CS231N assignment1——SVM
Multiclass Support Vector Machine exercise
Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the assignments page on the course website.
In this exercise you will:
- implement a fully-vectorized loss function for the SVM
- implement the fully-vectorized expression for its analytic gradient
- check your implementation using numerical gradient
- use a validation set to tune the learning rate and regularization strength
- optimize the loss function with SGD
- visualize the final learned weights
关键点分析
-如何计算这个损失值
-如何计算梯度下降
Loss function计算
Loss function的形式: Li=∑j≠yimax(0,sj−syi+△) L i = ∑ j ≠ y i m a x ( 0 , s j − s y i + △ ) , 这里的 △ △ 常定义为1,如果是的意思是在进行完矩阵乘法的基础上即样本集乘上权重矩阵,每个样本都在每个标签上有了一个分数,然后目标标签是 yi y i ,累计其他比目标标签高的标签的分数,累计求和便是最后的结果了。
如果是直接的计算方式的话,那便是先进行矩阵乘法,然后遍历每一个样本,然后取出目标标签的分数,分别进行运算,但是这样的运算是需要进行一层循环的,类似于K近邻里面的计算方法,我们希望能够通过一些运算方式代替这样的循环。
那最直接的想法便是利用广播机制让整个矩阵减去目标标签分数向量再求和。这里的一个关键运算便是取出目标标签,(说好的不用循环就不用。。。),一种方法便是:
target_scores = raw_scores[np.arange(X.shape[0]), y] #np.arrange(X.shape[0])是生成了一个样本下标的列表,y也是一个列表对应的是一个标签其实也就是目标标签的下标有了这个方式,计算loss function便简单了,先通过广播机制计算出最后的分数偏差(默认此处已经加上1),然后通过np,maximum(scores, 0)得到损失值矩阵。这里面有两个需要注意的地方,1)因为当时是作为一个整体计算出了分数差,但从公式里面是可以看到这个损失值是不包括目标标签自己的,我们需要额外的一步消去这个偏差,2)另外一个结构风险系数不能忘了,用于控制避免最后的过拟合。
raw_scores = X.dot(W)
target_scores = raw_scores[np.arange(X.shape[0]), y] #目标标签分数
scores = np.maximum( raw_scores-np.reshape(target_scores, (-1,1))+1, 0) #得出和目标标签的分数偏差,取正向值
scores[np.arange(X.shape[0]), y] = 0 #消去偏差
margin = np.sum(scores, axis=1)
loss += np.sum(margin/X.shape[0]) + np.sum(2*reg*W.dot(W.T)) #分数偏差和结构风险值梯度迭代值的计算
个人觉得梯度迭代值这里是很有思考价值的,你可以试着自己好好想想,看下这个需要如何表示。
下面我就几个方面分析下我做的时候的一些想法:
首先梯度的概念就不做赘述了,如何是一个简单的W*x,W和x都是一个数,然后要就W进行求导,那么它的导数就应该只是x,这个大家应该都没有异议,麻烦的是这个是一个多分类SVM,就想象起来会有些困难,那么就一步步来吧,先明确下原先计算的式子,看下如果求导的结果应该是什么样子的,
单从一个样本出发看式子的话,可以分析出如果是对W矩阵求导,就应该是有两个求导的样子,对于W矩阵,如果是对于目标标签列的话,它的求导项应该是样本值,由于除了目标标签以外的其他标签都参与运算了,那最终的结果应该是用标签列有非0偏差值的列数目乘上这个样本作为W矩阵对应目标标签列的梯度值,目标标签列的长度等于样本的维度;
如果是对于非目标标签列的话,它的求导项也应该是样本值,但这里有个比较麻烦的地方,就是它是有max运算在其中,运算的结果会决定其实这个式子有没有对非目标标签列有求导因子,这里回忆下上面我们的一个式子,
scores[np.arange(X.shape[0]), y] = 0这里其实就已经有了这个结果了,但是这里面存的是一个分数,一个参考做法就是使用numpy的一个特殊用法,假定目标Numpy数组是a,希望A中大于0的元素都变成1:
import numpy as np
a = np.array([[-1,0,3],[2,7,1]])
a[a>0]=0a>0的操作其实是得到一个大小和a数组一致的bool矩阵,i行j列的元素代表原矩阵中i行j列的元素是否满足大于0,最后这个就相当于掩码,只有掩码值为真的元素才会得到改变。
所以最后如果是对一个样本来说,对于W权重矩阵和样本i,它的梯度应该表示如下:
下面就分析下如何向量化运算,现在我们先假设这个样本的维度和权重的维度都是1,然后有N个样本,c个分类,然后对于每一个样本我们都有一个矩阵,矩阵是N行C列,代表之前运算分数的结果,如果之前是大于0的就计为1,然后样本的目标标签对应的是大于0的分数的列即标签的数量,记为分数映射权重矩阵
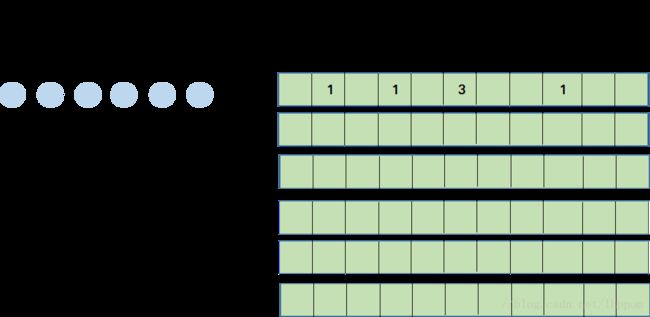
通过这幅图,你可以参考到,如果将左边的样本视为1维的矩阵,和右方权重矩阵进行相乘不便是我们想要的结果吗?单看左边的一个样本i和右边对应的第i行分数映射权重向量,矩阵相乘的结果就是我们想要的样本i对权重矩阵的梯度结果了。哪怕你最后将N个样本补充为D维也不会影响目前的形式。之所以最后能以矩阵相乘的形式运算是因为最后的结果也是各个梯度矩阵叠加。所以构造出右矩阵便能计算到我们的目标梯度矩阵了。
最后的最后还有一个trick,记得之前提到的结构风险期望吗?里面也是有对W进行计算的,只不过是刚好是它自身和自身元素的点乘,求导的结果便是本身乘上2,这个2如果前面定义loss function时加多一个1/2的系数便可以消掉了,这个就不加赘述了。
#gradient
margin[margin>0]=1
margin[margin<=0]=0
row_sum = np.sum(margin, axis=1) # 1 by N
margin[np.arange(num_train), y] = -row_sum # 统计出究竟有几个标签对权重模板矩阵有影响
dW += np.dot(X.T, margin) # D by C
dW/=num_train
dW += reg * W #通过前面的系数消掉了平方求导的系数2