cs231n Assignment 1# SVM详细答案及总结
Assignment 1# SVM
- 线性分类器简介:
-
- score function:
- loss function
- naive implementation:
-
- loss function:
- gradient:
- vectorized implementation:
-
- loss:
- gradient:
线性分类器简介:
在这里的两个分类器SVM和softmax都是线性分类器,也是后序神经网络的基础。他由两部分组成:score function和loss function。
前者通过 W T x + b W^Tx+b WTx+b的线性方式计算出每一个图片向量对于不同类别的得分,后者则采用不同的loss对误差进行度量(SVM or softmax)。
score function:
对于一张高维的图片,首先还是将它伸展为一维的列向量。 W T x + b W^Tx+b WTx+b获得不同类别的得分向量。如下图所示。对于为什么矩阵相乘,W矩阵的意义是什么,解释是模式匹配。
W W W的每一行可以认为是各类别的模版(如下图中第一行可以认为是猫向量,算法认为标准的猫就是行向量的样子),每一行与图片向量的点乘可以看作一种距离的度量方式(很简单,如果两个向量相似,他们的余弦就小,点乘的结果就更大)。这样score越大就认为越可能属于该类。下图也提供了对训练后的 W W W可视化,更加印证了模式匹配这一观点。


loss function
loss function 分为两部分,分类误差和泛化误差。


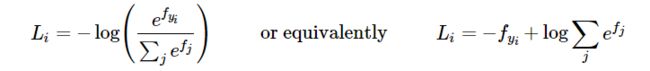
naive implementation:
这两部分分别现在linear_SVM.py 里面写好,是可以采用循环的。
loss function:
inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels;
对所有的N个样本循环,计算每一个的loss L i L_i Li。对于每一个 L i L_i Li先求出得分向量scores。 x [ i ] T W x[i]^TW x[i]TW。具体谁乘谁可以形状判断。遍历所有的错误类别看它的得分是不是超过正确类别大于一。
最后平均在加上reg loss。
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
loss /= num_train
loss += reg * np.sum(W * W)
gradient:
唯一可以依靠的就是上面loss 的计算式子。
感觉这里也是为后面的BP做铺垫,唯有链式法则方为正道。
两部分,reg loss部分的导数很简单,就是W矩阵的二倍。
model loss 部分。对于每个i我们对上式拆分 ∑ j ≠ y i [ max ( 0 , x i W j − x i W y i + δ ) ] \sum_{j\neq y_i}[\max(0,x_iW_j-x_iW_{y_i}+\delta)] ∑j=yi[max(0,xiWj−xiWyi+δ)]
这样链式求导
∂ L i ∂ W j = ∂ L i ∂ m a x ∂ m a x ∂ W j = 1 ( i f ( x i W j − x i W y i + δ ) ≥ 0 ) x i \frac{\partial L_i}{\partial W_j}=\frac{\partial L_i}{\partial max}\frac{\partial max}{\partial W_j}=1(if(x_iW_j-x_iW_{y_i}+\delta)\geq 0)x_i ∂Wj∂Li=∂max∂Li∂Wj∂max=1(if(xiWj−xiWyi+δ)≥0)xi
∂ L i ∂ W y i = ∂ L i ∂ m a x ∂ m a x ∂ W y i = ∑ j ≠ y i 1 ( i f ( x i W j − x i W y i + δ ) ≥ 0 ) x i \frac{\partial L_i}{\partial W_{y_i}}=\frac{\partial L_i}{\partial max}\frac{\partial max}{\partial W_{y_i}}=\sum_{j\neq y_i}1(if(x_iW_j-x_iW_{y_i}+\delta)\geq 0)x_i ∂Wyi∂Li=∂max∂Li∂Wyi∂max=j=yi∑1(if(xiWj−xiWyi+δ)≥0)xi
当时自己没有这样明确的弄出来就花了很大功夫debug,怎么也跑不对。还是要先弄清式子再写代码。
这样就很明确了,遍历所有的i,看 x i W j − x i W y i + δ x_iW_j-x_iW_{y_i}+\delta xiWj−xiWyi+δ是不是大于零,大于零就在loss的 W j W y i W_jW_{y_i} WjWyi部分分别加上相应的 x i x_i xi。
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
dW[:,j]+=X[i]
dW[:, y[i]] -= X[i]
dW=dW/num_train+2*reg*W
vectorized implementation:
loss:
思路就是对score得分矩阵(N,C)减去Y(Broadcast 之后的对应维度相减)。之后加一,大于零的是产生loss的以及正确的(减去自己再加一,肯定是一)。这样对所有元素求和之后减去N个正确维度的1,就是最终的loss。
score=X@W
realcalsses=score[np.arange(num_train),y]
print(score.shape)
print(realcalsses.shape)#对矩阵形状的测试
score-=realcalsses.reshape(-1,1)
scores=score+1
scorel=scores[scores>0]
loss+=sum(scorel)-num_train
loss/=num_train
前面说了捣鼓矩阵形状的时候多reshape,当然也可以print出来维度信息然后结合数学式子reshape。
注意
(5,)和(5,1)不一样!
(5,)是[1,2,3,4,5]是一个一维的array,不可以和(5,10)进行Broadcast运算。
(5,1)是[[1],[2],[3],[4],[5]]一个五行一列的高维array,可以和(5,10)Broadcast。
gradient:
这个比较confusing。
从上面的链式法则可以看出,对于每一个input x i x_i xi, d W dW dW在分类错误并且满足 x i W j − x i W y i + δ ) ≥ 0 x_iW_j-x_iW_{y_i}+\delta)\geq 0 xiWj−xiWyi+δ)≥0条件(后简称条件)那一列就是 x i x_i xi,分类正确的列为满足条件的错误类数目倍的 − x i -x_i −xi。(这句话确实绕,但是没办法。)
这样我们产生一个 S ( N , C ) S(N,C) S(N,C)矩阵每一行 S i T ( 1 , C ) S_i^T(1,C) SiT(1,C)在满足条件的错误类别上面是1,正确类别上面为负的满足条件的错误类数。
具体一点,对于一个 x i x_i xi,产生的 d W dW dW为 x i ( D , 1 ) x_i(D,1) xi(D,1)与 S i T ( 1 , C ) S_i^T(1,C) SiT(1,C)的外积。这样变成矩阵就是 X ( D , N ) X(D,N) X(D,N)和S(N,C)的内积。(着实费解)
zero_one=np.zeros((num_train,num_classes))#这就是我们上面的S矩阵
zero_one[scores>0]=1#margin大于零的设为一
zero_one[score==0]=0#进一步排除,正确列score为零
===============以上完成了错误列的数值===============
count=zero_one.sum(axis=1).reshape(num_train,1)#满足条件的错误数
zero_one[np.arange(num_train),y.reshape(1,num_train)]-=count.T#计算正确类别位置
dW=X.T@zero_one#矩阵乘法
dW=dW/num_train+2*reg*W
感觉还是很费解,当时我对着别人的code研究了好久。。。我尽力说的很明白了。