python如何训练图片_python+caffe训练自己的图片数据流程
1. 准备自己的图片数据
选用部分的Caltech数据库作为训练和测试样本。Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集。该数据集是由Fei-FeiLi, Marco Andreetto, Marc 'Aurelio Ranzato在2003年9月收集而成的。Caltech101包含101种类别的物体,每种类别大约40到800个图像,大部分的类别有大约50个图像。Caltech256包含256种类别的物体,大约30607张图像。图像如下图所示,下载链接为:
Caltech其中的airplanes、Faces、Motorbikes、watch 4个类别分别包含800、435、798、239张图片,选用这4种图片训练和测试数据。
airplanes:

Faces:

Motorbikes:

watch:

2. 图片重命名
为了清楚的分类,收集的图片按照各自的分类重命名一下(该过程也可以省略),airplanes、Faces、Motorbikes和watch类别中的图片分别以0、1、2、和3作为名称的第一个字母(如上图所示,已经做好了重命名),代表自己的分类。python实现的文件批量重命名:
import os
def renameImage(pathFile,label):
startNum=0
for files in os.listdir(pathFile):
oldDir=os.path.join(pathFile,files)
if os.path.isdir(oldDir):
continue
filename=os.path.splitext(files)[0]
filetype=os.path.splitext(files)[1]
newDir=os.path.join(pathFile,str(label)+'_'+str(startNum)+filetype)
os.rename(oldDir,newDir)
startNum+=1
print(oldDir+' 重命名为: '+newDir)
renameImage('D:\\0704\\Motorbikes',2)
renameImage函数第一个参数是需要重命名的文件所在文件夹路径,第二个参数是图片分类。
3. 灰度图转换&&图片大小统一
Caltech中的图片是三通道彩色图片,大小不统一,需要修改成单通道灰度图片,统一修改成64*64大小:
import cv2
import os
import numpy
def Resize(pathFile,reSizeFile):
for files in os.listdir(pathFile):
imagePathFile=os.path.join(pathFile,files)
img=cv2.imread(imagePathFile,0)
imgResize=cv2.resize(img,(64,64),interpolation=cv2.INTER_CUBIC)
reSizeDir=os.path.join(reSizeFile,files)
cv2.imwrite(reSizeDir,imgResize)
print(imagePathFile+' 调整大小成功,存放路径在: '+reSizeFile)
Resize('D:\\0704\\Motorbikes','D:\\0704\\RMotorbikes')
第一个参数是的图片文件所在路径,第二个参数是保存路径。
4. 生成Label文件
图片准备好之后开始制作label标签文件,格式是 “xx.jpg 0”,python实现:
import os
def maketxtList(imageFile,pathFile,label):
fobj=open(pathFile,'a')
for files in os.listdir(imageFile):
fobj.write('\n'+files+' '+str(label))
print(files+' '+str(label)+' 写入成功!')
fobj.close()
maketxtList('D:\\0704\\Testwatch','D:\\0704\\testLabel.txt',3)
第一个参数是在第3步处理好的图片路径,第二个参数是生成的标签文件,第三个参数是标签,生成的标签如下:
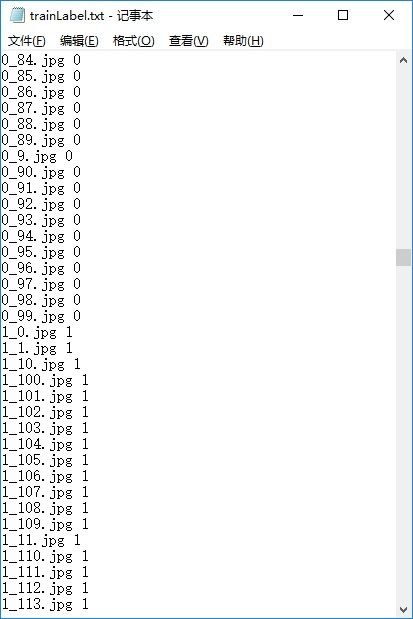
测试数据集分别取airplanes、Faces、Motorbikes、watch各200、200、200、100张图片共700张,按同样的方法生成测试标签。
5. 转化成lmdb数据库文件
新建一个MakeLmdb.bat的脚本文件,使用caffe中的convert_imageset.exe工具转化图片数据为lmdb数据文件:
D:\Software\Caffe\caffe-master\Build\x64\Release\convert_imageset.exe
D:\0704\testImage\ D:\0704\testLabel.txt D:\0704\test_lmdb
pause
执行结果:
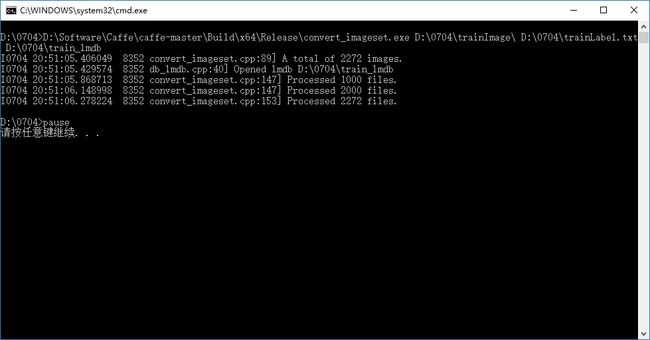
分别生成train_lmdb和 test_lmdb文件:
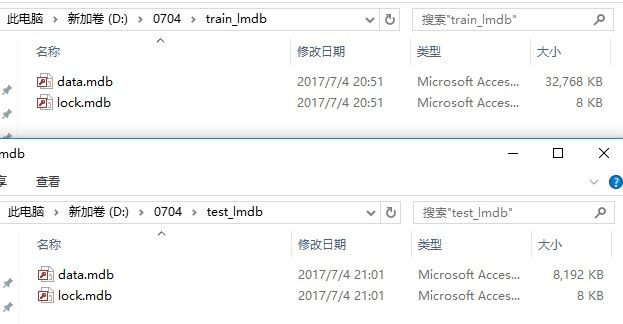
6. 计算均值文件mean.binaryproto
计算均值文件备用:
D:\Software\Caffe\caffe-master\Build\x64\Release\compute_image_mean.exe
D:\0704\test_lmdb D:\0704\mean_test.binaryproto
pause
7. 建立CNN网络和训练参数
CNN网络和训练参数文件使用caffe中mnist例子中的 “lenet_train_test.prototxt” 和 “lenet_solver.prototxt”两个文件,做一些参数修改:
lenet_solve.prototxt文件参数修改:
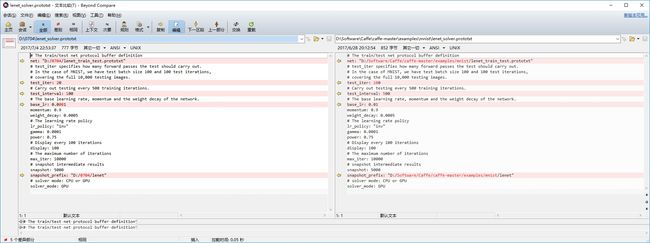
测试数据量比较少,这里的test_iter参数修改为20,另一个就是基础学习率设置为0.0001,这个参数比较重要,需要根据实际情况调整,如果按照之前学习率设置为0.01的话,会出现训练过程中loss一直保持87.3365(其实已经溢出了)这个值不变的情况。
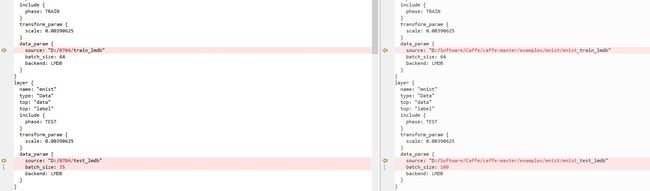
lenet_train_test.prototxt文件参数修改:
1. 修改训练和测试lmdb数据路径和训练数据每组包含数据(batch_size),这里的batch_size不宜设置过小,建议最少为20:
2. 修改输出层 ip2中的输出由10改为4,这里的4代表训练分为4种分类:

8. 执行训练
D:\Software\Caffe\caffe-master\Build\x64\Release\caffe.exe
train --solver=D:\0704\lenet_solver.prototxt
pause
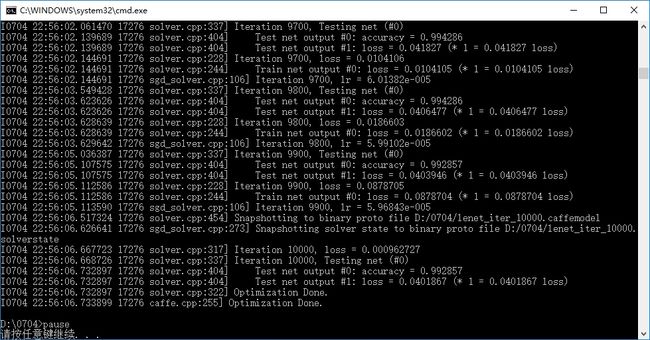
训练结果,accuracy为0.9928: