【生成对抗网络 论文泛读】……pix2pix & pix2pixhd……
文章目录
- 前言
- Pix2pix
-
- 简介
- 核心思想
- Pix2pixHD
-
- 升级1
- 升级2
- 升级3
- 升级4
前言
这两篇论文放在一起说。
pix2pix:点我下载
pix2pixhd:点我下载
Pix2pix
论文题目::Image-to-Image Translation with Conditional Adversarial Networks
这是一个条件生成网络,他跟cyclegan不同,cyclegan不需要任何条件,直接将需要的两种数据集喂进去就行了,而这个pix2pix是有条件的,
简介
- 生成器:是一个unet模型,需要 输入的图像+噪声,
- 判别器 :是一个patchgan模型,输入 真图+输入的图 和 生成的假图+输入的图 两组,输出的结果就是,某一对是真还是假的概率,是个二分类模型。
简单回顾一下unet:
一个解决语义鸿沟问题的U字形模型。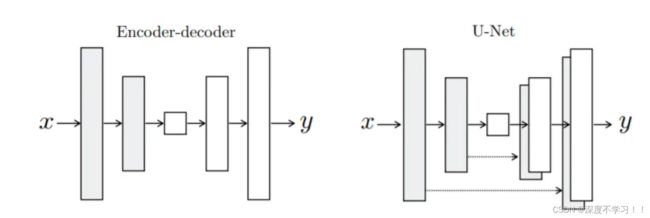
左边是GAN使用的编码及解码器模型,右边就是pix2pix生成器使用的unet模型,他用连接是Densenet里的connect 通道连接,而不是Resnet里的add。
害,其实就是扣小模块,找已有的更牛的小模块代替原来的老旧小模块,性能自然更上一层楼。
patchgan:就是将一张图分成N * N的patch,然后判断每一个patch是真图的概率,最后求平均。
核心思想
看一下论文中给出的这张图:

其实还是GAN的基本思想。
左边输入一个图像X +噪声, 生成器生成一个假图 再加上输入的X喂给判别器,判别器能判断出来是这一对是假图。
右边就是真图y+输入的轮廓图像x,此时判别器能判断出来是真图组合。
所以这里就明白了为什么说这是CGAN 就是条件GAN呢,其实也是迎合了上一篇了论文cyclegan,cyclegan是不需要图像对齐的,而这里是需要的,也就是说你生成器生成出来的图片不仅要具备真实图片的风格,还要和你输入的简笔画x相吻合(像素匹配)。
pix2pix在训练和测试的时候加入了dropout。
最后 pix2pix使用的损失函数是L1 loss,作者通过实验对比了L2和L1,最后选择的L1。
缺点:训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的照片。在这种情况下,自然就没有cycle那种风景照转成名家画作的功能了,毕竟你不能把梵高复活叫他给你画一个对应的照片哈哈。
Pix2pixHD
pix2pixHD是pix2pix的重要升级,末尾加了一个HD,显然就是高清的意思。
几个升级的方向:
升级1
将原来pix2pix的unet生成器 ,升级为多级生成器(coarse-to-fine generator)。
直接看论文中给出的这张图:

这张图作者画成三部分了,实际上当作一个过程来看待比较好理解,从左到右的过程,也可以看成绿色网络的中间嵌入了一个蓝色的网络。
其中 G1表示全局生成网络,输入和输出大小是1024 × 512,G2表示局部增强网络,输入和输出大小是2048 × 1024。
G1还是之前的u-net网络结构,只是去掉了跨层链接。
流程:
图片先经过一个生成器G2 的卷积层进行2倍下采样,然后使用另一个生成器 G1生成低分辨率的图,将得到的结果和刚刚下采样得到的图进行element-wise的相加,然后输出到 G2的后续网络生成高分辨率的图片。
在训练过程中也是先训练分辨率较小的G1,然后再一起训练G1和G2。
好处不言而喻,低分辨率学全局特征,高分辨率学像素级特征,两者结合,效果提升,
升级2
将原来pix2pix的patch GAN判别器 ,升级为多尺度判别器(multi-scale discriminator)。
作者在论文中说到:为了区分高分辨率真实图像和合成的图像,判别器需要有一个非常大的感受野。这就要求一个更深的网络过着更大的卷积核。这些都会增加网络的容量和潜在的过拟合因素。同时,这两种选择都需要更大的内存占用来用于训练,这已经是高分辨率图像生成的稀缺资源了。
所以作者提出了这个多尺度判别器,其实原理就一句话,就是在不同尺度的特征图上,分别训练判别器,最后的结果取平均。
升级3
优化了损失函数
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss

升级4
pix2pix的语义分割对于同类物体的外轮廓区分的不明显,导致多个同一类物体排列在一起的时候出现模糊。所以pix2pixhd使用实例分割的结果进行训练,也就是文中说的Instance-map。
实例分割出来的 Boundary map:
将Boundary map与输入的语义标签concatnate一起作为输入。
这里分割出来之后,论文中所说的实例级别修改就容易达到了。
比如作者在论文开头给出的树和楼之间的转换,车颜色和路面纹理的转换:

大致实现:先通过新增一个encoder网络抽取图像特征,然后对特征做实例级别的均值池化操作,最后将这种池化后的特征和生成器的原输入组合成为新的输入,从而实现实例级别图像多样化,
