基于gensim的Word2vec词向量训练
1、导入所需的库
# 首先导入所需要的库
import pandas as pd
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence2、读取数据
# 读取数据
df = pd.read_csv('tiyu.csv', encoding='gbk')
df.head()
输出数据的前5行
3、将数据转化成列表
# 将数据转化成列表
cps = []
line_sent = []
for i in df.groupby(['id']):
seg_list = list(i[1].word)
# print(seg_list)
line_sent.append(seg_list)
seg = ' '.join(seg_list)
cps.append(seg)
print(line_sent) 
4、计算词频
# 计算词频
import nltk
for i in cps:
ii = i.split(' ')
cfd = dict(nltk.FreqDist(ii))
print(cfd)
4、运用gensim的word2vec方法,训练模型, 训练好的模型保存在word2vec.model.
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
1) sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
2) size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
3) window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
4) sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
5) hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
7) cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
8) min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
9) iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
10) alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
11) min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
12) workers控制训练的并行,此参数只有在安装了Cpython后才有效,否则只能使用单核。
# 训练模型
model = Word2Vec(line_sent,
size=300,
window=5,
min_count=1,
workers=2)
print(model)
model.save('./word2vec.model')
print(model.wv.vocab) ![]()

5、导入模型
model = Word2Vec.load('word2vec.model')
print(model.wv['球员'])
print(model.most_similar('球员'))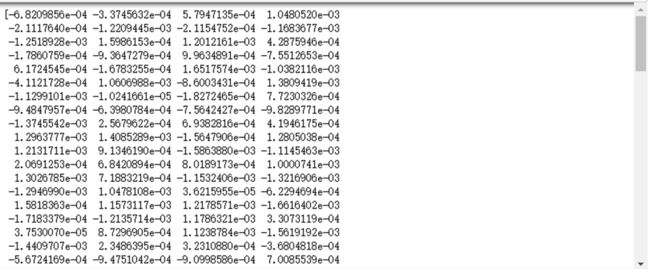
可以得到训练的词向量列表, 以及类似于“球员”的这个词的相似词, 但由于训练样本比较少, 训练结果可能不够准确。
5、测试结果
testwords = ['球员','大卫', '篮球']
for i in range(3):
res = model.most_similar(testwords[i])
print(testwords[i])
print(res) 