Attention:何为注意力机制?
本文来自公众号“AI大道理”
人类利用有限的注意力资源从大量信息中快速筛选出高价值信息,这是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
attention从注意力模型的命名方式看,借鉴了人类的注意力机制。
![]()
1、从机器翻译说起
Seq2Seq模型,想要解决的主要问题是:如何把机器翻译中,变长的输入X映射到一个变长输出Y的问题。
序列模型可以较好地学习到句子的语法知识,但是,在应用Sequence学习机器翻译问题时,仍然存在两个明显的问题:
1、把输入X的所有信息有压缩到一个固定长度的隐向量Z。当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降;
2、把输入X编码成一个固定的长度Z,对于句子中每个词都赋予相同的权重。但是词与词之间的翻译一般有对应关系,如果对输入的每个词赋予相同权重,这样做没有对应翻译的区分度,往往使模型性能下降。
attention能解决以上两个问题。
Attention关键就是学习出来一个权重分布,然后这个作用可以作用在特征上。这个权重作用在不同的载体上,就可以在实际中得到具体应用。
作用在不同时刻上,如机器翻译。
![]()
2、soft attention
对输入X的不同部分赋予不同的权重,实现了句子中不同部分词汇的对齐翻译,同时在对应位置上浓缩了句子的相关信息,达到了软区分(soft attention)相关信息更好地提取知识的目的。
Soft attention在编码器提取知识到隐变量的阶段时,不是将原句中所有的信息进行抽象学习。反之,它释放了编码器提取所有信息的压力。
因此,针对一个很长的句子,编码器可以从中提取更有效的信息实现机器翻译。
Attention机制,使得我们允许Decoder在每一步输出时使用隐变量Z中的不同部分的特征知识。此外,Attention机制让模型根据隐变量Z和已经生成的单词决定加强Z中不同部分特征的学习。
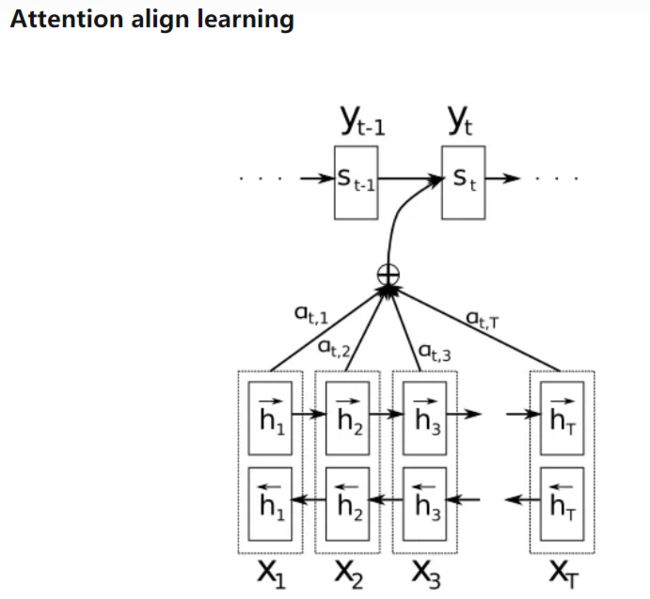
其主要的用法是先计算一个权重因子α,然后根据α的大小对隐变量Z(图中用h表示)进行加权求和。
其中,α值越大,对应的h隐变量对解码翻译的信息贡献越大。
在引入Attention机制之前,Decoder解码翻译时根据固定的隐变量Z进行提取知识学习,然而引入Attention之后,隐变量Z在不同时刻发生了变化。
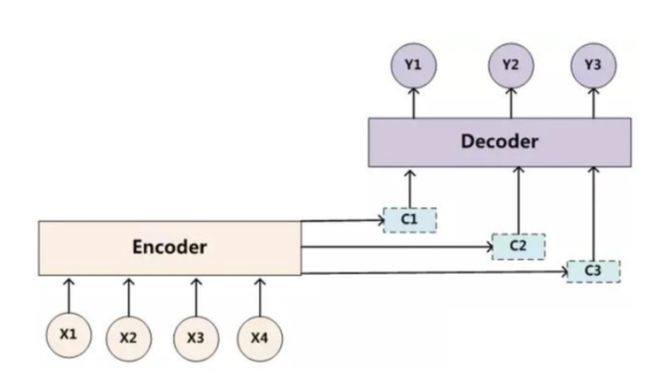
Attention模型的关键就是这里,即由固定的中间语义表示Z换成了受到注意力因子影响后的动态隐变量C,从而达到对齐翻译的效果。
![]()
3、Self Attention
传统的Attention机制过度依赖在Encoder-Decoder架构上;
传统的Attention机制依赖于Decoder的循环解码器,所以依赖于RNN,LSTM等循环结构;
传统的Attention依赖RNN结构,无法做到并行训练,训练速度受到影响;
传统的Attention计算本质是通过对比输入空间和输出空间的特征,学习Attention权重因子。
Self Attention脱离了Encoder-Decoder架构和RNN/CNN结构,并且针对输入空间特征或者输出空间特征单独学习权重因子,它不需要同时依赖两个空间的联系。
适合针对一个空间维度特征的知识进行学习,所以Self Attention也经常被称为intra Attention(内部Attention)。
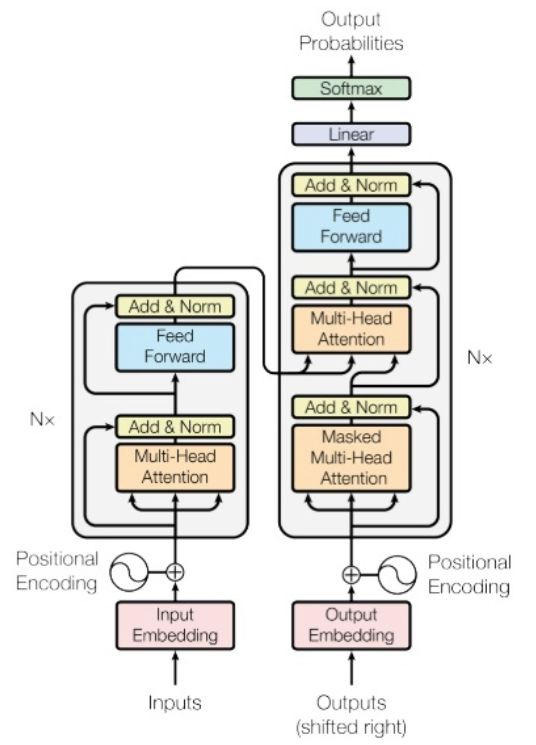
模型架构
该模型的架构如图1所示,依然符合seq2seq的架构,由encoder和decoder组成。在编码器中由许多重复的网络块组成,一个网络块由一个多头attention层和一个前向神经网络组成(而非单独使用attention模型),整个编码器栈式搭建了N个块。
Decoder与encoder类似,除了编码器到解码器的学习外,还有解码器到解码器的学习。
同时,为了能够更深层次的搭建网络结构,该模型使用了残差结构(Add)和对层的规范化(Norm)。
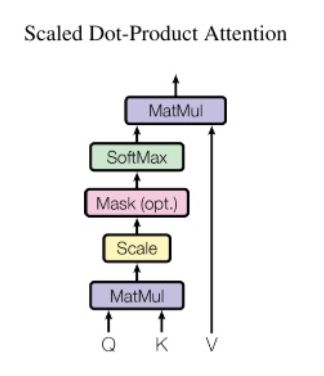
Scaled Dot-Product Attention的具体计算方法如下:
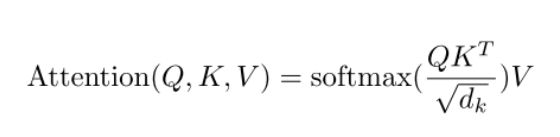
Attention的输入有Q,K,V分别代表query, key, value三个概念。
和传统的Additive Attention对比,这里的query相当于Decoder循环层的输出,key和value相当于Encoder输出的隐特征向量。
Scaled Dot-Product Attention也有三个计算步骤:
1、Q和K进行点乘得到初步权重因子,并对Q,K点乘结果进行缩放处理,这里除以\sqrt{dk}变量。对该步骤的计算,论文给出的解释是:假设Q和K都是独立的随机变量,满足均值为0,方差为1,则点乘后结果均值为0,方差为dk。也即方差会随维度dk的增大而增大,而大的方差导致极小的梯度。所以为了防止梯度消失,论文中用内积除以维度的开方,使之变为均值为0,方差为1;
2、步骤1中得到的权重分值进行归一化处理,即用softmax计算,使所有权重因子和为1;
3、根据归一化后的权重系数对value进行加权求和。
在整个模型中,从编码器到解码器的地方都使用了self attention结构,K、V和Q分别是编码器的层输出(这里K=V)和解码器中self attention的输入,这其实跟主流的机器翻译模型中的additive attention一样,进行传统的翻译对齐任务。
然后,在编码器和解码器中都使用了self-attention结构来学习文本的表示,K=V=Q,即里面的每个词都要和该句子中的所有词进行attention计算,其主要目的是学习句子内部的词依赖关系,捕获句子中的内部结构。
![]()
4、视觉中的Atttention
视觉中的Atttention其实也是学出一个权重分布,再拿这个权重分布施加在原来特征之上。
不过施加权重的方式略有差别,视觉应用中一般有以下几种施加方式:
-
加权可以保留所有分量做加权(soft attention);
-
可以在分布中以某种采样策略选取部分分量做加权(hard attention);
-
加权可以作用在原图上;
-
加权可以作用在空间尺度上,给不同空间区域加权;
-
加权可以作用在Channel尺度上,给不同通道特征加权;
-
加权可以作用在不同时刻历史特征上,结合循环结构添加权重,例如前面两章节介绍的机器翻译,或者后期会关注的视频相关的工作。
![]()
5、Hard Attention
机器翻译中的Attention和Self Attention,都属于Soft Attention的类型。
Hard Attention和Soft Attention的学习原理,这种结合强化学习“随机”采样图像局部区域的过程与我前两章内容介绍的Attention(Soft Attention)具有一定的区别:
Soft Attention是依赖特征之间的关系学习权重,Hard Attention主要在局部特征区域进行随机crop的过程;
Soft Attention可以嵌入到网络中应用Loss收敛学习权重,Hard Attention主要依赖强化学习训练权重(自然语言中有依赖蒙特卡罗方法),无法嵌入到网络中收敛学习;
Soft Attention的特征采样权重经过Softmax处理以后,所有的权重大小在0~1之间,大部分是小数形式,特征关系的采集是特征值和权重的累积和;Hard Attention的特征采集权重一般是局部区域作为一个整体(权重可以理解为只有0, 1两个情况),局部特征之间的关系需要经过神经网络进一步学习。
hard attention 的两种体现。一种是 picture crop,直接对一张图进行裁剪。把一些没有用的东西去掉。这种方式优点是简单暴力,直观。缺点是,不够general,不同图片,问题不太一样,没有明确的标准。另外一种是用RL不断学习,把像素关闭。
对比机器视觉任务上的Soft Attention和机器翻译上的Soft Attention,可以发现机器视觉上的Soft Attention似乎都是在输入空间上做的特征提取,这和机器翻译中的Attention定义似乎有些区别。
在机器翻译上的Soft Attention一般都是联系对比输入空间和输出空间的特征并提取Attention权重。如果只对输入空间做特征分析,一般属于Self Attention的定义。
![]()
6、视觉应用中的Self Attention
学出了non-local位置信息之间的关联。
对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
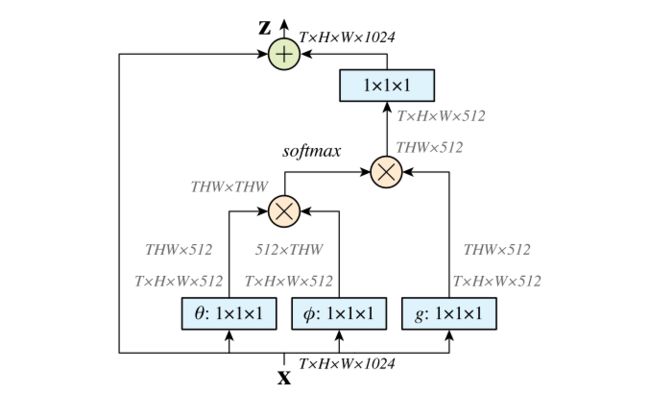
-
首先对输入的 feature map X 进行线性映射(说白了就是 1*1*1 卷积,来压缩通道数),然后得到 θ,φ,g 特征;
-
通过reshape操作,强行合并上述的三个特征除通道数外的维度,然后对θ和φ进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系);
-
然后对自相关特征进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention 系数;
-
最后将 attention系数,对应乘回特征矩阵 g 中,然后再上扩展channel数(1*1卷积),与原输入 feature map X 做残差运算,获得non-local block的输出。
![]()
7、Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
从概念上理解,是为注意力机制。
可以把Attention理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。
从计算上理解,是为权重分配机制。
不论何种注意力机制,本质上就是分配权重。其主要聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的特征值上,即权重代表了信息的重要性,而对应特征是其需要重点学习的知识。hard-attention分配的权重不是0就是1,而soft-attetion分配的权重则是0-1。
从QKV上理解,是为匹配机制。
QK的计算得出了相关性,相关性越高的权重越大,也即越匹配。因此,若想从一张图中找出狗,注意力机制就要让权重匹配上狗,将狗的这一块区域凸显出来。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
投稿吧 | 留言吧