【人工智能笔记】第三十一节:AutoML系列,用NNI框架进行神经网络架构搜索与超参调优(一)
本章节介绍NNI框架的安装,及使用NNI框架进行 神经网络架构搜索 与 超参调优。下面demo基于Tensorflow2.0编写。
NNI简介
NNI (Neural Network Intelligence) 是一个轻量但强大的工具包,帮助用户自动的进行 特征工程,神经网络架构搜索,超参调优 以及 模型压缩。
NNI 管理自动机器学习 (AutoML) 的 Experiment, 调度运行 由调优算法生成的 Trial 任务来找到最好的神经网络架构和/或超参,支持 各种训练环境,如 本机, 远程服务器, OpenPAI, Kubeflow, 基于 K8S 的 FrameworkController(如,AKS 等), DLWorkspace (又称 DLTS), AML (Azure Machine Learning) 以及其它云服务。
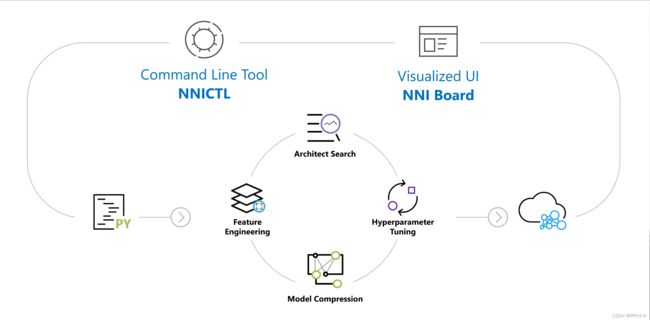
NNI安装
pip install --upgrade nni
NNI的使用Demo
-
Demo文件结构

-
NNI配置文件(./configs/config.yml)
该文件用于配置启动NNI的参数。
# This example shows more configurable fields comparing to the minimal "config.yml"
# You can use "nnictl create --config config_detailed.yml" to launch this experiment.
# If you see an error message saying "port 8080 is used", use "nnictl stop --all" to stop previous experiments.
experimentName: MNIST # An optional name to help you distinguish experiments.
# Hyper-parameter search space can either be configured here or in a seperate file.
# "config.yml" shows how to specify a seperate search space file.
# The common schema of search space is documented here:
# https://nni.readthedocs.io/en/stable/Tutorial/SearchSpaceSpec.html
searchSpaceFile: search_space.json
trialCommand: python demo.py # The command to launch a trial. NOTE: change "python3" to "python" if you are using Windows.
trialCodeDirectory: ../ # The path of trial code. By default it's ".", which means the same directory of this config file.
trialGpuNumber: 1 # How many GPUs should each trial use. CUDA is required when it's greater than zero.
trialConcurrency: 4 # Run 4 trials concurrently.
maxTrialNumber: 10 # Generate at most 10 trials.
maxExperimentDuration: 1h # Stop generating trials after 1 hour.
tuner: # Configure the tuning algorithm.
name: TPE # Supported algorithms: TPE, Random, Anneal, Evolution, GridSearch, GPTuner, PBTTuner, etc.
# Full list: https://nni.readthedocs.io/en/latest/Tuner/BuiltinTuner.html
classArgs: # Algorithm specific arguments. See the tuner's doc for details.
optimize_mode: maximize # "minimize" or "maximize"
# Configure the training platform.
# Supported platforms: local, remote, openpai, aml, kubeflow, kubernetes, adl.
# You can find config template of some platforms in this directory, and others in mnist-pytorch example.
trainingService:
platform: local
useActiveGpu: true # NOTE: Use "true" if you are using an OS with graphical interface (e.g. Windows 10, Ubuntu desktop)
# Reason and details: https://nni.readthedocs.io/en/latest/reference/experiment_config.html#useactivegpu
-
NNI 搜索空间配置文件(./configs/search_space.json)
该文件用于配置超参数选择范围。
“_type”: “choice” 为枚举,"uniform"为一个范围。文件内容:
{
"dropout_rate": { "_type": "uniform", "_value": [0.5, 0.9] },
"conv_size": { "_type": "choice", "_value": [2, 3, 5, 7] },
"hidden_size": { "_type": "choice", "_value": [124, 512, 1024] },
"batch_size": { "_type": "choice", "_value": [16, 32] },
"learning_rate": { "_type": "choice", "_value": [0.0001, 0.001, 0.01, 0.1] },
"layer_type": { "_type": "choice", "_value": ["conv", "dn"] }
}
-
Demo代码(./demo.py)
import tensorflow as tf
import nni
import logging
_logger = logging.getLogger('nni_demo')
_logger.setLevel(logging.INFO)
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only use the first GPU
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
tf.config.experimental.set_visible_devices(gpu, 'GPU')
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPU")
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized
print(e)
class ShareParams():
__params = {}
@classmethod
def __getitem__(self, key):
return ShareParams.__params[key]
@classmethod
def get_params(self) -> dict:
return ShareParams.__params
@classmethod
def set_params(self, **kwargs) -> None:
ShareParams.__params = kwargs
@classmethod
def get_param(self, key, default) -> object:
if key in ShareParams.__params.keys():
return ShareParams.__params[key]
else:
return default
@classmethod
def set_param(self, key, value) -> None:
ShareParams.__params[key] = value
@classmethod
def update_params(self, params) -> None:
ShareParams.__params.update(params)
class DemoLayer(tf.keras.layers.Layer):
'''自定义层'''
def __init__(self):
super(DemoLayer, self).__init__()
# 初始化超参数
share_params = ShareParams()
self.unit = share_params['hidden_size']
self.kernel_size = share_params['conv_size']
self.dorp = share_params['dropout_rate']
self.conv1 = tf.keras.layers.Conv2D(self.unit, kernel_size=self.kernel_size, activation='relu')
self.conv2 = tf.keras.layers.Conv2D(self.unit // 2, kernel_size=1, activation='relu')
self.conv3 = tf.keras.layers.Conv2D(self.unit, kernel_size=self.kernel_size, activation='relu', use_bias=False)
self.bn1 = tf.keras.layers.BatchNormalization()
self.dorpout1 = tf.keras.layers.Dropout(self.dorp)
def call(self, inputs, training, mask=None):
x = inputs
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.bn1(x, training=training)
x = self.dorpout1(x, training=training)
return x
class DemoModel(tf.keras.Model):
'''自定义类'''
def __init__(self):
super(DemoModel, self).__init__()
# 初始化超参数
share_params = ShareParams()
self.layer1 = DemoLayer()
# 动态架构搜索
if share_params['layer_type'] == 'dn':
self.flatten1 = tf.keras.layers.Flatten()
self.dn1 = tf.keras.layers.Dense(10)
elif share_params['layer_type'] == 'conv':
self.conv1 = tf.keras.layers.Conv2D(10, kernel_size=1)
def call(self, inputs, training, mask=None):
x = inputs
x = self.layer1(x, training=training, mask=mask)
# 动态架构搜索
if share_params['layer_type'] == 'dn':
x = self.flatten1(x)
x = self.dn1(x)
elif share_params['layer_type'] == 'conv':
x = self.conv1(x)
x = tf.math.reduce_sum(x, axis=[1,2])
x = tf.math.softmax(x)
return x
class DemoCallback(tf.keras.callbacks.Callback):
'''自定义回调函数'''
def __init__(self):
super(DemoCallback, self).__init__()
def on_epoch_end(self, epoch, logs=None):
"""Reports intermediate accuracy to NNI framework"""
# TensorFlow 2.0 API reference claims the key is `val_acc`, but in fact it's `val_accuracy`
if 'val_acc' in logs:
nni.report_intermediate_result(logs['val_acc'])
else:
nni.report_intermediate_result(logs['val_accuracy'])
if __name__ == '__main__':
# 参数初始值
params = {
'dropout_rate': 0.5,
'conv_size': 5,
'hidden_size': 1024,
'batch_size': 32,
'learning_rate': 1e-4,
'layer_type': 'conv',
}
share_params = ShareParams()
share_params.update_params(params)
# fetch hyper-parameters from HPO tuner
# comment out following two lines to run the code without NNI framework
tuned_params = nni.get_next_parameter()
share_params.update_params(tuned_params)
_logger.info('Hyper-parameters: %s', share_params.get_params())
model = DemoModel()
x = tf.zeros([32,28,28,1], dtype=tf.float32)
o = model(x, training=True)
tf.print('o:', tf.shape(o))
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = tf.cast(x_train[..., tf.newaxis], dtype=tf.float32)
y_train = tf.one_hot(y_train, 10)
x_test = tf.cast(x_test[..., tf.newaxis], dtype=tf.float32)
y_test = tf.one_hot(y_test, 10)
optimizer = tf.keras.optimizers.Adam(learning_rate=share_params['learning_rate'])
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(
x_train, y_train,
batch_size=share_params['batch_size'],
steps_per_epoch=100,
epochs=5,
verbose=1,
callbacks=[DemoCallback()],
validation_data=(x_test, y_test)
)
loss, accuracy = model.evaluate(x_test, y_test, verbose=1)
nni.report_final_result(accuracy) # send final accuracy to NNI tuner and web UI
-
NNI 启动
服务启动后,可以访问 http://127.0.0.1:8080
nnictl create -c .\configs\config.yml

页面效果如下:


-
NNI 停止
nnictl stop
-
Windows下可能遇到的问题
- 在调用GPU时,gpu_metrics文件缺失,可以执行 C:\Users{用户名}\AppData\Local\Temp{用户名}\nni\script\gpu_metrics_collector.ps1 生成。
参考资料:
- NNI源码地址:https://github.com/microsoft/nni
- NNI中文文档:https://nni.readthedocs.io/zh/stable/