“classification-IoU”),它的监督软化了标准的独热点类别标签,并使得对应类别上的一个可能的浮点数标签y∈[0,1] (见 Fig. 4中的分类分支)。特别地,y=0表示质量分数为0的负样本,0 < y≤1表示目标IoU得分为y的正样本。请注意,定位质量标签y遵循[29,12]中的传统定义:IoU在训练过程中预测的边框与其对应的真实标签框之间的得分,是一个动态值为0 ~ 1。按照[18,26]一样,我们采用多个带有sigmoid操作σ(·)的二分类来实现多分类。为简单起见,sigmoid的输出被标记为σ。
由于提出的classification-IoU联合表示需要对整个图像进行密集的监督,且仍然存在类不平衡问题,因此必须继承FL的思想。然而,当前的FL仅支持离散标签 {1, 0},而我们的新标签包含小数。因此我们提出扩展FL的两部分,以便在联合表示的情况下成功地进行训练:
- 交叉熵-log(pt)的部分展开为他的完成版本
-((1-y)log(1-σ) + ylog(σ)); - 缩放系数的部分(1- pt)γ推广为估计量σ及其连续标签y的绝对值, 即|y - σ|β (β ≥ 0),这里|·|保证了非负性。随后,我们将上述两个扩展部分结合起来,形成完整的目标损失,即称为 Quality Focal Loss (QFL):
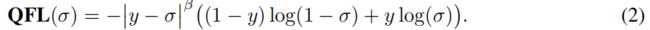
请注意,σ = y是QFL的全局最小解。Fig. 5(a)是QFL通过一些β的值(质量标签y = 0.5)的可视化。与FL相似,QFL中的|y - σ|β部分为一个可调节的系数:当一个样本的质量估计是错的并且偏离了标签y,这个可调节的系数就会相应的较大,因此就会将更多的注意力放在困难样本上。当质量评估变得准确时,即 , σ → y,该系数就是偏向0,易样本的损失权重就会减少,在此情况下,参数控制器平稳地控制降权率(在我们的实验中,对于QFL来说,β = 2是最有效的)。

Distribution Focal Loss (DFL): 和 [26, 31]一样,我们采用位置到边框四边的相对偏移量作为回归目标 (在Fig. 4查看回归分支)。传统的边框回归将标签y建模为Dirac delta分布δ(x - y),它满足∫-∞+∞(x - y) dx = 1,通常通过全连接层实现。更正式地,求出y的积分形式如下:

根据第1节的分析,代替狄拉克函数[23,8,1,26,31]或高斯函数[4],[10]假设,我们建议直接学习潜在的一般分布P(x)而不引入任何其他先验。对于标签y的范围,最小值y0和最大值yn (y0 ≤ y ≤ yn, n ∈ N+),我们可以从模型估计回归值yˆ(yˆ也满足y0≤yˆ≤yn):
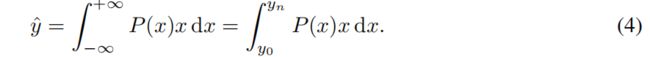
为了与卷积神经网络保持一致,我们将连续域上的积分转换为离散表示,通过离散范围[y0, yn]组成一个集合{y0, y1,…,yi, yi+1,……, yn-1, yn},间隔∆(为简单起见,我们使用∆= 1)。因此,鉴于离散分布性质 Σni=0P(yi) = 1, 估计的回归值yˆ可以表示为:
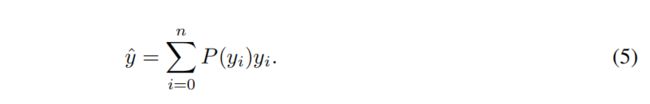
因此,P(x)可以通过由n + 1个单元组成的softmax S(·)层轻松实现,为简单起见,P(yi)被表示为Si。注意,yˆ与传统损失目标像SmoothL1[7],IOU损失[27]或GIoU损失[24]一样可以被训练在一个端到端的方式。然而,P(x)的值有无限个组合可以使最终的积分结果为y,如 Fig. 5(b)所示,这样可能会降低学习效率。直观的与(1)与(2)比较,分布(3)比较紧凑,在边框估计上更加自信和精确,这促使我们通过明确地鼓励接近目标y值的高概率来优化P(x)的形状。此外,通常情况下,最合适的潜在定位(如果存在的话)将离粗糙的标签不远。因此,我们引入了 Distribution Focal Loss(DFL),通过显式增大yi和yi+1的概率(最接近y的两个值, yi≤y≤yi+1),它迫使网络快速聚焦于接近标签y的值。由于边框的学习只针对正样本,不存在类不平衡问题的风险,因此我们在DFL的定义中简单应用QFL中的整个交叉熵部分:
![]()
直观地,DFL的目标是扩大目标y周围值(即yi和yi+1)的概率。DFL的全局最小解,即Si= (yi+1- y)/(yi+1-yi), Si+1 = (y- yi)/(yi+1-yi) (见补充材料),能保证预测的回归目标yˆ无限接近相应的标签y,即 ![]()
这也保证了它作为一个损失函数的正确性。

Generalized Focal Loss (GFL): 注意QFL和DFL可以统一成一个普遍形式,在本文中称为GFL。假设一个模型估计两个变量yl,yr(yl
![]()
GFL的性能: GFL(pyl, pyr ) 通过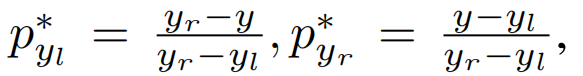
来获取他的全局最小值,这也代表了估计值yˆ 完美的匹配了他的连续标签y,即, yˆ = ylpyl∗ + yrpyr∗ = y(详见补充材料)。显然,原来的FL[18]和提议的QFL和DFL都是GFL的特殊情况(详见补充资料)。注意,GFL可以应用于任何one-stage检测器。改进后的检测器与原检测器有两个不同之处。第一,前向推理的过程中,我们直接输入分类得分(与质量估计的联合表示)作为NMS评分,而不需要乘以任何单独的质量预测,如果存在的话(例如,在FCOS[26]和ATSS[31]中的centerness)。第二,用于预测边框每个位置的回归分支的最后一层现在有n + 1个输出,而不是1个输出,这带来的额外计算成本可以忽略不计,如Table 3所示。
使用GFL训练密集检测器:
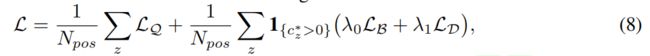
LQ表示QFL,LD表示DFL。一般情况下,LB表示GIoU损失,如[26,31]。Npos表示正样本的数量。λ0(和[3]一样,通常默认为2)和λ1(实际上是1/4,平均在四个方向上)分别是LQ和LD的平衡权重。对金字塔特征图[17]上的所有位置z进行求和。
1{cz∗ >0}是指示器函数,如果cz∗ > 0就为1,否则为0。按照官方代码[3,26,31,15]中的常见做法,我们还在训练期间利用质量分数来计算LB和LD的权重。
4.实验
我们的实验是在COCO benchmark[19]上进行的,其中使用trainval35k (115K images)进行训练,我们使用minival (5K images)验证我们的消融研究。主要结果在test-dev上报告(20K图像),这些图像可以从评估服务器获得。为了公平的比较,所有的结果都来自mmdetection[3],其中采用默认超参数。除非另有说明,我们采用1x学习策略(12 epoch)进行以下研究,并且不进行多尺度训练,基于ResNet-50 [9]作为骨干网络。更多的训练/测试细节可以在补充材料中找到。

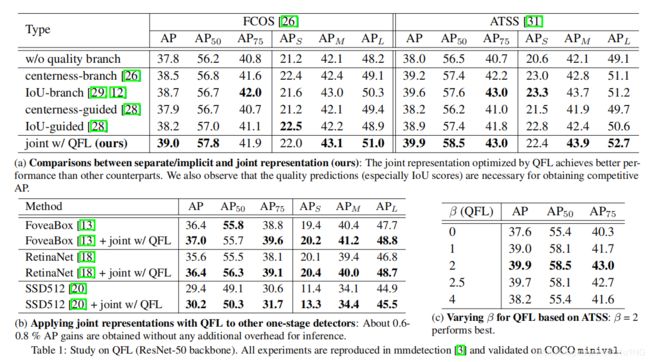
第一: 我们首先调查了QFL的有效性(Table 1)。在Table 1(a)中,我们将提议的联合表示与单独的或隐含的对应表示进行了比较。两种表示定位质量的方法:实验中也采用IoU[29,12]和centerness[26,31]。一般来说,我们构造使用分离或隐式表示的4个变量,如Fig. 6所示。根据计算结果,我们观察到使用QFL优化联合表示始终比所有对应的方法表现得更好,而IoU作为定位质量(补充材料)的衡量标准总是比中心度更好。 Table 1(b)展示了显示
QFL还可以提高其他常用的one-stage检测器的性能,Table 1©表明,对于QFL,β = 2是最好的设置。 我们通过IoU-branch模型和我们的模型的预测分类和IoU得分的抽样实例来说明联合表示的有效性,如Fig. 2(b)。实验结果表明,采用QFL训练的联合表示方法可以提高质量估计的可靠性,并且根据其定义,分类与质量分数之间的相关性最强。事实上,在我们的联合表示中,预测的分类得分与估计的质量得分是完全相等的。
第二: 我们调查了DFL的有效性 (Table 2)。为了快速的为n选择一个合理的值,我们首先说明回归目标的分布Fig. 5©。我们将在后面的实验中说明,ATSS的推荐选择n为14或16。在Table 2(a)中,我们比较了不同数据表示的边框回归的有效性。我们发现,一般分布可以获得更好的或至少可比较的结果,而DFL可以进一步提高其性能。定量的比较如Fig. 7所示。可以看到,相比于高斯分布和Dirac delta分布,提出的通用分布可以提供更准确的边框位置,特别是在有相当大的遮挡的情况下(更多的讨论见补充材料)。在GFL训练的改进ATSS的基础上,我们在Table 2(b)和©中报告了n和∆在DFL中的作用。结果证明n的选择不敏感,在实际应用中建议∆较小(如1)。为了说明一般分布的效果,我们在Fig.3中绘制了几个具有代表性的实例,其边框分布在四个方向上,其中所提出的分布表示可以通过其形状有效地反映边框的不确定性(详见补充资料中的示例)。


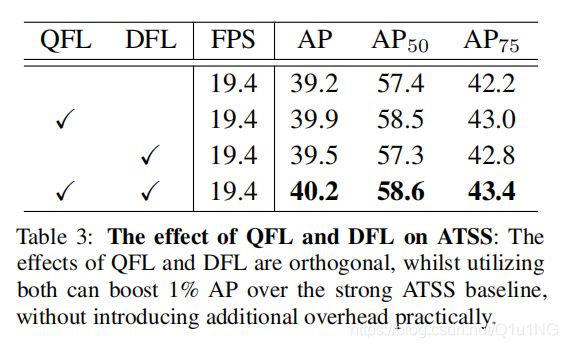
第三: 我们使用ResNet-50主干对ATSS进行了消融研究,以展示QFL和DFL的相对贡献 (Table 3)。在相同的mmdetection[3]框架下,使用同一台机器GeForce RTX 2080Ti GPU,批处理大小为1的测量每秒帧数FPS。我们观察到DFL的改进与QFL是正交的,并且两者的联合使用(即GFL)提高了强大的ATSS基线的绝对1% AP分数。此外,根据推理速度,GFL带来的额外开销可以忽略不计,被认为是非常实用的。
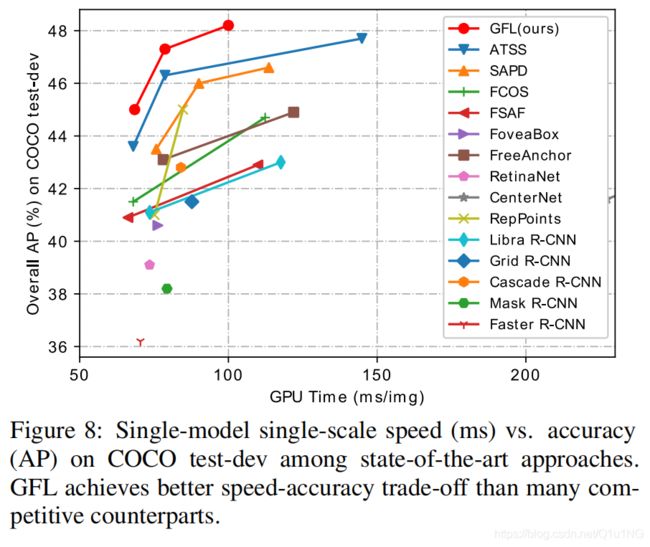
最后: 我们在Table 4上比较了GFL(基于ATSS)和最先进的COCO test-dev方法。在之前研究[18,26]的基础上,在训练中采用了多尺度训练策略和2x学习策略(24个epoch)。为了进行公平的比较,我们报告了所有方法的单模型单尺度测试的结果,以及相应的推断速度(FPS)。GFL与ResNet-101[9]的AP达到45.0%,14.6 FPS,优于现有的同骨干网络的检测器,包括SAPD[33] (43.5%)和ATSS[31] (43.6%)。更多的是,可形变卷积网络(DCN)[36]一贯地在ResNe(X)t骨干网络上提高性能,GFL与ResNeXt-101-32x4d-DCN以10FPS获得最先进的48.2% AP。 Fig. 8 显示了精度-速度平衡的可视化,其中可以看到,我们提出的GFL将精度-速度边界的包络线推到了一个很高的水平。

5.结论
为了有效地学习密集目标检测器的合格分布边界盒,我们提出了一种新的方法Generalized Focal Loss(GFL)将原始的 Focal Loss{1,0}离散公式推广到连续公式。GFL可以细化为Quality Focal loss(QFL)和 Distribution Focal Loss(DFL),其中QFL鼓励学习更好的分类和定位质量的联合表示,而DFL通过建模它们的位置作为一般分布,提供了更多的信息和精确的边框估计。大量的实验验证了该方法的有效性。
参考
[1] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In CVPR,
2018.
[2] Yuhang Cao, Kai Chen, Chen Change Loy, and Dahua Lin. Prime sample attention in object detection.
arXiv preprint arXiv:1904.04821, 2019.
[3] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng,
Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint
arXiv:1906.07155, 2019.
[4] Jiwoong Choi, Dayoung Chun, Hyun Kim, and Hyuk-Jae Lee. Gaussian yolov3: An accurate and fast
object detector using localization uncertainty for autonomous driving. In ICCV, 2019.
[5] Zhiwei Dong, Guoxuan Li, Yue Liao, Fei Wang, Pengju Ren, and Chen Qian. Centripetalnet: Pursuing
high-quality keypoint pairs for object detection. In CVPR, 2020.
[6] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint
triplets for object detection. In ICCV, 2019.
[7] Ross Girshick. Fast r-cnn. In ICCV, 2015.
[8] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In ICCV, 2017.
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition.
In CVPR, 2016.
[10] Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, and Xiangyu Zhang. Bounding box regression
with uncertainty for accurate object detection. In CVPR, 2019.
[11] Zhaojin Huang, Lichao Huang, Yongchao Gong, Chang Huang, and Xinggang Wang. Mask scoring r-cnn.
In CVPR, 2019.
[12] Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Yuning Jiang. Acquisition of localization
confidence for accurate object detection. In ECCV, 2018.
[13] Tao Kong, Fuchun Sun, Huaping Liu, Yuning Jiang, and Jianbo Shi. Foveabox: Beyond anchor-based
object detector. arXiv preprint arXiv:1904.03797, 2019.
[14] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In ECCV, 2018.
[15] Hengduo Li, Zuxuan Wu, Chen Zhu, Caiming Xiong, Richard Socher, and Larry S Davis. Learning from
noisy anchors for one-stage object detection. arXiv preprint arXiv:1912.05086, 2019.
[16] Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-aware trident networks for object
detection. In ICCV, 2019.
[17] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature
pyramid networks for object detection. In CVPR, 2017.
[18] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object
detection. In ICCV, 2017.
[19] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár,
and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[20] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and
Alexander C Berg. Ssd: Single shot multibox detector. In ECCV, 2016.
[21] Xin Lu, Buyu Li, Yuxin Yue, Quanquan Li, and Junjie Yan. Grid r-cnn. In CVPR, 2019.
[22] Jiangmiao Pang, Kai Chen, Jianping Shi, Huajun Feng, Wanli Ouyang, and Dahua Lin. Libra r-cnn:
Towards balanced learning for object detection. In CVPR, 2019.
[23] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection
with region proposal networks. In NeurIPs, 2015.
[24] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese.
Generalized intersection over union: A metric and a loss for bounding box regression. In CVPR, 2019.
[25] Guanglu Song, Yu Liu, and Xiaogang Wang. Revisiting the sibling head in object detector. In CVPR, 2020.
[26] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection.
In ICCV, 2019.
[27] Lachlan Tychsen-Smith and Lars Petersson. Improving object localization with fitness nms and bounded
iou loss. In CVPR, 2018.
[28] Shengkai Wu and Xiaoping Li. Iou-balanced loss functions for single-stage object detection. arXiv preprint
arXiv:1908.05641, 2019.
[29] Shengkai Wu, Xiaoping Li, and Xinggang Wang. Iou-aware single-stage object detector for accurate
localization. Image and Vision Computing, 2020.
[30] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for
object detection. In ICCV, 2019.
[31] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z Li. Bridging the gap between anchorbased and anchor-free detection via adaptive training sample selection. In CVPR, 2020.
[32] Xiaosong Zhang, Fang Wan, Chang Liu, Rongrong Ji, and Qixiang Ye. Freeanchor: Learning to match
anchors for visual object detection. In NeurIPs, 2019.
[33] Chenchen Zhu, Fangyi Chen, Zhiqiang Shen, and Marios Savvides. Soft anchor-point object detection. In
CVPR, 2020.
[34] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object
detection. In CVPR, 2019.
[35] Li Zhu, Zihao Xie, Liman Liu, Bo Tao, and Wenbing Tao. Iou-uniform r-cnn: Breaking through the
limitations of rpn. arXiv preprint arXiv:1912.05190, 2019.
[36] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better
results. In CVPR, 2019.