NNI优化超参数
文章目录
- 1. NNI简介
- 2. 使用步骤及示例
-
- 2.1 编写程序
- 2.2 设置参数搜索空间
- 2.3 更改源程序
- 2.4 定义配置文件
- 3. 参数空间设置
- 4. 命令行命令
-
- 4.1 创建AutoML
- 4.2 继续AutoML
- 4.3 可视化AutoML
- 5. NNI使用细节
- 6. 调参结果
1. NNI简介
NNI (Neural Network Intelligence) 是微软开源的自动机器学习(AutoML)的工具包。它通过多种调优的算法来搜索最好的神经网络结构和(或)超参,并支持单机、本地多机、云等不同的运行环境。
在其中使用到的基本概念如下:
- Experiment(实验): 表示一次任务,例如,寻找模型的最佳超参组合,或最好的神经网络架构等。它由 Trial 和自动机器学习算法所组成。
- Search Space(搜索空间):是模型调优的范围。 例如,超参的取值范围。
- Configuration(配置):配置是搜索空间的实例化,从搜索空间中固定下来一定的超参数,每个超参都会有特定的值。
- Trial(尝试):是一次独立的尝试,它会使用某组配置(例如,一组超参值,或者特定的神经网络架构)。 Trial 会基于提供的配置来运行。
- Tuner(调优器):一种自动机器学习算法,会为下一个 Trial 生成新的配置。 新的 Trial 会使用这组配置来运行。
- Assessor(评估器):分析 Trial 的中间结果(例如,定期评估数据集上的精度),来确定 Trial 是否应该被提前终止。
- 训练平台:是 Trial 的执行环境。 根据 Experiment 的配置,可以是本机,远程服务器组,或其它大规模训练平台(如OpenPAI,Kubernetes等)。
2. 使用步骤及示例
2.1 编写程序
首先NNI只是一个自动机器学习的工具,作用是调参、神经架构搜索等,即是对已经能够训练出模型的代码文件进行参数的调节,所以,第一步,我们需要先写出能够训练出模型的代码。之后,在这基础上插入NNI的几行代码即可。
这里,我们用我文本分类文章中的程序来做示例,当然,没看过这篇文章的朋友也可以继续看下去,因为改动其实很少的。
2.2 设置参数搜索空间
NNI能够支持TensorFlow、Pytorch等很多的深度学习框架,且兼容性很好,如果需要使用NNI的参数优化,仅需要添加很少的代码,这里,假如我们需要调节的参数只有学习率 learning_rate 以及 训练轮次 epoch,建立一个名为 search_space.json 的JSON文件,文件内容如下:
{
"learning_rate": {"_type":"uniform", "_value": [0.0001, 0.1]},
"num_epochs":{"_type":"choice","_value":[5, 10, 15, 20]}
}
上述文件中,learning_rate,epoch 为需要优化的参数的名称,_type 为参数搜索的策略,比如如果搜索策略为 chioce,那么参数的搜索就会在 _value 的值中选择一个值进行搜索,如果搜索策略为 uniform,那么参数就会在 _value 所属的范围里面按照均匀分布进行参数的选择,更加详细的策略下面会讲。
2.3 更改源程序
原来的程序主函数如下所示。
# 存放数据的文件夹
dataset = 'text_classify_data'
# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random
embedding = 'embedding_SougouNews.npz'
# 需要用到的所有参数
config = Config(dataset, embedding)
# 得到数据的迭代器
vocab, train_data, dev_data, test_data = get_data(config, False)
dataloaders = {
'train': DataLoader(TextDataset(train_data, config), 128, shuffle=True),
'dev': DataLoader(TextDataset(dev_data, config), 128, shuffle=True),
'test': DataLoader(TextDataset(test_data, config), 128, shuffle=True)
}
model = RNNModel(config).to(config.device)
# 训练模型
train_best(config, model, dataloaders)
修改后的代码如下所示:
import nni
# 存放数据的文件夹
dataset = 'text_classify_data'
# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random
embedding = 'embedding_SougouNews.npz'
# 需要用到的所有参数,这里去除了需要优化的learning_rate以及epoch
config = Config(dataset, embedding)
vocab, train_data, dev_data, test_data = get_data(config)
dataloaders = {
'train': DataLoader(TextDataset(train_data, config), config.batch_size, shuffle=True),
'dev': DataLoader(TextDataset(dev_data, config), config.batch_size, shuffle=True),
'test': DataLoader(TextDataset(test_data, config), config.batch_size, shuffle=True)
}
# 传入一组新的需要优化的参数
def main(super_params):
model = RNNModel(config).to(config.device)
# r为返回的测试集的准确率
r = train_best(config, model, dataloaders, super_params)
# 这行代码必须加,意思是NNI根据传入的r的情况进行参数的选取优化
nni.report_final_result(r)
if __name__ == '__main__':
# 初始化需要优化的参数
super_params = {'learning_rate': 0.001, 'num_epochs': 2}
# 从NNI那里拿到一组满足搜索空间定义的参数值
super_params.update(nni.get_next_parameter())
# 传入超参数并开始训练
main(super_params)
大家看出来了,实际上我加的代码只有两行,即nni.report_final_result(r) 以及 super_params.update(nni.get_next_parameter()) 两行,并将需要优化的参数与不需要优化的参数进行了分离而已。
这样,其实就已经完成了NNI在代码中的嵌入,整个过程可以说是很简单了,二关于NNI的其与配置需要在配置文件中进行配置。
2.4 定义配置文件
创建一个名为 config.yml 的配置文件,里面需要编写NNI的各种配置信息,基本配置信息如下:
# 搜索空间的文件所在位置
searchSpaceFile: search_space.json
# 运行文件使用的命令,Linux是 python3 mian.py
trialCommand: python main.py
# 同时运行的trial数量
trialConcurrency: 3
# 最大的trial数量
maxTrialNumber: 100
# 最大的实验时间,当最大时间或者最大trial达到时终止实验
maxExperimentDuration: 1h
# 实验结果文件的存储位置,不能含有中文
experimentWorkingDirectory: "C:\\User\\nni-experiment"
# 使用的调优算法
tuner:
name: TPE
classArgs:
# 需要将传入的参数进行最大化还是最小化,若传入NNI的结果是loss就最小化,是准确率等最大化
optimize_mode: maximize
trainingService:
platform: local
然后切换到对应的Python环境中,使用 nnictl create --config config.yml 命令开始进行参数优化。
3. 参数空间设置
常用的参数空间搜索策略如下所示:
| 参数形式 | 参数意义 |
|---|---|
{"_type": "choice", "_value": [item1,...]} |
从_value 中选取一个值 |
{"_type": "randint", "_value": [lower, upper]} |
从[lower, upper] 中选取一个整数值 |
{"_type": "uniform", "_value": [low, high]} |
变量值在[lower, upper]之间均匀采样 |
{"_type": "quniform", "_value": [low, high, q]} |
变量值在[lower, upper] 且步长为q |
4. 命令行命令
4.1 创建AutoML
使用的是 nnictl create 命令,该命令中支持一些参数,支持的参数如下:
| 全称/缩写 | 是否必须 | 描述 |
|---|---|---|
--config, -c |
是 | yaml配置文件的路径 |
--port, -p |
否 | 启动web服务的端口,默认是8080 |
--foreground, -f |
否 | 将日志文件内容打印到命令行 |
4.2 继续AutoML
使用的是 nnictl resume 命令,该命令中支持一些参数,支持的参数如下:
| 全称/缩写 | 是否必须 | 描述 |
|---|---|---|
id |
是 | 需要继续的实验的ID名 |
--port, -p |
否 | 启动web服务的端口,默认是8080 |
--foreground, -f |
否 | 将日志文件内容打印到命令行 |
--experiment_dir, -e |
否 | 指定继续实验的外部路径 |
4.3 可视化AutoML
使用的是 nnictl view 命令,该命令中支持一些参数,支持的参数如下:
| 全称/缩写 | 是否必须 | 描述 |
|---|---|---|
id |
是 | 需要继续的实验的ID名 |
--port, -p |
否 | 启动web服务的端口,默认是8080 |
--experiment_dir, -e |
否 | 指定继续实验的外部路径 |
5. NNI使用细节
- 在
nni.report_final_result(r)中,传递的参数r必须是基本类型,不能是tensor类型或者pandas类型 - 你的参数应该是个字典,比如
args['batch_size']而非args.batch_size
6. 调参结果
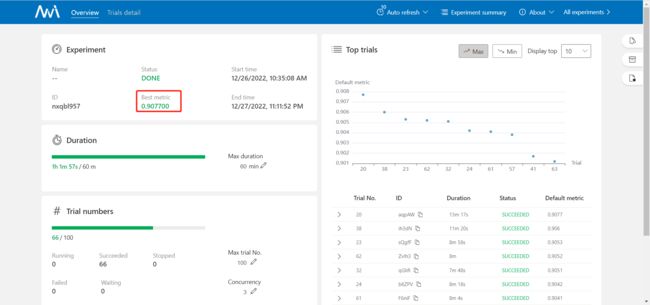
上图展示了最优的结果,以及一些测试的值。
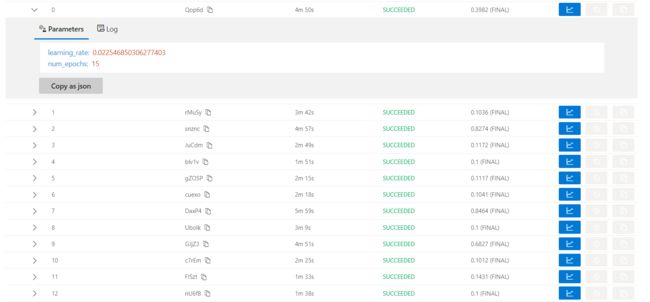
点开每一个trial有每一个trail的详细信息,如参数信息、打印信息、训练信息等。
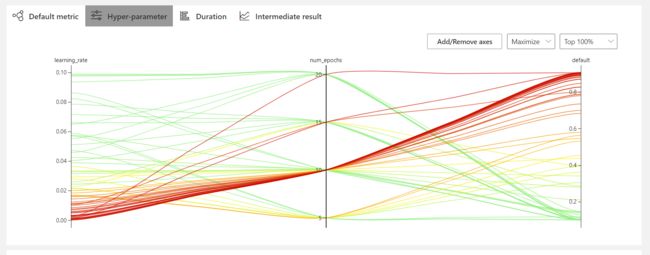
在详细中能够看到超参数之间的关系。