空间分析(二)——统计进阶
空间分析(二)——统计进阶
- 格局分析
-
- Join count统计
- Lacunarity analysis
- Centrography 点模式分析
-
- 密度分析
- 方位分析
-
- 中心位置
- 标准差椭圆
- 属性分析
- 其它
- 完全空间随机性(Compete Spatial Randomness -CSR)
- 点过程的协变量效应
- 趋势分析
-
- 线性趋势
- 单调趋势
- 随机性和断点检验
-
- 随机性检验
- 突变点检测
- 空间插值
- 描述统计量
-
- 距离与相似性
- 多样性
- 不均衡系数
- 混淆矩阵相关内容
-
- Kappa系数
- F F F Score
- ROC曲线
格局分析
Join count统计
当空间随机变量是类型变量的时候,用Join-count方法来计算空间自相关,即评价空间离散/聚集程度。
Join-count是全局统计方法
-
理论依据:
考虑只有两种类型的变量,绿色出现的概率为 P 1 P_1 P1,则白色出现的概率为 1 − P 1 1-P_1 1−P1
绿绿连在一起的概率: P G G = P 1 P 1 = P 1 2 P_{GG}=P_1 P_1=P_1^2 PGG=P1P1=P12
白白连在一起的概率: P W W = ( 1 − P 1 ) ( 1 − P 1 ) = ( 1 − P 1 ) 2 P_{W W}=\left(1-P_1\right)\left(1-P_1\right)=\left(1-P_1\right)^2 PWW=(1−P1)(1−P1)=(1−P1)2
白绿交叉出现的概率: P G W = P B ( 1 − P 1 ) + ( 1 − P 1 ) P 1 = 2 P 1 ( 1 − P 1 ) P_{G W}=P_B\left(1-P_1\right)+\left(1-P_1\right) P_1=2 P_1\left(1-P_1\right) PGW=PB(1−P1)+(1−P1)P1=2P1(1−P1)
理论随机值: 概率乘上邻接矩阵并加权求和,得到的结果即为在随机情况下这表现出某种关系的单元在空间中出现的期望。
E = 1 2 ∑ i ∑ j w i j P {E}=\frac{1}{2} \sum_i \sum_j w_{i j} P E=21∑i∑jwijP实际值: G G = 1 2 ∑ i ∑ j w i j y i y j GG=\frac{1}{2} \sum_i \sum_j w_{i j} y_i y_j GG=21∑i∑jwijyiyj (Green)
y j y_j yj:为绿色时记为 1,为白色时记为 0。然后通过Z-Scores检验实际值是否显著高于/低于随机下的期望值,从而来判断是否存在空间自相关。

Lacunarity analysis
定义: 孔隙分析是一种描述空间离散模式的多尺度方法。用来判别与空间纹理相关的对象的分布模式,计算结果具有尺度依赖性。
基本思想: 利用 ”gliding box” 扫描目标研究区域,并计算 Lacunarity统计量,然后通过分析Lacunarity统计量随之gliding box大小的变化情况,得出研究区某随机变量的空间分布随着观测尺度变化的特征。
Lacunarity统计量:
r r r:box的大小(观测尺度);
s s s:box里变量的数目
n ( s , r ) n(s,r) n(s,r):frequency distribution of the box masses(计数序列)
N ( r ) N(r) N(r):total number of boxes of size r r r(总数)
Q ( s , r ) Q(s,r) Q(s,r): = n ( s , r ) / N ( r ) =n(s,r) / N(r) =n(s,r)/N(r),概率分布
该分布的一阶和二阶原点矩:
Z ( 1 ) = Σ s Q ( s , r ) Z(1)=\Sigma s Q(s, r) Z(1)=ΣsQ(s,r),=均值: s ˉ ( r ) \bar{s}(r) sˉ(r)
Z ( 2 ) = Σ s 2 Q ( s , r ) Z(2)=\Sigma s^2 Q(s, r) Z(2)=Σs2Q(s,r),=方差+均值平方: s s 2 ( r ) + s ˉ 2 ( r ) s_s^2(r)+\bar{s}^2(r) ss2(r)+sˉ2(r)
根据上述内容,将Lacunarity统计量定义为:
Λ ( r ) = s s 2 ( r ) / s ˉ 2 ( r ) + 1 \Lambda(r)=s_s^2(r) / \bar{s}^2(r)+1 Λ(r)=ss2(r)/sˉ2(r)+1
解释:
当窗口 r r r 的大小固定时,分布的越聚集(sparse),方差越大,均值越小,Lacunarity值越大。所以,越高的值意味着越强的聚集效应存在。
观测尺度增大,或是观测对象的聚集程度减少,Lacunarity降低,极值趋向1
与随机模式下的尺度-值的变化相比,得出是否存在特殊的分布模式,以及是否显著的结论

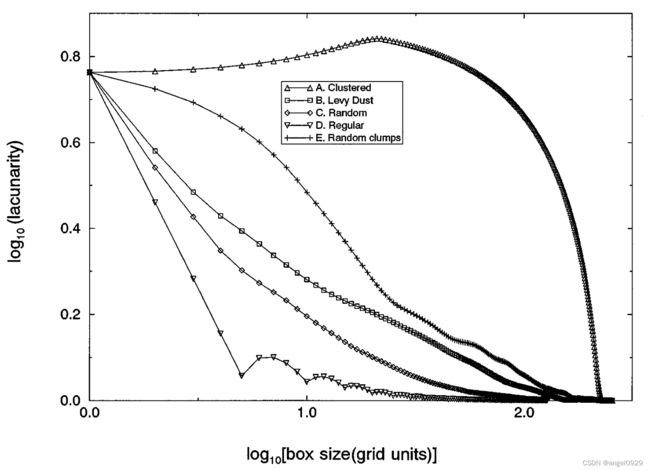
Set A: 当box远远小于序列长度(M)的时候,大部分的box要么被元素完全充满,要不然是全空状态。所以方差很大,Lacunarity值很大。当box大小达到聚集块的大小时,Lacunarity值快速下降。
Set D: 完全均匀分布的状态,元素之间的间隔固定,大小为M/S,所以每一个box中的元素数目 s s s 的值是恒定的。所以方差趋于0,同时,当box的大小超过M/S时,Lacunarity的值趋于1。
Set C: 随机分布形成了一个向上的凹曲线,在box大小很小时急剧下降。在box变大后方差趋于平稳,Lacunarity值平稳下降。这是因为随机模式在更大范围内具有统计不变性。
Set B: Levy dust的值在所有box的情况下都高于随机序列。是因为它具有层次聚集性(hierarchically clumped)<我理解的是在一定的尺度下,Levy dust分布呈现聚集>。这种分布又被称为分形分布(fractal distribution)
Set E: 曲缓慢下降到约Lacunarity值约为0.6的点,这一点对应的box size与聚集块的大小相近。之后曲线迅速下降,曲线走势与随机分布模式相似。
Centrography 点模式分析
点分析的内容:
- 点的数量,多少
- 点的疏密,分布是均匀、随机、聚集?
- 点的方位,点分布的方向和范围
- 点的属性:有哪些性质
- 其它:如动态变化等
密度分析
-
分布密度:
λ ^ = n a = # ( S ∈ A ) a \hat{\lambda}=\frac{n}{a}=\frac{\#(S \in A)}{a} λ^=an=a#(S∈A)
n n n 为选定尺度下分布对象的计量; a a a 为分布区域的计量。 -
样方分析
该方法通过检查其密度(每个样方的点数)在空间上的变化来评估点分布。
步骤:
(1)将研究区域划分为规则的正方形格网
(2)统计待评价模式下各样方中的点数目,得到相应的频率分布
(3)将该频率分布与已知模式(通常是构造得到的随机分布)的频率分布进行比较,来待评价的模式与随机模式相比是更分散还是更聚集。用 χ 2 \chi^2 χ2检验法对这些数据进行估计,其公式表示为: χ 2 = ∑ ( Q − E ) 2 / E \chi^2=\sum(Q-E)^2 / E χ2=∑(Q−E)2/E
Q Q Q为每个样方中实际点数量; E E E为已知模式(均匀分布、随机分布)下的期望值。
χ 2 \chi^2 χ2越大,待评价分布与已知分布相符的可能性越小
方位分析
中心位置

标准差椭圆
绘制方法:
(1)确定圆心
S D E x = ∑ i = 1 n ( x i − X ˉ ) 2 n S D E y = ∑ i = 1 n ( y i − Y ˉ ) 2 n \begin{aligned} S D E_x & =\sqrt{\frac{\sum_{i=1}^n\left(x_i-\bar{X}\right)^2}{n}} \\ S D E_y & =\sqrt{\frac{\sum_{i=1}^n\left(y_i-\bar{Y}\right)^2}{n}}\end{aligned} SDExSDEy=n∑i=1n(xi−Xˉ)2=n∑i=1n(yi−Yˉ)2
X i X_i Xi 和 Y i Y_i Yi 是每个要素的空间位置坐标, X ˉ \bar{X} Xˉ 和 Y ˉ \bar{Y} Yˉ是算数平均中心。
S D E x S D E_x SDEx 和 S D E y S D E_y SDEy就是计算出来的椭圆的方差。
椭圆的大小取决于方差大小,长半轴表示最大方差,短半轴表示最小方差,在空间统计上面,用X、Y的方差进行计算,得到长短半轴。
(2)确定椭圆的方向
tan θ = A + B C A = ( ∑ i = 1 n x ~ i 2 − ∑ i = 1 n y ~ i 2 ) B = ( ∑ i = 1 n x ~ i 2 − ∑ i = 1 n y ~ i 2 ) 2 + 4 ( ∑ i = 1 n x ~ i y ~ i ) 2 C = 2 ∑ i = 1 n x ~ i y ~ i \begin{aligned} \tan \theta & =\frac{A+B}{C} \\A & =\left(\sum_{i=1}^n \tilde{x}_i^2-\sum_{i=1}^n \tilde{y}_i^2\right) \\ B & =\sqrt{\left(\sum_{i=1}^n \tilde{x}_i^2-\sum_{i=1}^n \tilde{y}_i^2\right)^2+4\left(\sum_{i=1}^n \tilde{x}_i \tilde{y}_i\right)^2} \\ C & =2 \sum_{i=1}^n \tilde{x}_i \tilde{y}_i\end{aligned} tanθABC=CA+B=(i=1∑nx~i2−i=1∑ny~i2)=(i=1∑nx~i2−i=1∑ny~i2)2+4(i=1∑nx~iy~i)2=2i=1∑nx~iy~i
x ~ i \tilde{x}_i x~i、 y ~ i \tilde{y}_i y~i是平均中心和(x, y)坐标的差
(3)确定椭圆方程
σ x = 2 ∑ i = 1 n ( x ~ i cos θ − y ~ i sin θ ) 2 n \sigma_x=\sqrt{2} \sqrt{\frac{\sum_{i=1}^n\left(\tilde{x}_i \cos \theta-\tilde{y}_i \sin \theta\right)^2}{n}} σx=2n∑i=1n(x~icosθ−y~isinθ)2
σ y = 2 ∑ i = 1 n ( x ~ i sin θ + y ~ i cos θ ) 2 n \sigma_y=\sqrt{2} \sqrt{\frac{\sum_{i=1}^n\left(\tilde{x}_i \sin \theta+\tilde{y}_i \cos \theta\right)^2}{n}} σy=2n∑i=1n(x~isinθ+y~icosθ)2
( x σ x ) 2 + ( y σ y ) 2 = s \left(\frac{x}{\sigma_x}\right)^2+\left(\frac{y}{\sigma_y}\right)^2=s (σxx)2+(σyy)2=s
σ x \sigma_x σx、 σ y \sigma_y σy分别是X、Y轴的标准差
s s s 是置信度的值
结果解读:
(1)椭圆的长半轴表示的是数据分布的方向,短半轴表示的是数据分布的范围,长短半轴的值差距越大(扁率越大),表示数据的方向性越明显。
(2)短半轴表示数据分布的范围,短半轴越短,表示数据呈现的向心力越明显;反之,短半轴越长,表示数据的离散程度越大。
(3)若长短半轴相等,则表示数据没有任何的分布和方向特征。
标准差的体现:
三个级别的椭圆,分别表示生成的椭圆能够包含68%,95%和99%的数据,对应着标准正态分布中的 1 σ 1 \sigma 1σ, 2 σ 2 \sigma 2σ, 3 σ 3 \sigma 3σ。
属性分析
- 空间插值
- 空间聚类
- 空间相关性分析
- ……
其它
- 趋势变化
- 轨迹追踪
- ……
完全空间随机性(Compete Spatial Randomness -CSR)
两个特征:
1、空间一致性:
每一个位置发生某一件事情具有相同的概率,事件的强度在平面上并不发生变化
2、独立性:
两个地点是否发生某一事件不相互影响
The events of a pattern are independently and uniformly distributed over space; in other words, the events are equally likely to occur anywhere and do not interact with each other.
数学定义:
考虑一个区域S及其子区域C。S中有n个随机点, N ( C ) N(C) N(C)表示落在区域C内的点个数。
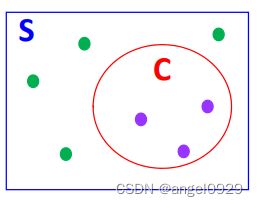
则 N ( C ) N(C) N(C)在随机下的期望为:
E [ N ( C ) ] = n a ( C ) a ( S ) E[N(C)]=n \frac{a(C)}{a(S)} E[N(C)]=na(S)a(C)
将S的点落在C内视作一个随机实验,则落在C内的点的个数的概率分布满足二项分布,即某件事情发生概率为 p , p = a ( C ) a ( S ) p, p=\frac{a(C)}{a(S)} p,p=a(S)a(C),那么
P ( X = k ) = C n k p k ( 1 − p ) n − k P(\mathrm{X}=k)=C_n^k p^k(1-p)^{n-k} P(X=k)=Cnkpk(1−p)n−k
带入 p p p可进一步计算出有k个点落在区域C中概率
当 n n n趋于∞时,上时采用泊松分布近似,另 λ = n a ( S ) \lambda=\frac{n}{a(S)} λ=a(S)n,则:
P [ N ( C ) = k ∣ λ ] = [ λ a ( C ) ] k k ! e − λ a ( C ) P[N(C)=k \mid \lambda]=\frac{[\lambda a(\mathrm{C})]^k}{k !} e^{-\lambda a(\mathrm{C})} P[N(C)=k∣λ]=k![λa(C)]ke−λa(C)
应用:
(1)用作零假设,来判断点分布是否为随机的
检验方法: χ 2 \chi^2 χ2检验(O为实际值,E为CSR模式下的期望值)

因为泊松分布的方差和均值相等,所以在CSR的情况下,方差均值之比为1。所以>1:离散分布;<1:聚集分布。
(2)判断当处在在某一位置上时,下一个有事件发生的点与该位置的距离是多少
记随机变量D为给定点到离其最近点的距离,则D在CSR下的分布为:
P { D < d } = P { N [ a ( C d ) ] = k = 0 } = e − λ a ( C d ) = e − λ π d 2 P\{D
P { D = d } = p ( d ) = F ′ ( d ) = 2 π λ d ⋅ e − π λ d 2 P\{D=d\}=p(d)=F^{\prime}(d)=2 \pi \lambda d \cdot e^{-\pi \lambda d^2} P{D=d}=p(d)=F′(d)=2πλd⋅e−πλd2

再根据大数定理构造标准正态分布,进行Z-test检验。
Z m = D ˉ m − 1 / ( 2 λ ) ( 4 − π ) / ( m 4 π λ ) Z_m=\frac{\bar{D}_m-1 /(2 \sqrt{\lambda})}{\sqrt{(4-\pi) /(m 4 \pi \lambda)}} Zm=(4−π)/(m4πλ)Dˉm−1/(2λ)
点过程的协变量效应

![]()
趋势分析
趋势分析是分析地理现象沿着时间/空间变化的规律
常见的模型分类:
- 线性 or 非线性
- 参数 or 非参数
线性趋势
一般用简单线性回归拟合
拟合方程: y t = a + b t y_t=a+b t yt=a+bt
用最小二乘法拟合求解未知参数 a a a、 b b b
线性显著性检验:

(t分布的自由度为n-2)
单调趋势
随着时间/空间存在上升/下降的改变, 通常只关心相对大小,并且对异常值不敏感,
判断平均变化趋势的大小:(Sen‘’s估计法)
β = Median ( x j − x i j − i ) , j > i \beta=\operatorname{Median}\left(\frac{x_{\mathrm{j}}-x_{\mathrm{i}}}{\mathrm{j}-\mathrm{i}}\right), \quad \mathrm{j}>\mathrm{i} β=Median(j−ixj−xi),j>i
显著性检验:
Mann-Kendall趋势检验: 一种非参数检验方法,能检验某一自然过程是处于随机波动还是存在确定的单调改变
趋势。不需要样本遵从一定的分布,只关心观测值的相对大小。
统计量:
S = ∑ k = 1 n − 1 ∑ j = k + 1 n sign ( x j − x k ) S=\sum_{k=1}^{n-1} \sum_{j=k+1}^n \operatorname{sign}\left(x_j-x_k\right) S=∑k=1n−1∑j=k+1nsign(xj−xk)
随机情况下的期望和方差:
E ( S ) = 0 \mathrm{E}(\mathrm{S})=0 E(S)=0
V a r ( S ) = n ( n − 1 ) ( 2 n + 5 ) / 18 {Var}(\mathrm{S})=\mathrm{n}(\mathrm{n}-1)(2 \mathrm{n}+5) / 18 Var(S)=n(n−1)(2n+5)/18
检验统计量:
n>10的时候根据大数定理转换为标准正态分布。
Z = { S − 1 Var ( S ) S > 0 0 S = 0 S + 1 Var ( S ) S < 0 \mathrm{Z}=\left\{\begin{array}{cl}\frac{\mathrm{S}-1}{\sqrt{\operatorname{Var}(\mathrm{S})}} & \mathrm{S}>0 \\ 0 & \mathrm{~S}=0 \\ \frac{\mathrm{S}+1}{\sqrt{\operatorname{Var}(\mathrm{S})}} & \mathrm{S}<0\end{array}\right. Z=⎩ ⎨ ⎧Var(S)S−10Var(S)S+1S>0 S=0S<0
随机性和断点检验
随机性检验
方法
- Wallis-Moore Phase Frequency Test
- Bartels rank von Neumann’s ratio test
- Wald-Wolfowitz Test
- ……
Wald-Wolfowitz Test:
统计量:
R = ∑ i = 1 n − 1 x i x i + 1 + x 1 x n R=\sum_{i=1}^{n-1} x_i x_{i+1}+x_1 x_n R=∑i=1n−1xixi+1+x1xn
随机情况下的期望和方差:
E ( R ) = s 1 2 − s 2 n − 1 E(R)=\frac{s_1^2-s_2}{n-1} E(R)=n−1s12−s2
V ( R ) = s 2 2 − s 4 n − 1 − E ( R ) 2 + s 1 4 − 4 s 1 2 s 2 + 4 s 1 s 3 + s 2 2 − 2 s 4 ( n − 1 ) ( n − 2 ) V(R)=\frac{s_2^2-s_4}{n-1}-E(R)^2+\frac{s_1^4-4 s_1^2 s_2+4 s_1 s_3+s_2^2-2 s_4}{(n-1)(n-2)} V(R)=n−1s22−s4−E(R)2+(n−1)(n−2)s14−4s12s2+4s1s3+s22−2s4
s t = ∑ i = 1 n x i t , t = 1 , 2 , 3 , 4 s_t=\sum_{i=1}^n x_i^t, \quad t=1,2,3,4 st=∑i=1nxit,t=1,2,3,4
检验统计量
n>10的时候根据大数定理,可以用正态分布近似拟合。
Z = R − E ( R ) V ( R ) Z=\frac{R-E(R)}{\sqrt{V(R)}} Z=V(R)R−E(R)
突变点检测
方法
- Lanzante’s test procedures
- Pettitt’s test, Buishand Range Test
- Buishand U Test
- Standard Normal Homogeneity Test
- ……
Buishand U Test:
步骤:
(1)将样本分成两段:
x i = { μ + ϵ i , i = 1 , … , m μ + Δ + ϵ i i = m + 1 , … , n x_i= \begin{cases}\mu+\epsilon_i, & i=1, \ldots, m \\ \mu+\Delta+\epsilon_i & i=m+1, \ldots, n\end{cases} xi={μ+ϵi,μ+Δ+ϵii=1,…,mi=m+1,…,n
(2) H 0 : Δ = 0 H_0:\Delta = 0 H0:Δ=0
(3)构造统计量:
U = U= U= 1 n ( n + 1 ) \frac{1}{n(n+1)} n(n+1)1 ∑ k = 1 n − 1 ( S k / D x ) 2 \sum_{k=1}^{n-1}\left(S_k / D_x\right)^2 ∑k=1n−1(Sk/Dx)2
S k = ∑ i = 1 k ( x i − x ˉ ) 1 ≤ i ≤ n S_k=\sum_{i=1}^k\left(x_i-\bar{x}\right)\quad1≤i≤n Sk=∑i=1k(xi−xˉ)1≤i≤n, D x = n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 \quad D_x=\sqrt{n^{-1} \sum_{i=1}^n\left(x_i-\bar{x}\right)^2} Dx=n−1∑i=1n(xi−xˉ)2
P-value由Monte Carlo模拟求得
S ^ = max ( ∣ S k ∣ ) \hat{S}=\max \left(\left|S_k\right|\right) S^=max(∣Sk∣),突变点K为 ∣ S k ∣ \left|S_k\right| ∣Sk∣最大时对应的 k 值
空间插值
暂略
描述统计量
距离与相似性

(Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions)
-
连续数值变量
( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 / p \left(\sum_{i=1}^n\left|x_i-y_i\right|^p\right)^{1 / p} (∑i=1n∣xi−yi∣p)1/p
p = 2 p=2 p=2,欧式距离
p = 1 p=1 p=1,曼哈顿距离
…… -
二值变量

symmetric binary variables: d ( i , j ) = b + c a + b + c + d d(i, j)=\frac{b+c}{a+b+c+d} d(i,j)=a+b+c+db+casymmetric binary variables: d ( i , j ) = b + c a + b + c d(i, j)=\frac{b+c}{a+b+c} d(i,j)=a+b+cb+c
-
类型变量
d ( i , j ) = p − m p d(i, j)=\frac{p-m}{p} d(i,j)=pp−m,(p:变量总数,m:两个实体相同的变量数)
-
顺序变量
z i f = r i f − 1 M f − 1 z_{i f}=\frac{r_{i f}-1}{M_f-1} zif=Mf−1rif−1,( r i f r_{i f} rif:变量的顺序, M f : M_f: Mf:变量总数)
多样性
多样性指数定量测量在同一集合(区域)内,有多少种不同类型的对象以及每种类型对象数量的分布特征。
衡量方法:
-
Shannon entropy,熵:
H ′ = − ∑ i = 1 R p i ln p i H^{\prime}=-\sum_{i=1}^R p_i \ln p_i H′=−∑i=1Rpilnpi,(R是类型个数,p是每种类型的比例) -
Simpson index:
λ = ∑ i = 1 R p i 2 \lambda=\sum_{i=1}^R p_i^2 λ=∑i=1Rpi2 -
Gini–Simpson index:
1 − λ = 1 − ∑ i = 1 R p i 2 1-\lambda=1-\sum_{i=1}^R p_i^2 1−λ=1−∑i=1Rpi2
Simpson index和GIni-Simpson index的实际含义是随机选取两个目标,类型相同/不同的概率
不均衡系数
Gini系数: 最初用于描述一个区域内收入/财富在人群中的分布以及不均衡性评估
定义: Gini系数的定义是基于Lorenz曲线: G = A A + B G=\frac{A}{A+B} G=A+BA

应用:
- 环境领域:用来衡量生物多样性,其中作对比的是物种的累积比例与个体的累积比例。
- 健康领域:用于衡量人口中与健康有关的生活质量的不平等程度。
- 教育领域:用来衡量大学的不平等程度。
- 工程应用,用于评估Internet routers在调度来自不同流量的数据包传输时所达到的公平性。
- ……
混淆矩阵相关内容
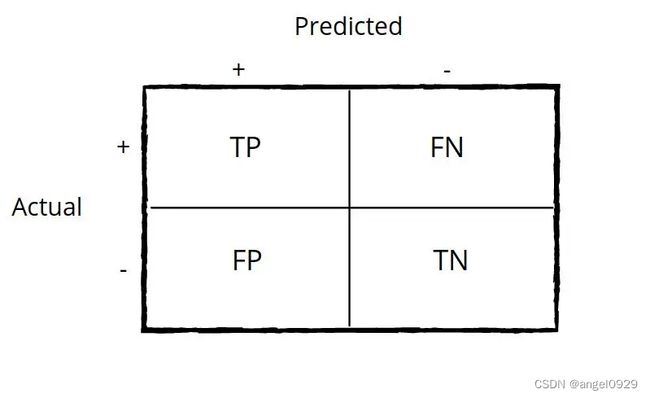
基本概念:
-
Accuracy(准确性):
( T P + T N ) / t o t a l (TP+TN)/ total (TP+TN)/total
用于总体评价模型分类的准确性如何,在样本均衡的时候是一个合理有效的评价指标,当样本不均衡时不好用。
eg.
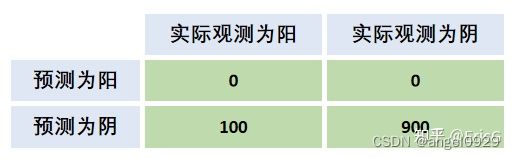
该模型的Accuracy达到0.9。但是实际上,模型一个阳性都没有鉴别出来。 -
True Positive Rate(召回率)
= T P / T P + F N = TP/TP+FN =TP/TP+FN
又被称为Sensitivity,Recall,是指目标对象被正确识别的比例。
追求TPR高可以解释为“不放过一个坏人”,极端情况为将所有对象都预测为目标对象,此时 TPR= 1。 -
True Negative Rate(特异性)
= T P / F P + T N = TP/FP+TN =TP/FP+TN
又被称为Specificity,是指非目标对象被正确排除的比例。
追求TNR高可以解释为“不冤枉一个好人”,极端情况为把所有对象都预测为非目标对象,此时 TNR = 1。 -
Precision(精度)
= T P / T P + F P = TP/TP+FP =TP/TP+FP
在被识别为目标对象的集合中有多少是真正的目标对象。
1-Precision可以用来表示“有多少好人被冤枉”。同理,1- T N / T N + F N TN/TN+FN TN/TN+FN可以用来表示“有多少坏人被放过”。 -
Error Rate(错误率)
= ( F P + F N ) / t o t a l =(FP+FN)/total =(FP+FN)/total
Kappa系数
用来弥补用Accuracy评价模型时由于样本不均衡而产生的不合理性。根据Kappa系数的计算公式,越不平衡的混淆矩阵, p e p_e pe越高,Kappa值就越低,从而可以给“偏向性”强的模型打低分。
用于一致性检验,可以用于多分类问题。
K = P o − P e 1 − P e K=\frac{\mathrm{P}_{\mathrm{o}}-\mathrm{P}_{\mathrm{e}}}{1-\mathrm{P}_{\mathrm{e}}} K=1−PePo−Pe
p o = 对角线元素之和 整个矩阵元素之和 p_o=\frac{\text { 对角线元素之和 }}{\text { 整个矩阵元素之和 }} po= 整个矩阵元素之和 对角线元素之和 , p e = ∑ i 第 i 行元素之和 ∗ 第 i 列元素之和 ( ∑ 矩阵所有元素 ) 2 p_e=\frac{\sum_i \text { 第 } i \text { 行元素之和 } * \text { 第 } i \text { 列元素之和 }}{\left(\sum \text { 矩阵所有元素 }\right)^2 } pe=(∑ 矩阵所有元素 )2∑i 第 i 行元素之和 ∗ 第 i 列元素之和
F F F Score
是一个综合考虑 Precision 和 Recall 的评估指标,理想情况下是希望两个指标都高,但实际情况是Precision高,Recall就低,Recall高,Precision就低。
所以我们需要一个综合的指标对两个值进行折中与取舍:
(1)在保证召回率的条件下,尽量提升精确率(一般的搜索情况)
(2)在保证精确率的条件下,尽量提升召回率。(癌症检测、地震检测、金融欺诈)
F − F- F− Score = ( 1 + β 2 ) ⋅ Precision ⋅ Recall β 2 ⋅ Precision + Recall =\left(1+\beta^2\right) \cdot \frac{\text { Precision } \cdot \text { Recall }}{\beta^2 \cdot \text { Precision }+\text { Recall }} =(1+β2)⋅β2⋅ Precision + Recall Precision ⋅ Recall
通过调整 β 来调节哪一个值更重要。如果认为精确率更重要些,那就调整β的值小于1;如果认为召回率更重要些,那就调整β的值大于1。
ROC曲线
用来比较在每一个阈值下,非目标对象未被排除的比例和目标对象被正确识别的比例之间的关系。
根据ROC曲线找最优点的原则就是:保证TPR高的同时FPR要尽量的小。可以建立
m a x ( T P R + ( 1 − F P R ) ) max (TPR+(1-FPR)) max(TPR+(1−FPR))的模型。一般方法是找到离(0,1)最近的点。
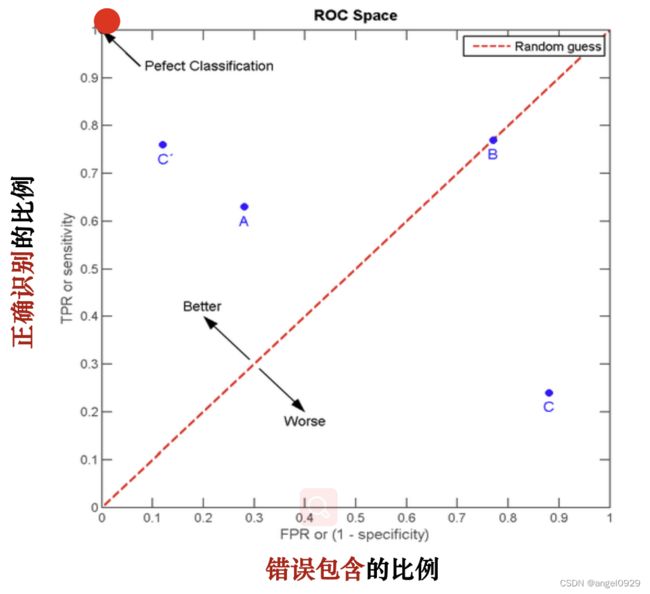
在实际应用中选取最佳阈值,还需要考虑对真阳性的要求以及对假阳性的容忍程度。
比如,在一些病毒检测实验中,要求能够识别出所有的真阳性、可以容忍一定程度的假阳性(宁可错杀三千,不可放过一个)——此时要选靠右的点的阈值,使得TPR尽可能大。
如果不能容忍假阳性、要求识别出来的样本必须为真阳性(绝不冤枉一个好人)——此时可以选靠右的点对应的阈值,使得FPR尽可能小。
AUC
ROC曲线下的面积(AUC)衡量一个分类器随机选择一个目标对象高于随机选择非目标对象的概率。所以一般来说,AUC 的值越大表示模型越好。
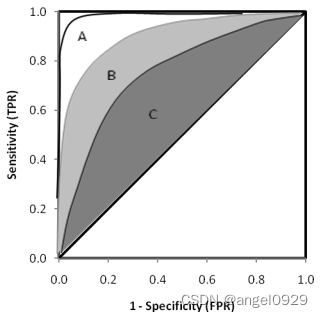
上图中的三条ROC曲线,A模型比B和C都要好
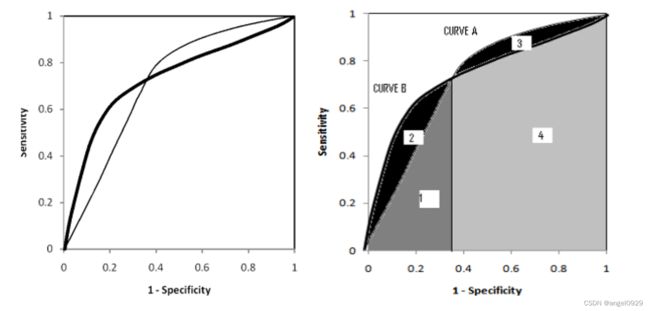
上面两幅图中两条ROC曲线相交于一点,AUC值几乎一样:
当需要高Sensitivity时,模型A比B好;
当需要高Speciticity时,模型B比A好