ICCV 2021可逆的跨空间映射实现多样化的图像风格传输:Diverse Image Style Transfer via Invertible Cross-Space Mapping
Diverse Image Style Transfer via Invertible Cross-Space Mapping
Haibo Chen, Lei Zhao∗ , Huiming Zhang, Zhizhong Wang Zhiwen Zuo, Ailin Li, Wei Xing∗ , Dongming Lu
College of Computer Science and Technology, Zhejiang University
[paper]
目录
Abstract
1. Introduction
3. Approach
3.1. Stylization Branch
3.2. Disentanglement Branch
3.3. Inverse Branch
3.4. Final Objective and Network Architectures
4. Experiments
5. Conclusion
Abstract
Image style transfer aims to transfer the styles of artworks onto arbitrary photographs to create novel artistic images.
Although style transfer is inherently an underdetermined problem, existing approaches usually assume a deterministic solution, thus failing to capture the full distribution of possible outputs.
To address this limitation, we propose a Diverse Image Style Transfer (DIST) framework which achieves significant diversity by enforcing an invertible cross-space mapping.
Specifically, the framework consists of three branches: disentanglement branch, inverse branch, and stylization branch. Among them, the disentanglement branch factorizes artworks into content space and style space; the inverse branch encourages the invertible mapping between the latent space of input noise vectors and the style space of generated artistic images; the stylization branch renders the input content image with the style of an artist. Armed with these three branches, our approach is able to synthesize significantly diverse stylized images without loss of quality.
We conduct extensive experiments and comparisons to evaluate our approach qualitatively and quantitatively. The experimental results demonstrate the effectiveness of our method.
研究方向:
图像风格转换的目的是将艺术作品的风格转换到任意的照片上,创造新颖的艺术形象。
提出本文要解决的核心问题:
虽然风格转移本质上是一个不确定的问题,但现有的方法通常假设一个确定的解决方案,因此无法捕获可能的输出的完整分布。
本文主要的研究方法:
为了解决这一限制,本文提出了一个多样化的图像风格传输 (DIST) 框架,该框架通过强制一个可逆的跨空间映射实现了显著的多样性。
研究方法的具体介绍:
具体来说,框架由三个分支组成:解耦分支、逆分支和风格化分支。其中,解耦分支将艺术品分解为内容空间和风格空间;逆分支鼓励输入噪声向量的潜在空间与生成的艺术图像的风格空间之间的可逆映射;风格化分支以艺术家的风格呈现输入内容图像。有了这三个分支,本文的方法能够合成出显著不同的风格化图像而不损失质量。
实验结论:
本文进行了广泛的实验和比较,从质量和数量上评价我们的方法。实验结果证明了该方法的有效性。
1. Introduction
An exquisite artwork can take a diligent artist days or even months to create, which is labor-intensive and timeconsuming. Motivated by this, a series of recent approaches studied the problem of repainting an existing photograph with the style of an artist using either a single artwork or a collection of artworks. These approaches are known as style transfer. Armed with style transfer techniques, anyone could create artistic images.
本文研究对象:风格迁移之艺术图像生成
一件精美的艺术品可能需要一个勤奋的艺术家几天甚至几个月的时间来创作,这是劳动密集型和时间消耗。受此启发,一系列最近的研究方法研究了用艺术家的风格重新绘制现有照片的问题,无论是使用单一的艺术作品还是收藏的艺术作品。这些方法被称为风格转换。有了风格转换技术,任何人都可以创造艺术图像。
How to represent the content and style of an image is the key challenge of style transfer. Recently, the seminal work of Gatys et al. [7] firstly proposed to extract content and style features from an image using pre-trained Deep Convolutional Neural Networks (DCNNs). By separating and recombining contents and styles of arbitrary images, novel artworks can be created. This work showed the enormous potential of CNNs in style transfer and created a surge of interest in this field. Based on this work, a series of subsequent methods have been proposed to achieve better performance in many aspects, including efficiency [13, 21, 34], quality [20, 35, 40, 43, 39, 4], and generalization [6, 5, 10, 24, 30, 27, 22]. However, diversity, as another important aspect, has received relatively less attention.
研究背景及问题引出:
如何表现图像的内容和风格是风格转换的关键挑战。最近,Gatys et al. [7] 的开创性工作首先提出使用预训练的深度卷积神经网络 (Deep Convolutional Neural Networks, DCNNs) 从图像中提取内容和风格特征。通过对任意图像的内容和风格进行分离和重组,可以创作出新颖的艺术品。这项工作显示了 cnn 在风格转换方面的巨大潜力,并引发了人们对这一领域的兴趣激增。在此基础上,又提出了一系列后续的方法,以期在效率 [13,21,34]、质量 [20,35,40,43,39,4] 和泛化[6,5,10,24,30,27,22] 等多个方面取得更好的性能。然而,作为另一个重要方面,多样性受到的关注相对较少。
As the saying goes, “There are a thousand Hamlets in a thousand people’s eyes”. Similarly, different people have different understanding and interpretation of the style of an artwork. There is no uniform and quantitative definition of the artistic style of an image. Therefore, the stylization results should be diverse rather than unique, so that the preferences of different people can be satisfied. To put it another way, style transfer is an underdetermined problem, where a large number of solutions can be found. Unfortunately, existing style transfer methods usually assume a deterministic solution. As a result, they fail to capture the full distribution of possible outputs.
动机:用很站得住的理由解释动机,让动机更合理,更自然
俗话说,“一千个人眼中有一千个哈姆雷特”。同样,不同的人对一件艺术品的风格也有不同的理解和解读。一个形象的艺术风格没有统一的、定量的定义。因此,风格化的结果应该是多样化的,而不是独一无二的,这样才能满足不同人的偏好。换句话说,风格转移是一个未确定的问题,可以找到大量的解决方案。不幸的是,现有的样式转换方法通常采用确定性的解决方案。因此,它们无法捕获可能输出的全部分布。
A straightforward approach to handle diversity in style transfer is to take random noise vectors along with content images as inputs, i.e., utilizing the variability of the input noise vectors to produce diverse stylization results. However, the network tends to pay more attention to the high-dimensional and structured content images and ignores the noise vectors, leading to deterministic output. To ensure that the variability in the latent space can be passed into the image space, Ulyanov et al. [35] enforced the dissimilarity among generated images by enlarging their distance in the pixel space. Similarly, Li et al. [23] introduced a diversity loss that penalized the feature similarities of different samples in a mini-batch. Although these methods can achieve diversity to some extent, they have obvious limitations.
First, forcibly enlarging the distance among outputs may cause the results to deviate from the local optimum, resulting in the degradation of image quality.
Second, to avoid introducing too many artifacts to the generated images, the weight of the diversity loss is generally set to a small value. Consequently, the diversity of the stylization results is relatively limited.
Third, diversity is more than the pixel distance or feature distance among generated images, which contains richer and more complex connotation. Most recently, Wang et al. [37] achieved better diversity by using an orthogonal noise matrix to perturb the image feature maps while keeping the original style information unchanged. However, this approach is apt to generate distorted results, providing insufficient visual quality. Therefore, the problem of diverse style transfer remains an open challenge.
技术难题:对问题更细致、更深入的探讨
处理风格转换多样性的一种简单方法是将随机噪声向量与内容图像一起作为输入,即利用输入噪声向量的可变性来产生多样化的程式化结果。然而,该网络更倾向于关注高维和结构化内容图像,而忽略噪声向量,导致输出的确定性。为了保证潜在空间中的可变性可以传递到图像空间,Ulyanov et al. [35] 通过增大像素空间中的距离来增强生成图像之间的不相似性。类似地,Li et al. [23] 引入了多样性损失,惩罚了小批量中不同样品的特征相似性。这些方法虽然能在一定程度上实现多样性,但也存在明显的局限性。
首先,强行增大输出之间的距离可能会导致结果偏离局部最优,导致图像质量下降。
其次,为了避免在生成的图像中引入过多的伪影,一般将多样性损失的权重设置为一个较小的值。因此,风格化结果的多样性相对有限。
第三,多样性不仅仅是生成图像之间的像素距离或特征距离,它包含更丰富、更复杂的内涵。最近,Wang et al. [37] 在保持原始风格信息不变的情况下,利用正交噪声矩阵扰动图像特征映射,获得了更好的多样性。然而,这种方法容易产生失真的结果,产生不理想的视觉质量。
因此,多元化的风格转换问题仍然是一个开放的挑战。
In this paper, we propose a Diverse Image Style Transfer (DIST) framework which achieves significant diversity without loss of quality by enforcing an invertible crossspace mapping. Specifically, the framework takes random noise vectors along with everyday photographs as its inputs, where the former are responsible for style variations and the latter determine the main contents. However, according to above analyses, we can learn that the noise vectors are prone to be ignored in the network. Our proposed DIST framework tackles this problem through three branches: disentanglement branch, inverse branch, and stylization branch.
The disentanglement branch factorizes artworks into content space and style space. The inverse branch encourages the invertible mapping between the latent space of input noise vectors and the style space of generated artistic images, which is inspired by [32]. But different from [32], we invert the style information rather than the whole generated image to the input noise vector, since the input noise vector mainly influences the style of the generated image. The stylization branch renders the input content image with the style of an artist. Equipped with these three branches, DIST is able to synthesize significantly diverse stylized images without loss of quality, as shown in Figure 1.
本文提出了一个多样化的图像风格传输 (DIST) 框架,通过强制一个可逆的跨空间映射来实现显著的多样性而不损失质量。具体来说,框架将随机噪声向量和日常照片作为输入,前者负责风格变化,后者决定主要内容。但是,通过以上分析,可以了解到噪声向量在网络中很容易被忽略。本文提出的 DIST 框架通过三个分支来解决这个问题:解纠缠分支、逆分支和风格化分支。
解构分支将艺术品分解为内容空间和风格空间。
逆分支鼓励输入噪声向量的潜在空间与生成的艺术图像的风格空间之间的可逆映射,其灵感来自 [32]。但与 [32] 不同的是,由于输入噪声矢量主要影响生成图像的风格,所以本文将风格信息而不是生成的整个图像转换为输入噪声矢量。
风格化分支以艺术家的风格呈现输入内容图像。
配备了这三个分支,DIST 能够合成出明显不同的风格化图像而不降低图像质量,如图 1 所示。
Overall, the contributions can be summarized as follows:
• We propose a novel style transfer framework which achieves significant diversity by learning the one-toone mapping between latent space and style space.
• Different from existing style transfer methods [35, 23, 37] that obtain diversity with serious degradation of quality, our approach can produce both high-quality and diverse stylization results.
• Our approach provides a new way to disentangle the style and content of an image.
• We demonstrate the effectiveness and superiority of our approach by extensive comparison with several state-of-the-art style transfer methods.
总的来说,这些贡献可总结如下:
• 通过学习潜在空间和风格空间之间的一对一映射,提出了一种新的风格迁移框架,实现了显著的多样性。
• 与现有的风格转移方法 [35,23,37] 获得多样性而质量严重退化不同,本文的方法可以产生高质量和多样化的风格化结果。
• 本文的方法提供了一种新的方法来理清图像的风格和内容。
• 通过与几种最先进的风格转换方法的广泛比较,证明了本文的方法的有效性和优越性。
【贡献总结略显简单】
3. Approach
Inspired by [29, 17, 18, 33], we learn artistic style not from a single artwork but from a collection of related artworks. Formally, our task can be described as follows: given a collection of photos x ∼ X and a collection of artworks y ∼ Y (the contents of X and Y can be totally different), we aim to learn a style transformation G : X → Y with significant diversity. To achieve this goal, we propose a DIST framework consisting of three branches: stylization branch, disentanglement branch, and inverse branch. In this section, we introduce the three branches in details.
受 [29,17,18,33] 的启发,学习艺术风格不是从单一的艺术品,而是从相关艺术品的集合。形式上,本文的任务可以这样描述:给定一组照片 x ~ X 和一组艺术品 y ~ Y (x 和 y 的内容可以完全不同),本文的目标是学习具有显著多样性的风格转变 G: X→Y。为了实现这一目标,本文提出了一个由三个分支组成的 DIST 框架:风格化分支、解耦分支和逆分支。
3.1. Stylization Branch
The stylization branch aims to repaint x ∼ X with the style of y ∼ Y . To this end, we enable G to approximate the distribution of Y by employing a discriminator D to train against G: G tries to generate images that resembles the images in Y , while D tries to distinguish the stylized images from the real ones. Joint training of these two networks leads to a generator that is able to produce desired stylizations. This process can be formulated as follows (note that for G, we adopt an encoder-decoder architecture consisting of an encoder Ec and a decoder D) :
(1)
where z ∈ R dz is a random noise vector and p(z) is the standard normal distribution N (0, I). We leverage its variability to encourage diversity in generated images.
风格化分支
风格化分支的目标是用 y ~ Y 的风格重新绘制 x ~ X。为此,本文使用判别器器 D 对 G 进行训练,使 G 能够近似 Y 的分布: G 试图生成与 Y 中的图像相似的图像,而 D 试图将程式化的图像与真实的图像区分开来。对这两个网络的联合训练将产生一个能够产生所需程式化的生成器。这个过程可以表述如下 (注意对于 G,本文采用编码器 Ec 和解码器 D 组成的编解码器体系结构),如公式(1)。
其中 z∈rdz 是一个随机噪声向量,p(z) 是标准正态分布 N (0, I)。本文利用它的可变性来鼓励生成图像的多样性。
Only using above adversarial loss cannot preserve the content information of x in the generated image, which does not meet the requirements of style transfer. The simplest solution is to utilize a pixel-wise loss between the content image x ∼ X and stylized image D(Ec(x), z). However, this loss is too strict and harms the quality of the stylized image. Therefore, we soften the constraint: instead of directly calculating the distance between original images, we first input them into an average pooling layer P and then calculate the distance between them. We express this content structure loss as:
(2)
Compared with the pixel-wise loss which requires the content image and the stylized image to be exactly the same, Lp measures their difference in a more coarse-grained manner and only requires them to be similar in general content structures, more consistent with the goal of style transfer.
Although the stylization branch is sufficient to obtain remarkable stylized images, it can only produce a deterministic stylized image without diversity, because the network tends to ignore the random noise vector z.
仅使用上述对抗性损失无法保留生成图像中 x 的内容信息,不满足风格转移的要求。最简单的解决方案是利用内容图像 x ~ X 和风格化图像 D(Ec(x), z) 之间的像素损失。然而,这种损失太过严格,损害了风格化图像的质量。因此,本文软化约束:本文不是直接计算原始图像之间的距离,而是首先将它们输入到平均池化层 P 中,然后计算它们之间的距离。本文将这种内容结构损失表示为公式(2)。
与要求内容图像和风格化图像完全相同的像素损失相比,Lp 以更粗粒度的方式衡量它们的差异,只要求它们在一般内容结构上相似,更符合风格转移的目标。
虽然风格化分支足以获得显著的风格化图像,但由于网络倾向于忽略随机噪声向量 z,只能产生确定性的风格化图像,没有多样性。
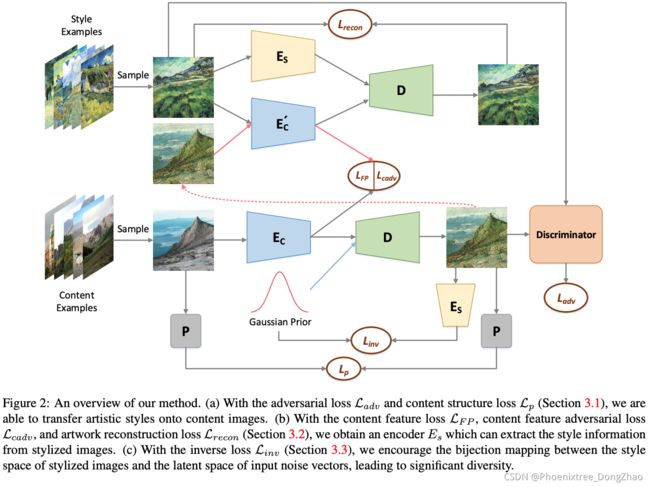
3.2. Disentanglement Branch
[32] alleviated the mode collapse issue in GANs by enforcing the bijection mapping between the input noise vectors and generated images. Different from [32], which only takes noise vectors as inputs, our model takes noise vectors along with content images as inputs, where the former are responsible for style variations and the latter determine the main contents. Therefore, in the inverse process, instead of inverting the whole generated image to the input noise vector like [32] does, we invert the style information of the stylized image to the input noise vector (details in Section 3.3). To be specific, we utilize a style encoder to extract the style information from the stylized image, and enforce the consistency between the style encoder’s output and the input noise vector. The main problem now is how to obtain such a style encoder. We resolve this problem through the disentanglement branch.
解释为什么需要解耦分支:
[32] 通过加强输入噪声向量与生成图像之间的双射映射,缓解了 GAN 中的模式坍缩问题。与 [32] 只使用噪声向量作为输入不同,本文的模型将噪声向量与内容图像一起作为输入,前者负责风格变化,后者决定主要内容。因此,在反过程中,本文不像 [32] 那样将整个生成的图像反到输入噪声向量,而是将风格化图像的样式信息反到输入噪声向量 (详见第3.3节)。具体来说,本文利用样式编码器从风格化图像中提取样式信息,并加强样式编码器输出与输入噪声向量之间的一致性。现在的主要问题是如何获得这样的样式编码器。本文通过解耦分支来解决这个问题。
First, the disentanglement branch employs an encoder E ′ c which takes the stylized image D(Ec(x), z) as input. Given that the content image and stylized image share the same content and differ greatly in style, if we encourage the similarity between the output of Ec (whose input is the content image) and that of E ′ c (whose input is the stylized image), Ec and E ′ c shall extract the shared content information and neglect the specific style information. Notice that Ec and E ′ c are two independent networks and do not share weights. This is because there are some differences when extracting photographs’ contents and artworks’ contents. We define the corresponding content feature loss as,
(3)
首先,解耦分支采用编码器 E ' c,以风格化图像 D(Ec(x), z) 作为输入。鉴于内容图像和风格化图像共享相同的内容和风格有很大的不同,如果鼓励 Ec 的输出之间的相似性 (其输入内容图像) 和E’c (其输入是程式化的形象), Ec 和 E’c 应提取共享内容信息和忽视具体样式信息。注意,Ec 和 E ’c 是两个独立的网络,不共享权值。这是因为在提取照片内容和艺术品内容时存在一些差异。本文将相应的内容特征损失定义为公式(3)。
However, L_FP may encourage Ec and E ′ c to output feature maps in which the value of each element is pretty small (i.e., ∥ Ec(x) ∥→ 0, ∥ E ′ c (D(Ec(x), z)) ∥→ 0). In such a circumstance, although L_FP is minimized, the similarity between Ec(x) and E ′ c (D(Ec(x), z)) is not increased. To alleviate this problem, we employ a feature discriminator Df and introduce a content feature adversarial loss,
(4)
L_cadv measures the distribution deviation, less sensitive to the value of its input in comparison with L_FP . In addition, Lcadv together with L_FP can promote the similarity in two dimensions, further improving the performance.
然而,L_FP 可能鼓励 Ec 和 E ' c 输出特征图中每个元素的值是很小的 (也就是说,∥Ec (x)∥→0,∥E ' c (D (Ec (x), z))∥→0)。在这种情况下,尽管如果 P 是最小化,Ec (x) 之间的相似性和 Ec (D (Ec (x), z)) 不增加。为了缓解这个问题,本文使用了特征判别器 Df,并引入了内容特征对抗损失,即公式 (4)。
L_cadv 测量的是分布偏差,与 L_FP 相比,L_cadv 对其输入值的敏感性较小。此外,L_cadv 与 L_FP一起可以促进两个维度的相似性,进一步提高性能。
Then the disentanglement branch adopts another encoder Es together with the content encoder E ′ c and the decoder D to reconstruct the artistic image. Since E ′ c is constrained to extract the content information, Es has to extract the style information to reconstruct the artistic image. Therefore, we get our desired style encoder Es. We formulate the reconstruction loss as,
(5)
然后解耦分支采用另一个编码器 Es,再加上内容编码器 E’c 和解码器 D 来重构艺术图像。由于 E ' c 被约束提取内容信息,Es 必须提取风格信息来重建艺术形象。因此,本文得到所需的样式编码器 Es。本文将重建损失定义为公式(5)。
3.3. Inverse Branch
Armed with the style encoder Es, we can access the style space of artistic images. To achieve diversity, the inverse branch enforces the one-to-one mapping between latent space and style space by employing the inverse loss,
(6)
The inverse loss ensures that the style information of the generated image D(Ec(x), z) can be inverted to the corresponding noise vector z, which implies that D(Ec(x), z) retains the influence and variability of z. In this way, we can get diverse stylization results by randomly sampling different z from the standard normal distribution N (0, I).
借助风格编码器 Es,可以进入艺术形象的风格空间。为了实现分集,逆分支利用逆损失,强制潜在空间和风格空间之间的一对一映射,如果公式 (6)。
逆损失确保样式信息生成的图像 D (Ec (x), z) 可以倒到相应的噪声向量 z,这意味着 D (Ec (x), z) 保留 z 的影响和变化。通过这种方式,本文可以得到不同的格式化结果由标准正态分布 N(0, 1) 随机抽样不同 z。
3.4. Final Objective and Network Architectures
Figure 2 illustrates the full pipeline of our approach. We summarize all aforementioned losses and obtain the compound loss,
where the hyper-parameters λadv, λp, λfp, λcadv, λrecon, and λinv control the importance of each term. We use the compound loss as the final objective to train our model.
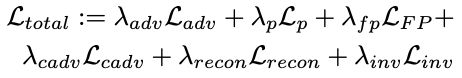
图 2 说明了本文方法的完整 pipeline。将上述损失汇总,得出复合损失。
其中超参数 λadv、λp、λfp、λcadv、λrecon、λinv 控制各项的重要性。本文将复合损耗作为训练模型的最终目标。
Network Architectures
We build on the recent AST backbone [29], and extend it with our proposed changes to produce diverse stylization results. Specifically, the content encoder Ec and E ′ c have the same architecture and are composed of five convolution layers. The style encoder Es includes five convolution layers, a global average pooling layer, and a fully connected (FC) layer. Similar to [15], our decoder D has two branches. One branch takes the content image x as input, containing nine residual blocks [9], four upsampling blocks, and one convolution layer. Another branch takes the noise vector z as input (notice that at inference time, we can take either z or the style code Es(y) extracted from a reference image y as its input), containing one FC layer to produce a set of affine parameters γ, β. Then the two branches are combined through AdaIN [10],
where a is the activation of the previous convolutional layer in branch one, µ and σ are channel-wise mean and standard deviation, respectively. The image discriminator D is a fully convolutional network with seven convolution layers. The feature discriminator Df consists of three convolution layers and one FC layer. As for P, it is an average pooling layer. The loss weights are set to λadv = 2, λp = 150, λfp = 100, λcadv = 10, λrecon = 200, and λinv = 600. We use the Adam optimizer with a learning rate of 0.0002.
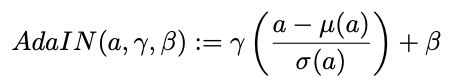
本文的网络构建在最近的 AST baseline [29] 上,并使用提出的更改对其进行扩展,以产生不同的样式化结果。
[29] A style-aware content loss for real-time hd style transfer. ECCV 2018.
具体来说,内容编码器 Ec 和 E ' c 具有相同的架构,由 5 个卷积层组成。
风格编码器 Es 包括 5 个卷积层、全局平均池化层和完全连接 (FC) 层。
解码器 D 有两个分支。一个分支以内容图像 x 为输入,包含 9 个残差 block,4 个上采样 block 和 1 个卷积层。另一个分支将噪声向量 z 作为输入 (注意,在推断时,可以将 z 或从参考图像 y 中提取的样式代码 Es(y) 作为输入),包含一个 FC 层以产生一组仿射参数 γ, β。
然后两个分支通过 AdaIN 合并,如上式,式中,a 为分支1上一层卷积层的激活,µ 和 σ 分别为通道均值和标准差。
图像判别器 D 是一个具有 7 层卷积层的全卷积网络。特征鉴别器 Df 由 3 个卷积层和 1 个 FC 层组成。P 是一个平均的池化层。
损失权重设置为: λadv = 2, λp = 150, λfp = 100, λcadv = 10, λrecon = 200, λinv = 600。我们使用 Adam 优化器,学习率为 0.0002。
4. Experiments
Dataset
Like [29, 17, 18, 33], we take Places365 [45] as the content dataset and Wikiart [14] as the style dataset (concretely, we collect hundreds of artworks for each artist from WikiArt and train a separate model for him/her). Training images were randomly cropped and resized to 768×768 resolutions.
本文将 Places365 [GitHub][官网] 作为内容集,Wikiart [14] 作为风格集 (具体来说,从 Wikiart 为每个艺术家收集数百件艺术品,并为他/她训练一个单独的模型)。训练图像被随机裁剪并调整为 768×768 分辨率。
Baselines
We take the following methods that can produce diversity as our baselines: Gatys et al. [7], Li et al. [23], Ulyanov et al. [35], DFP [37], and MUNIT [11]. Apart from above methods, we also compare with AST [29] and Svoboda et al. [33] to make the experiments more sufficient. Note that we use their officially released codes and default settings of hyper-parameters for experiments.
我们采用以下能够产生多样性的方法作为我们的基线:Gatys et al. [7], Li et al. [23], Ulyanov et al. [35], DFP[37],和MUNIT[11]。除上述方法外,我们还与AST[29]和Svoboda et al.[33]进行了比较,使实验更加充分。请注意,我们使用他们官方发布的代码和默认超参数的实验设置。
[7] Image style transfer using convolutional neural networks. CVPR 2016.
[11] Multimodal unsupervised image-to-image translation. ECCV 2018.
[23] Diversified texture synthesis with feed-forward networks. CVPR 2017.
[29] A style-aware content loss for real-time hd style transfer. ECCV 2018.
[33] Two-stage peer-regularized feature recombination for arbitrary image style transfer. CVPR 2020. GitHub
[35] Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. CVPR 2017.
[37] Diversified arbitrary style transfer via deep feature perturbation. CVPR 2020. GitHub
实验结果展示


5. Conclusion
In this paper, we propose a Diverse Image Style Transfer (DIST) framework which achieves significant diversity without loss of quality by encouraging the one-to-one mapping between the latent space of input noise vectors and the style space of generated artistic images. The framework consists of three branches, where the stylization branch is responsible for stylizing the content image, and the other two branches (i.e., the disentanglement branch and the inverse branch) are responsible for diversity. Our extensive experimental results demonstrate the effectiveness and superiority of our method. In the future work, we would like to extend our method to other tasks, such as text-to-image synthesis and image inpainting.
在本文中,本文提出了一个多样化的图像风格转换 (DIST) 框架,通过鼓励输入噪声向量的潜在空间和生成的艺术图像的风格空间之间的一对一映射,实现了显著的多样性而不损失质量。框架由三个分支组成,其中程式化分支负责程式化内容图像,其他两个分支 (即耦分支和逆分支) 负责多样性。大量的实验结果证明了该方法的有效性和优越性。在未来的工作中,希望将本文的方法扩展到其他任务,如文本到图像的合成和图像的填充。