Pandas详细总结(20000字 完结)
文章内容是我自己学习pandas所做的一些笔记,知识点搭配案例,内容全面而详细。
目录
Series对象
●创建Series对象
●Series的索引
DataFrame对象
●创建DataFrame对象
DataFrame对象的一些重要属性
DataFrame对象的一些重要方法
导入外部数据
导入.xIs或.xIsx文件
导入csv文件
导入html网页数据
数据提取loc和iloc的使用
数据提取按行
数据提取按列
提取区域数据
筛选指定条件数据
数据的增加修改和删除
数据增加
数据修改(内容和索引的修改)
删除数据drop()
数据清洗(缺失值和重复值的处理)
查看缺失值以及判断缺失值
缺失值的处理方式
重复值处理
索引设置
编辑重新设置索引
设置某列为行索引
●数据清洗后重新设置连续索引
数据的排序和排名
数据的排序sort_values()方法
数据的排名 rank()
数据的计算(求和方差等)
数据格式化
编辑设置小数位数
设置千位分隔符
设置百分比
apply() applymap() map() 区别
数据分组统计分析groupby()
分组数据的迭代
对分组的某列或多列使用聚合函数
通过字典和Series对象进行分组统计
数据移位 .shift()
数据转换
一列数据转换为多列数据
行列转换
DataFrame转换为字典、列表和元组
数据合并
merge()
merge方法一对一合并
左连接
右连接
内连接 外连接
多对多或者多对一合并
concat()
纵向合并
横向合并
交叉合并
数据导出
导出数据为Excel文件
导出数据为CSV文件
日期数据处理
日期数据转换
dt对象的使用
获取日期区间数据
按时期统计并显示数据
按时期统计数据 df.resample()
按时期显示数据 df.to_period()
先统计后显示
时间序列 pandas.date_range()
时间序列重采样
时间序列数据汇总 resample().ohlc()
移动窗口数据计算 df.rolling()
Series对象
●Pandas库中的一种数据结构,类似于一维数组
●由一组数据以及与这组数据有关的标签(索引)组成
●Series对象可以存储整数、浮点数、字符串、Python对象等多种数据类型的数据
●创建Series对象
pd.Series(data,index=index)
import pandas as pd
data=['语文','数学','英语']
s=pd.Series(data=data,index=['张三','李四','王五'])print(s)
# 张三 语文 # 李四 数学 # 王五 英语 # dtype: object
●Series的索引
●位置索引
●索引范围[0,N-1]
●标签索引
●索引名称
●获取多个标签索引值使用[标签索引1,标签索...]
●切片索引
●[start:stop:step]
●获取Series的索弓|和值
●获取索引s.index
●获取值s.values
这是一个Series对象s
张三 语文
李四 数学
王五 英语
dtype: object
●位置索引
print(s[1]) >>>数学
●标签索引
print(s['李四']) >>>数学
print(s[['张三','王五']])
# 张三 语文
# 王五 英语
# dtype: object
●切片索引
#位置索引切片 含头不含尾
print(s[0:2])
# 张三 语文
# 李四 数学
# dtype: object
#标签索引切片 含头含尾
print(s['张三':'王五'])
# 张三 语文
# 李四 数学
# 王五 英语
# dtype: object
●Series的索弓|和值
s.values
# ['语文' '数学' '英语']
s.index
# Index(['张三', '李四', '王五'], dtype='object')
DataFrame对象
●DataFrame对象是Pandas库中的一种数据结构,类似于二维数组,由行列构成
●与Series一样支持多种数据类型
●创建DataFrame对象
●pd.DataFrame(data,index,columns,dtype)
import pandas as pd
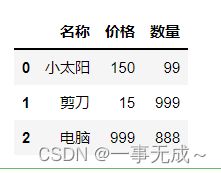
data=[['小太阳',150,99],['剪刀',15,999],['电脑',999,888]]
columns=['名称','价格','数量']
s=pd.DataFrame(data=data,columns=columns)
s
data={
'名称':['小太阳','剪刀','电脑'],
'价格':[150,15,999],
'数量':[99,999,888],
'供应商':'英雄联盟'
}
s=pd.DataFrame(data=data)
s

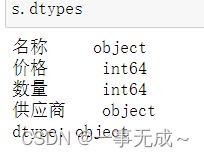
DataFrame对象的一些重要属性
# 1 values 查看所有元素的值 # 2 dtypes 查看所有元素的类型 # 3 index 查看所有行名、重命名行名 # 4 columns 查看所有列名、重命名列名 # 5 T 行列数据转换 # 6 head 查看前N条数据,默认5条 # 7 tail 查看后N条数据,默认5条 # 8 shape 查看行数和列数shape[0]表示行,shape[1]表示列 data={ '名称':['小太阳','剪刀','电脑'], '价格':[150,15,999], '数量':[99,999,888], '供应商':'英雄联盟' } s=pd.DataFrame(data=data)1 s.values
2 s.dtypes
3 s.index
4 s.columns

5 s.T
8 s.shape s.shape[0] s.shape[1]
(3,4) 3 4




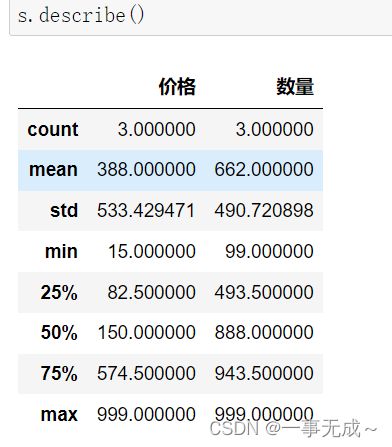
DataFrame对象的一些重要方法
# 1 describe() 查看每列的统计汇总信息,DataFrame类型
# 2 count() 返回每一列的非空值的个数
# 3 sum() 返回每一列的和,无法计算返回空值
# 4 max() 返回每一列的最大值

# 5 min() 返回每一列的最小值
# 6 info() 查看索引、数据类型和内存信息



导入外部数据
导入.xIs或.xIsx文件
●导入.xIs或.xIsx文件
●pd.read _excel(io,sheet_ name,header)
●常用参数说明
●io:表示.xIs或.xIsx文件路径或类文件对象
●sheet_name:表示工作表,用法如下
●header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None
sheet_ name=0 第一个Sheet页中的数据作为DataFrame对象
sheet_ name=1 第二个Sheet页中的数据作为DataFrame对象
sheet_ name= 'Sheet1' 名称为'Sheet1 '的Sheet页中的数据作为DataFrame对象
sheet name=[0,1,'Sheet3'] 第一 个第二个和名称为Sheet3的Sheet页中的数据作为DataFrame象
sheet_ name=None 读取所有工作表
fp=pd.read_excel('美团商家数据.xlsx',sheet_name=0,usecols=['店铺名','饮食类型'])
或fp=pd.read_excel('美团商家数据.xlsx',sheet_name=0,usecols=[0,1])

导入csv文件
● pd.read_ _csv(filepath_ or_ buffer ,sep=',',header,encoding= None)
● 常用参数说明
● filepath_ _or_ _buffer:字符串、文件路径,也可以是URL链接
● sep:字符串、分隔符
● header:指定作为列名的行,默认值为0,即取第一行的值为列名。数据为除列名以外的数据,若数据不包含列表,则设置header= None
● encoding:字符串, 默认值为None,文件的编码格式
fp=pd.read_csv(r'C:\Users\xiaoxin15\Desktop\美食商家数据.csv',sep=',',encoding='gbk')
# gbk对应ANSI
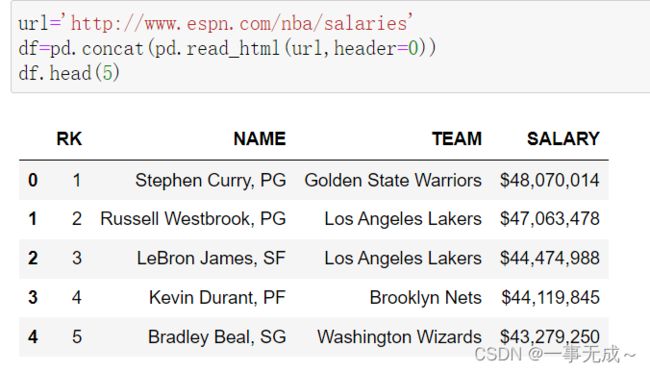
print(fp.head(5))导入html网页数据

# 只可以读取含有table标签的网页
import pandas as pd
url='http://www.espn.com/nba/salaries'
df=pd.concat(pd.read_html(url,header=0))
print(df)
数据提取loc和iloc的使用

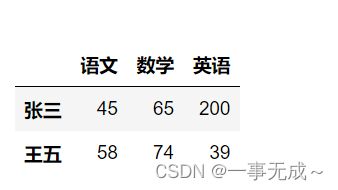
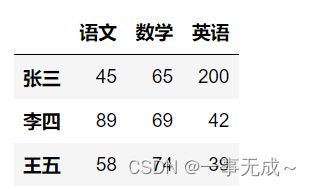
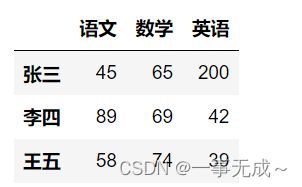
import pandas as pd
data=[[45,65,200],[89,69,42],[58,74,39]]
index=['张三','李四','王五']
col=['语文','数学','英语']
s=pd.DataFrame(data=data,index=index,columns=col)
s

数据提取按行
('----------------------------------------------------------------数据提取 根据标签')
s.loc['张三']('----------------------------------------------------------------数据提取 根据序列')
s.iloc[0]
('----------------------------------------------------------------数据提取 提取多行')
s.loc[['张三','王五']]或
s.iloc[[0,2]]
('----------------------------------------------------------------切片')
s.loc['张三':'王五']
s.iloc[0:2]含头不含尾
s.iloc[::]#start:stop:step


数据提取按列
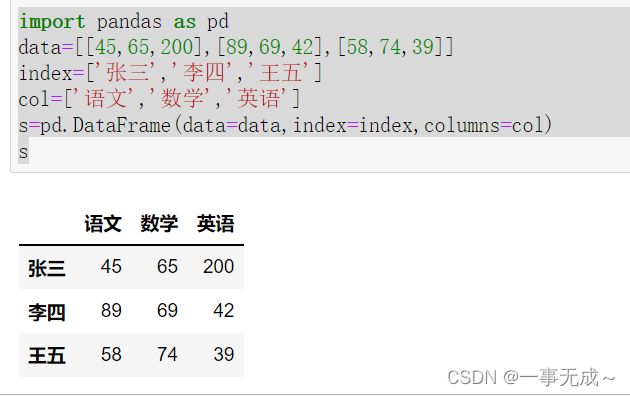
print('----------------------------------------------直接使用列名')
s[['数学','英语']]print('---------------------------------------------使用loc iloc') :逗号左边表示行 逗号右边表示列
s.loc[:,['数学','英语']]
s.iloc[:,[1,2]]
print('----------------提取连续数据')
s.loc[:,'语文':]或
s.iloc[:,0:]
或
s.iloc[:,[0,1,2]]
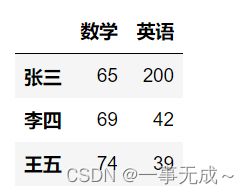

提取区域数据
s.loc['张三','语文']
s.iloc[0,0]
# 45
s.loc[['张三','王五'],['语文','数学']]
s.iloc[[0,2],[0,1]]
s.iloc[0:2,0:2] #,左边行切片,右边列切片
s.loc['张三':'王五','语文':'英语']


筛选指定条件数据
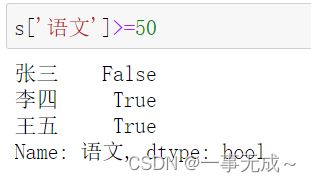
单个条件
s['语文']>=50
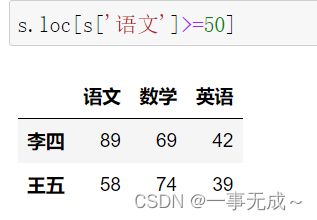
s.loc[s['语文']>=50]
多个条件
s.loc[(s['语文']>=50) & (s['数学']>=70)]

数据的增加修改和删除

数据增加
#按行
print('--------------------------------------直接赋值')
s['化学']=[90,88,67]
s
print('--------------------------------------采用loc属性在最后一列增加')
s.loc[:,'物理']=[77,88,99]
s
print('--------------------------------------在指定索引位置添加一列')
lst=[22,33,32]
s.insert(0,'心理',lst)
s
#按列
print('--------------------------------------采用loc属性')
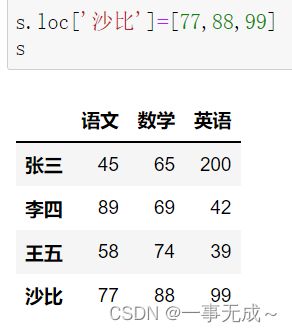
s.loc['沙比']=[77,88,99]
print('--------------------------------------添加多行')
d=pd.DataFrame( data={'语文':[78,79],'数学':[74,71],'英语':[45,46]}, index=['小虎','小红'] ) s=pd.concat([s,d])






数据修改(内容和索引的修改)
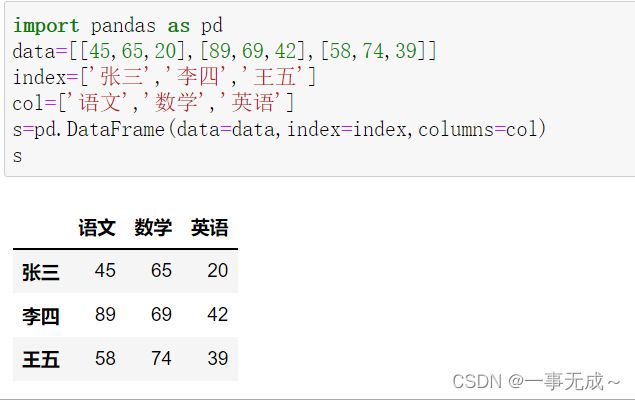
print('---------------------------------------------------------修改列索引')
print('---------------1 直接使用 columns属性')
s.columns=['chinese','math','english']
print('---------------2 使用 rename方法')
s.rename({'chinese':'语文','math':'数学','english':'英语'},inplace=True,axis=1)
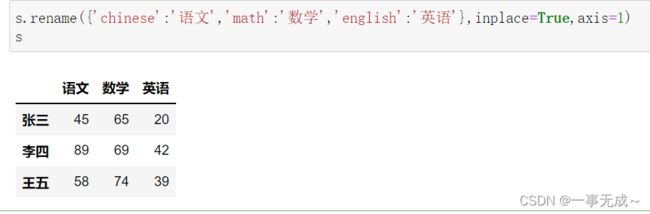
print('---------------------------------------------------------修改行索引')
print('---------------1 直接使用 index属性')
s.index=['小明','小虎','小狗']
print('---------------2 使用 rename方法')
s.rename({'小明':'张三','小虎':'李四','小狗':'王五'},inplace=True,axis=0)



数据内容的修改
print('----------------------------------------------------------修改数据内容')
print('-------------------------修改一整行')
s.loc['张三']=[10,10,10] / s.iloc[0,:]=[10,10,10]
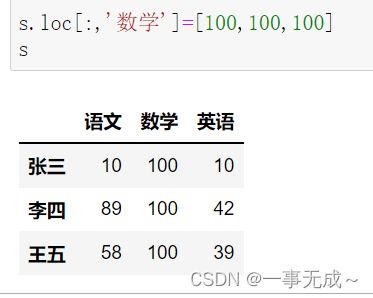
print('-------------------------修改一整列')
s['数学']=[100,100,100] s.loc[:,'数学']=[100,100,100]
print('-------------------------修改某一处')
s.loc['李四','语文']=80或s.iloc[1,0]=80

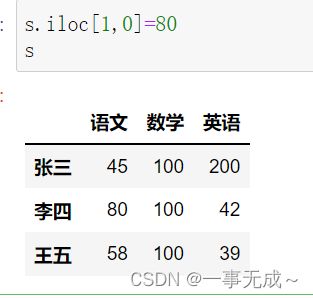
删除数据drop()
print('------------------------------------------------------------------删除列数据')
s.drop(['语文'],axis=1,inplace=True)
s.drop(columns='英语',inplace=True)
s.drop(labels='数学',axis=1,inplace=True)
print('------------------------------------------------------------删除行数据')
s.drop(['张三'],axis=0,inplace=True)
s.drop(index='李四',inplace=True)
s.drop(labels='王五',axis=0,inplace=True)



条件删除print('------------------------------------------------------------条件删除')
s.drop(s[s['语文']<=60].index[0],inplace=True)
#语文成绩中小于60的,有张三和王五,删除行索索引1的王五

数据清洗(缺失值和重复值的处理)

查看缺失值以及判断缺失值
导入数据
import pandas as pd
pd.set_option('display.unicode.east_asian.width',True)
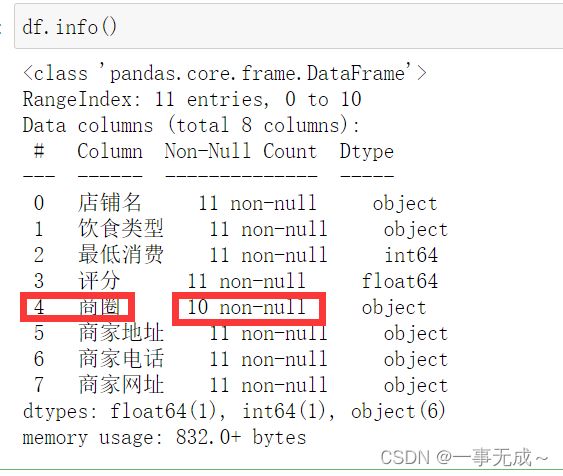
df=pd.read_excel('美团商家数据.xlsx')#查看是否有缺失值
df.info()
print('------------------判断缺失值')
df.isnull()
df.notnull()

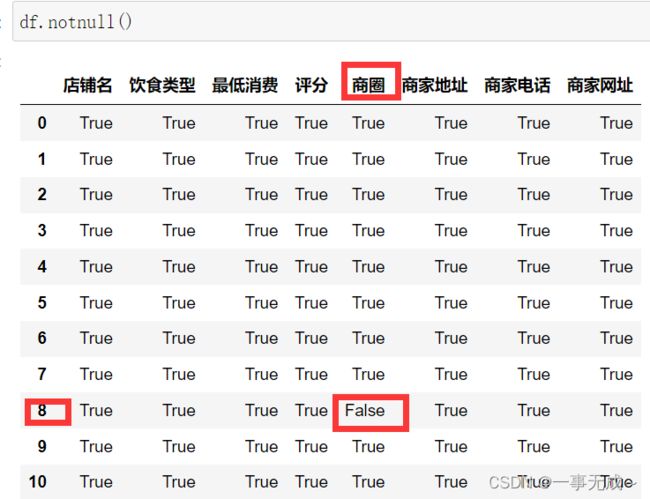
缺失值的处理方式
删除
df=df.dropna() # 第八条数据删除了
填充
df['商圈']=df['商圈'].fillna(' ')
df.iloc[8,4]


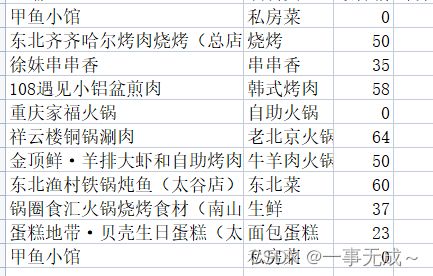
重复值处理
原数据部分展示
判断是否有重复值(第一条和最后一条重复)
df.duplicated()
删除全部重复的数据
df.drop_duplicates()
#最后一条就被删除了
print('-------------------------删除有指定列重复的全部数据')
df.drop_duplicates(['列名'])
#假设有三行数据在该列的内容一致 则会删除后两行数据


索引设置

重新设置索引
●df.reindex(labels=None,index= None,column= None,axis=None,method=None,fill_ _value=nan)
import pandas as pd
print('------------------------------------------------------------series')
s=pd.Series(data=[10,20,30],index=[1,2,3])
print(s)
print('-----------------------------重新设置索引')
print(s.reindex(range(1,6)))#多出的两个为nan
print('---------------------------------------')
print(s.reindex(range(1,6),fill_value=0))#使用0填充
print('---------------------------------------')
print(s.reindex(range(1,6),method='ffill'))#向前填充
print('---------------------------------------')
print(s.reindex(range(1,6),method='bfill'))#向后填充重点讲解dataframe
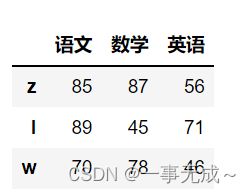
df=pd.DataFrame( data=[[85,87,56],[89,45,71],[70,78,46]], index=['z','l','w'], columns=['语文','数学','英语'] )
print('-----------------------------重新设置行索引')
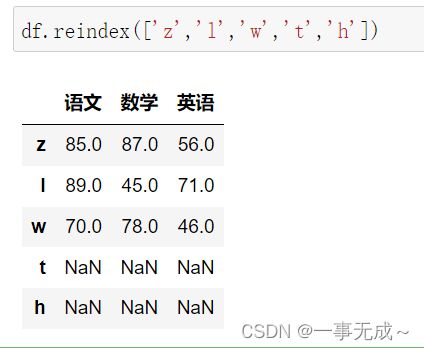
df.reindex(['z','l','w','t','h'])
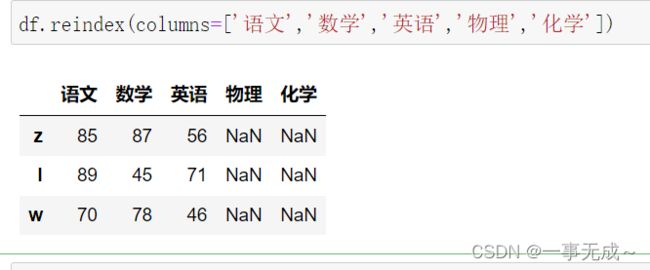
print('-----------------------------重新设置列索引')
df.reindex(columns=['语文','数学','英语','物理','化学'])
print('-----------------------------同时设置行列索引')
df.reindex(index=['z','l','w','t','h'],columns=['语文','数学','英语','物理','化学'],fill_value=0)

设置某列为行索引
df.set_ index()

●数据清洗后重新设置连续索引
df.reset_ _index()
df.reset_index(drop=True)
#其效果就是 比如之前存在重复数据删除后会导致索引不连续,使用该方法可以使不连续的索引变得连续 如下图

数据的排序和排名
数据的排序sort_values()方法

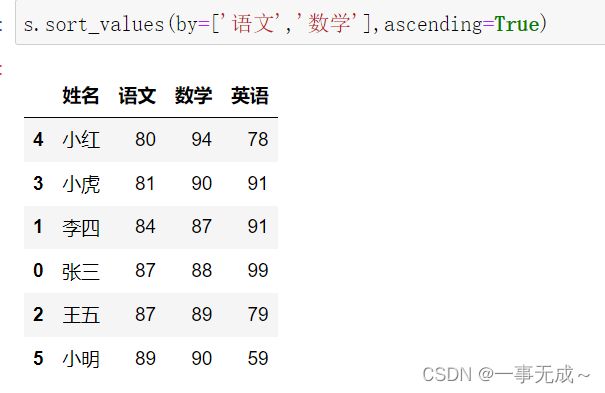
s.sort_values(by='语文',ascending=True)
s.sort_values(by=['语文','数学'],ascending=True)

数据的排名 rank()
先排序后排名
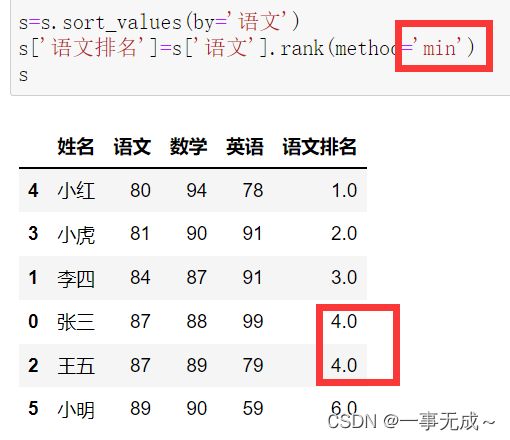
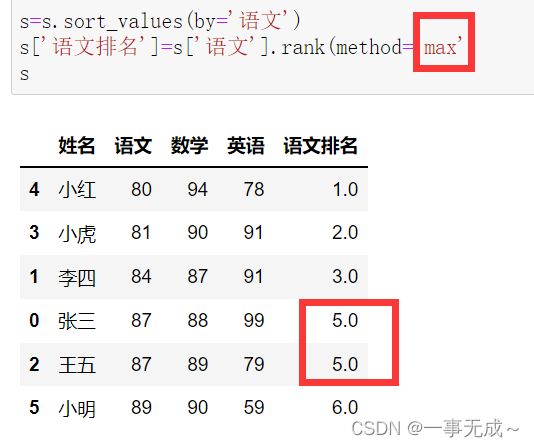
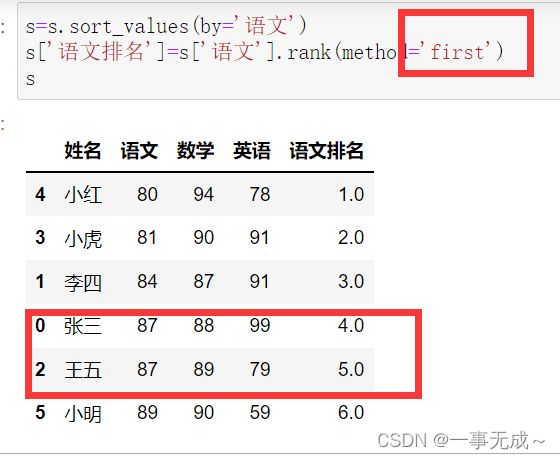
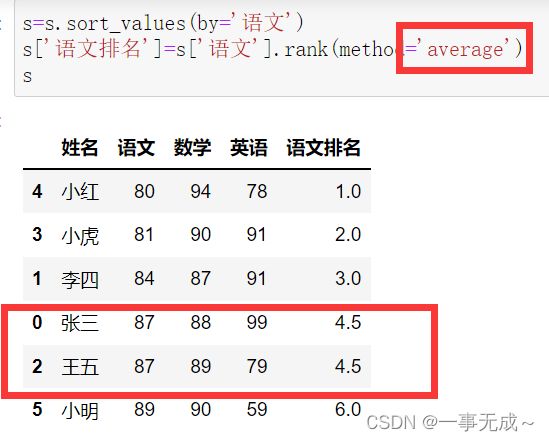
s=s.sort_values(by='语文')
s['语文排名']=s['语文'].rank(method='min')
s['语文排名']=s['语文'].rank(method='max')
s['语文排名']=s['语文'].rank(method='first')
s['语文排名']=s['语文'].rank(method='average')
数据的计算(求和方差等)

from warnings import simplefilter
simplefilter(action="ignore",category=FutureWarning)
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
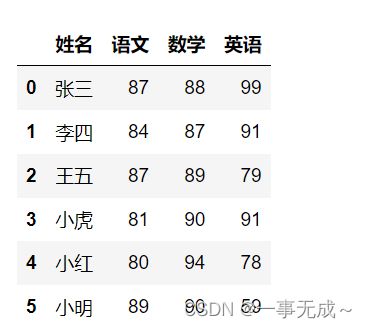
s=pd.read_excel('数据排序.xlsx')
# print(s)
# 姓名 语文 数学 英语
# 0 张三 87 88 99
# 1 李四 84 87 91
# 2 王五 87 89 79
# 3 小虎 81 90 91
# 4 小红 80 94 78
# 5 小明 89 90 5
print('-------------------------------------------------------------求和')
s['总成绩']=s.sum(axis=1)
print(s)
print('-------------------------------------------------------------求均值')
s.loc['6']=['均值']+list(s.iloc[0:6,1:].mean(axis=0))
print(s)
print('-------------------------------------------------------------最大值')
s.loc['7']=['最大值']+list(s.iloc[0:6,1:].max(axis=0))
print(s)
print('-------------------------------------------------------------最小值')
s.loc['8']=['最低分']+list(s.iloc[0:6,1:].min())
print(s)
print('-------------------------------------------------------------中位数')
s.loc['9']=['中位数']+list(s.iloc[0:6,1:].median())
print(s)
print('-------------------------------------------------------------众数')
s.loc['10']=['众数']+list(s.iloc[0:6,1:].mode().loc[0])
print(s)
print('-------------------------------------------------------------方差')
# var()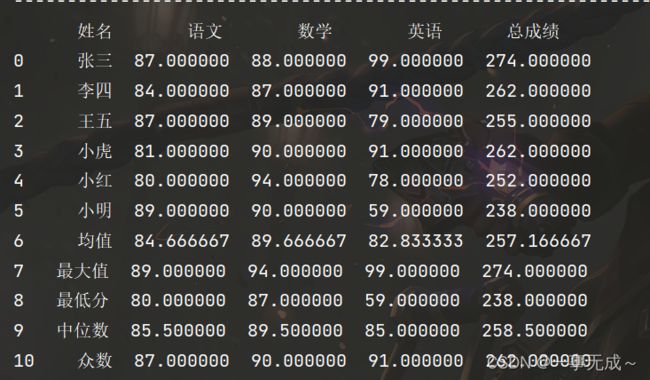
数据格式化
 设置小数位数
设置小数位数
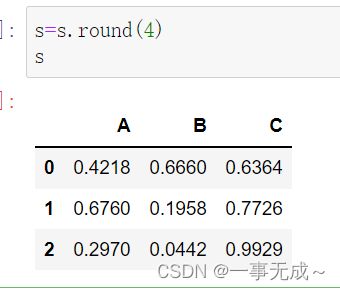
s.round()
import pandas as pd
import random
s=pd.DataFrame(data=[[random.random() for i in range(0,3)],[random.random() for i in range(0,3)],[random.random() for i in range(0,3)]],columns=['A','B','C'])
s
s=s.round(4)
s
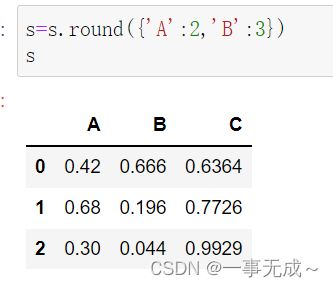
指定列
s=s.round({'A':2,'B':3})
s
方法三 使用函数
s=s.applymap(lambda x:'{:.2f}'.format(x))
s


设置千位分隔符
import pandas as pd
s=pd.DataFrame(data={
'name':['电脑','汽车','手机'],
'价格':[18888,888888,8888]
})
s
s['价格']=s['价格'].apply(lambda x:format(int(x),','))
s


设置百分比
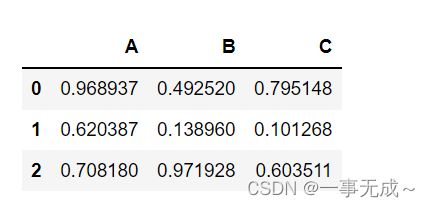
import pandas as pd
import random
s=pd.DataFrame(data=[[random.random() for i in range(0,3)],[random.random() for i in range(0,3)],[random.random() for i in range(0,3)]],columns=['A','B','C'])
s
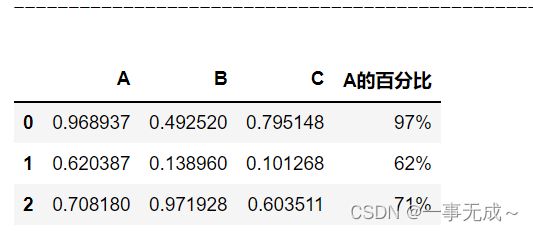
使用apply()
s['A的百分比']=s['A'].apply(lambda x:format(x,'.0%'))
s
使用map()
s['A的百分比']=s['A'].map(lambda x:format(x,'.0%'))
s

apply() applymap() map() 区别
1.apply()和applymap()可以用在Series,对series每个元素都执行一次函数;
也可以用于dataframe,对其每个对象起作用,但也可以控制作用于某一列或者是某一行,或每个元素;
2.map()只可以用在Series对象中。
map()参数可以是函数也可以是字典,比如
s=s.map({'male':'男','female':'女'})

或者使用函数同样可以达到效果
def aa(x):
if x=='nan':
return 'male'
else:
return 'female'
s=s.map(aa)
数据分组统计分析groupby()
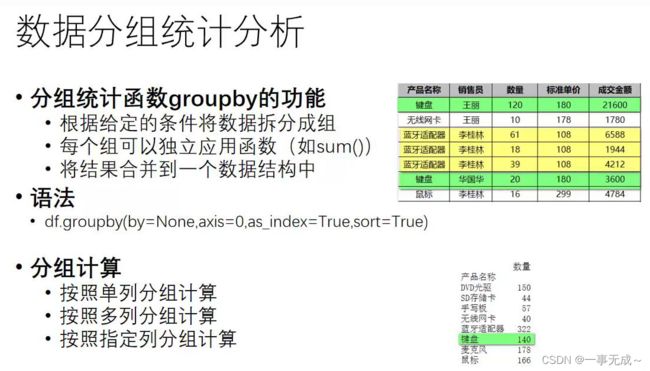
as_index=True 则使用分组的标签作为行索引 sort=True 则会对分组后的数据进行排序
as_index=False,sort=False 默认都是False
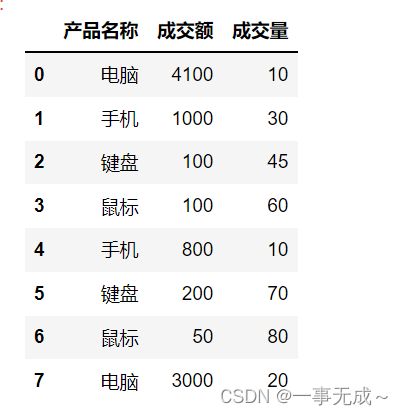
import pandas as pd
s=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑'],
'成交额':[4100,1000,100,100,800,200,50,3000],
'成交量':[10,30,45,60,10,70,80,20]
})
s
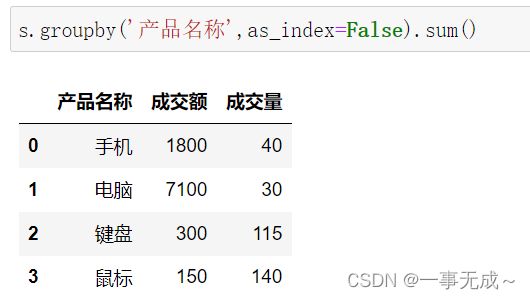
按照一列进行分组 #对量和价都进行求和统计
s.groupby('产品名称',as_index=False).sum()
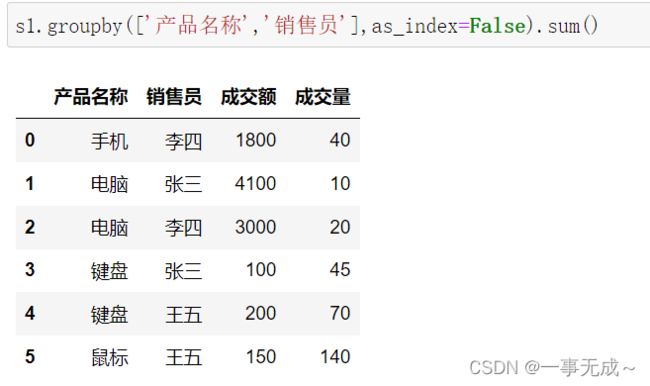
按照多列进行分组
s1=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑'],
'销售员':['张三','李四','张三','王五','李四','王五','王五','李四'],
'成交额':[4100,1000,100,100,800,200,50,3000],
'成交量':[10,30,45,60,10,70,80,20]
})
s1
s1.groupby(['产品名称','销售员'],as_index=False).sum()
分组对指定列列进行计算
s.groupby('产品名称',as_index=False)['成交量'].sum()


分组数据的迭代
通过for循环对分组统计数据进行迭代(遍历分组数据)
import pandas as pd
s=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑'],
'成交额':[4100,1000,100,100,800,200,50,3000],
'成交量':[10,30,45,60,10,70,80,20]
})
s
单列分组数据的迭代
s1=s.groupby('产品名称')
for name,group in s1:
print(name)
print(group)
print('-------------------------')
多列分组数据的迭代
s2=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑']
'销售员':['张三','李四','张三','王五','李四','王五','王五','李四'],
'成交额':[4100,1000,100,100,800,200,50,3000],
'成交量':[10,30,45,60,10,70,80,20] })
s3=s2.groupby(['产品名称','销售员'])for (n1,n2),group in s3:
print(n1,n2)
print(group)
print('-------------------------')




对分组的某列或多列使用聚合函数
通过groupby()与agg()函数
常用的函数函数, sum(),mean(),max(),min()等
import pandas as pd
s=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑','手机'],
'销售员':['张三','李四','张三','王五','李四','王五','王五','李四','张三'],
'成交额':[4100,1000,100,100,800,200,50,3000,700],
'成交量':[10,30,45,60,10,70,80,20,15]
})
s1=s[['产品名称','成交量']]
print(s1)
# 产品名称 成交量
# 0 电脑 10
# 1 手机 30
# 2 键盘 45
# 3 鼠标 60
# 4 手机 10
# 5 键盘 70
# 6 鼠标 80
# 7 电脑 20
# 8 手机 15
print('----------------------------------对单列使用聚合函数')
a=s1.groupby('产品名称').agg(['sum','mean'])
print(a)
# 成交量
# sum mean
# 产品名称
# 手机 55 18.333333
# 电脑 30 15.000000
# 键盘 115 57.500000
# 鼠标 140 70.000000
print('----------------------------------对不同列使用不同聚合函数')
s2=s[['产品名称','成交量','成交额']]
print(s2)
# 产品名称 成交量 成交额
# 0 电脑 10 4100
# 1 手机 30 1000
# 2 键盘 45 100
# 3 鼠标 60 100
# 4 手机 10 800
# 5 键盘 70 200
# 6 鼠标 80 50
# 7 电脑 20 3000
# 8 手机 15 700
a=s2.groupby('产品名称').agg({'成交量':['sum','max'],'成交额':['sum','max','mean']})
print(a)
# 成交量 成交额
# sum max sum max mean
# 产品名称
# 手机 55 30 2500 1000 833.333333
# 电脑 30 20 7100 4100 3550.000000
# 键盘 115 70 300 200 150.000000
# 鼠标 140 80 150 100 75.000000通过字典和Series对象进行分组统计
1.通过字典进行分组统计
2.通过Series进行分组统计需求 对如下数据进行分组
1.通过字典进行分组统计
dict1={
'北京销量':'华北地区',
'上海销量':'华东地区',
'广州销量':'华南地区',
'天津销量':'华北地区',
'苏州销量':'华东地区',
'沈阳销量':'华北地区'
}
s1=s.groupby(dict1,axis=1).sum()
s1
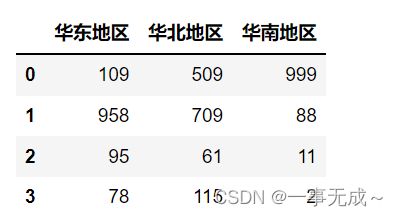
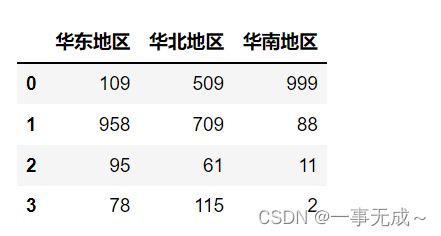
2.通过Series进行分组统计
p=pd.Series(data=['华北地区','华东地区','华南地区','华北地区','华东地区','华北地区'],index=['北京销量','上海销量','广州销量','天津销量','苏州销量','沈阳销量'])
s1=s.groupby(p,axis=1).sum()
s1
数据移位 .shift()
作用:例如可以计算月份之间销售差

import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
s=pd.DataFrame(data={
'销量':[4699,1456,8887,4441,666]
},index=['一月','二月','三月','四月','五月'])
print(s)
s['销售差']=s['销量']-s['销量'].shift()
print(s)数据转换
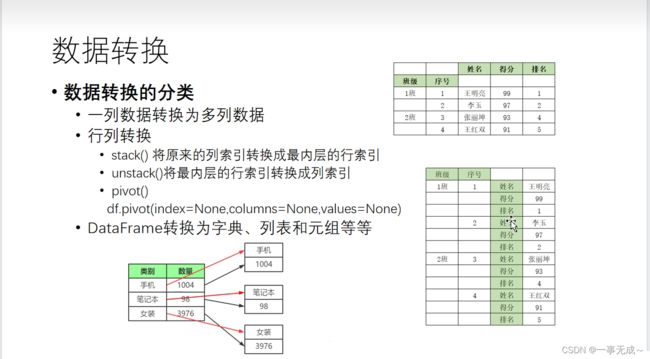
数据转换的分类
一列数据转换为多列数据
行列转换
DataFrame转换为字典、列表和元组等等
语法
Series.str.split(pat=None,n=-1,expand=False)
参数说明:
pat : 字符串符号或正则表达式,表示字符串分割的数据,默认以空格分割
n:整型、分割次数,默认值是-1。0或-1都将返回所有拆分的字符串
expand:布尔型,分割后的结果是否转换为DataFrame,默认值是False
一列数据转换为多列数据
案列一 (把一串地址分割成省市区 )#信息均为捏造
import pandas as pd
pd.set_option('display.width',1000)
pd.set_option('display.max_columns',500)
s=pd.DataFrame(data=[['李明玉','15974201351','陕西省 西安市 长安中路888号西安音东学院教研中心'],
['张凤香','13993355162','河北省 唐山市 乐亭县财富大街990号'],
['王红军','15850914728','上海市 浦东新区 快乐路867快乐城市1111号8808室'],
['牛霸','13599745669','河北省 唐山市 开发区喜庆道100号'],
['马明','15018711991','台湾省 台北市 开发区经济路101号'],
['昊尹明','18194186347','辽宁省 抚顺市 顺城区太重阳北路1号楼2单元606'],
['欧阳丽','15857069909','山东省 临沂市 河东区正阳北路国科石油分公司'],
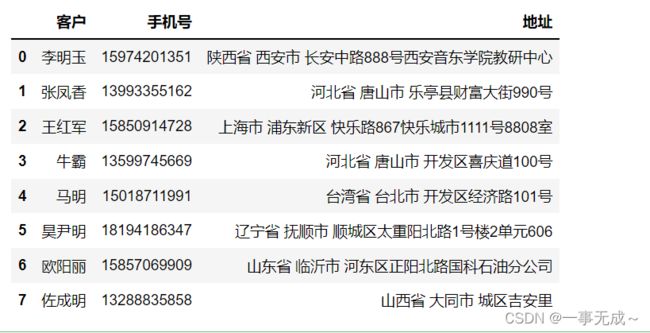
['佐成明','13288835858','山西省 大同市 城区吉安里']],columns=['客户','手机号','地址'])
s
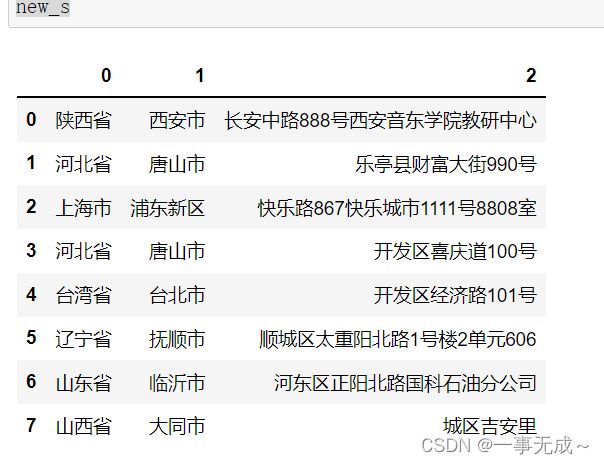
new_s=s['地址'].str.split(' ',expand=True)
s['省']=new_s[0]
s['市']=new_s[1]
s['区']=new_s[2]
s

案例二:元组数据进行分割
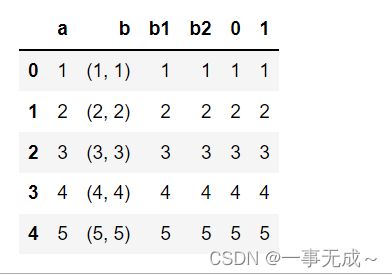
df=pd.DataFrame(data={
'a':[1,2,3,4,5],
'b':[(1,1),(2,2),(3,3),(4,4),(5,5)]
})
df
df[['b1','b2']]=df['b'].apply(pd.Series)
df
df=df.join(df['b'].apply(pd.Series))
df


行列转换

案例代码:
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
s=pd.DataFrame(data=[
['1','1班','王*亮','84','11'],
['2','1班','杨**','82','17'],
['3','1班','王*彬','78','37'],
['4','2班','赛*琪','77','51'],
['5','2班','刘**','76','64'],
['6','2班','刘*彤','74','89']
],columns=['序号','班级','姓名','得分','排名'])
print(s)
# 序号 班级 姓名 得分 排名
# 0 1 1班 王*亮 84 11
# 1 2 1班 杨** 82 17
# 2 3 1班 王*彬 78 37
# 3 4 2班 赛*琪 77 51
# 4 5 2班 刘** 76 64
# 5 6 2班 刘*彤 74 89
s=s.set_index(['班级','序号'])
print(s)
# 姓名 得分 排名
# 班级 序号
# 1班 1 王*亮 84 11
# 2 杨** 82 17
# 3 王*彬 78 37
# 2班 4 赛*琪 77 51
# 5 刘** 76 64
# 6 刘*彤 74 89
print('-----------------------------------------将原来的列索引转换成最内层的行索引')
s=s.stack()
print(s)
# 班级 序号
# 1班 1 姓名 王*亮
# 得分 84
# 排名 11
# 2 姓名 杨**
# 得分 82
# 排名 17
# 3 姓名 王*彬
# 得分 78
# 排名 37
# 2班 4 姓名 赛*琪
# 得分 77
# 排名 51
# 5 姓名 刘**
# 得分 76
# 排名 64
# 6 姓名 刘*彤
# 得分 74
# 排名 89
# dtype: object
print('------------------------------------------------将最内层的行索引转换成列索引')
s=s.unstack()
print(s)
# ------------------------------------------------------将最内层的行索引转换成列索引
# 姓名 得分 排名
# 班级 序号
# 1班 1 王*亮 84 11
# 2 杨** 82 17
# 3 王*彬 78 37
# 2班 4 赛*琪 77 51
# 5 刘** 76 64
# 6 刘*彤 74 89
print('-------------------------------------------------------------行列转换pivot')
s=pd.DataFrame(data=[
['1','1班','王*亮','84','11'],
['2','1班','杨**','82','17'],
['3','1班','王*彬','78','37'],
['4','2班','赛*琪','77','51'],
['5','2班','刘**','76','64'],
['6','2班','刘*彤','74','89']
],columns=['序号','班级','姓名','得分','排名'])
print(s)
# # 序号 班级 姓名 得分 排名
# 0 1 1班 王*亮 84 11
# 1 2 1班 杨** 82 17
# 2 3 1班 王*彬 78 37
# 3 4 2班 赛*琪 77 51
# 4 5 2班 刘** 76 64
# 5 6 2班 刘*彤 74 89
print(s.pivot(index='序号',columns='班级',values='得分'))
# 班级 1班 2班
# 序号
# 1 84 NaN
# 2 82 NaN
# 3 78 NaN
# 4 NaN 77
# 5 NaN 76
# 6 NaN 74DataFrame转换为字典、列表和元组
示例:
import pandas as pd
s=pd.DataFrame(data={
'产品名称':['电脑','手机','键盘','鼠标','手机','键盘','鼠标','电脑'],
'成交额':[4100,1000,100,100,800,200,50,3000],
'成交量':[10,30,45,60,10,70,80,20]
})
s

转字典:
mydict=s.to_dict()
for i in mydict:
print(i,':',mydict[i])

转列表:
a=s.values.tolist()

转元组
t=[tuple(x) for x in s.values]
for i in t:
print(i)


数据合并
merge()
merge方法一对一合并
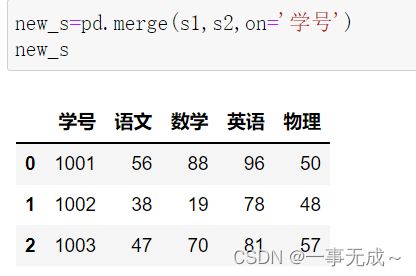
import pandas as pd
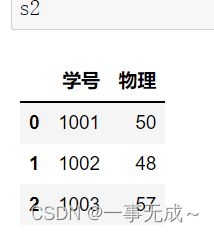
s1=pd.DataFrame(data={ '学号':[1001,1002,1003], '语文':[56,38,47], '数学':[88,19,70], '英语':[96,78,81] })
s2=pd.DataFrame(data={ '学号':[1001,1002,1003], '物理':[50,48,57] })
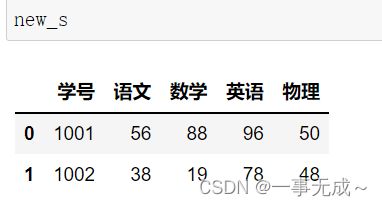
new_s=pd.merge(s1,s2,on='学号')
print(new_s)

左连接
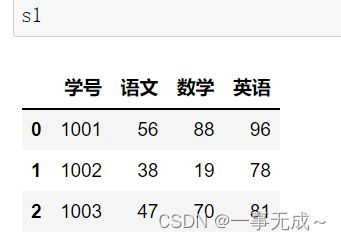
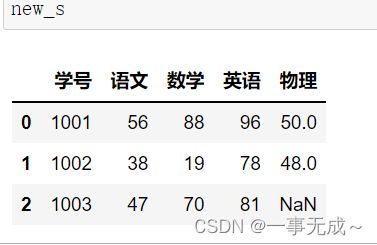
s1=pd.DataFrame(data={ '学号':[1001,1002,1003], '语文':[56,38,47], '数学':[88,19,70], '英语':[96,78,81] })
s2=pd.DataFrame(data={ '学号':[1001,1002], '物理':[50,48] }) new_s=pd.merge(s1,s2,how='left',on='学号')

右连接
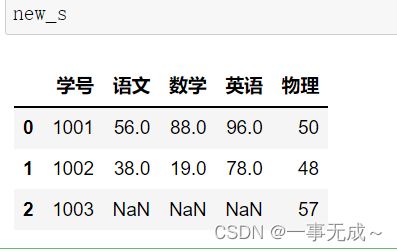
s1=pd.DataFrame(data={
'学号':[1001,1002],
'语文':[56,38],
'数学':[88,19],
'英语':[96,78]
})
s2=pd.DataFrame(data={
'学号':[1001,1002,1003],
'物理':[50,48,57]
})
new_s=pd.merge(s1,s2,how='right',on='学号')


内连接 外连接
s1=pd.DataFrame(data={
'学号':[1001,1002,1003],
'语文':[56,38,47],
'数学':[88,19,70],
'英语':[96,78,81]
})
s2=pd.DataFrame(data={
'学号':[1001,1002,1004],
'物理':[50,48,57]
})
new_s=pd.merge(s1,s2,how='inner',on='学号')
外连接:new_s=pd.merge(s1,s2,how='outer',on='学号')



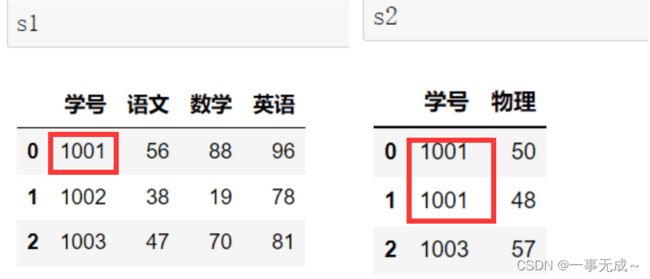
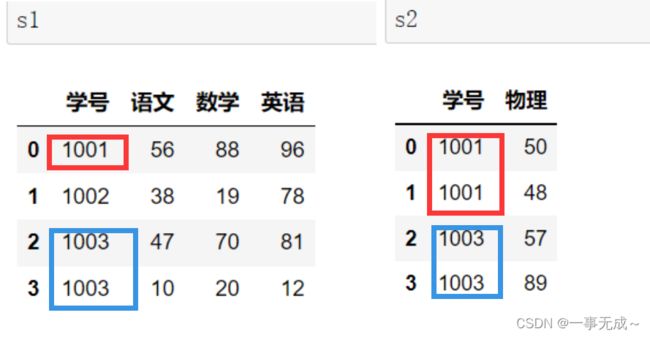
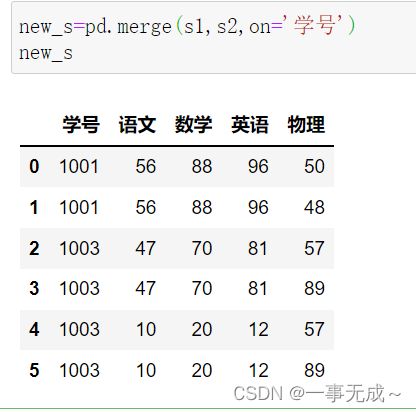
多对多或者多对一合并

concat()
语法:pd.concat(objs,axis=0,join='outer',ignore_index=False,keys=None)
参数说明:
objs:Series、DataFrame的对象等
axis:axis=1表示行, axis=0表示列,默认为0
join:值为inner(交集)或outer(联合).默认为outer
ignore_index:默认为False,保留行索引,如是不保留行索引,则为True
keys:使用传递的键作为最外层构建层次索引
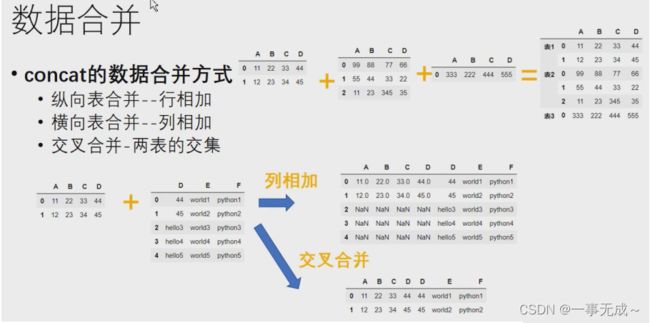
纵向合并
keys:使用传递的键作为最外层构建层次索引
ignore_index:默认为False,保留行索引,如是不保留行索引,则为True

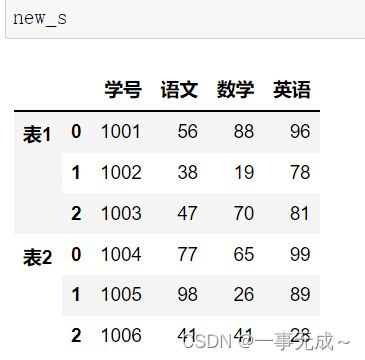
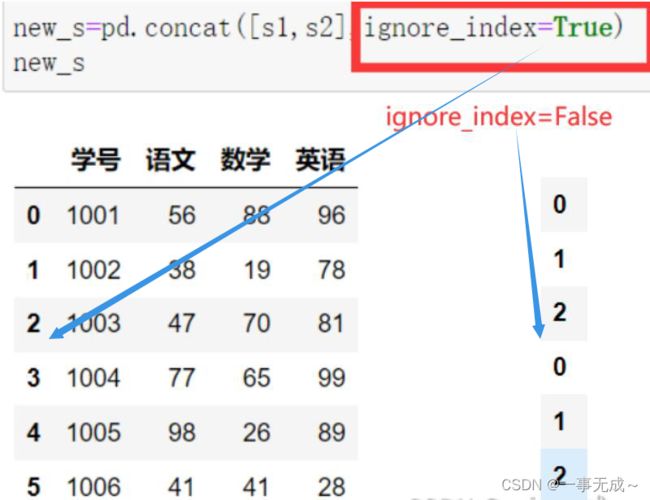
横向合并
s1=pd.DataFrame(data={ 'A':['1001','1002','1003'], 'B':['56','38','47'], 'C':['88','19','70'], 'D':['96','78','81'] }) s2=pd.DataFrame(data={ 'D':['a','b','e','f'], 'E':['c','d','h','j'] })new_s=pd.concat([s1,s2],axis=1)

交叉合并
s1=pd.DataFrame(data={ 'A':['1001','1002','1003'], 'B':['56','38','47'], 'C':['88','19','70'], 'D':['a','b','e'] }) s2=pd.DataFrame(data={ 'D':['a','b','e','f'], 'E':['c','d','h','j'] }) new_s=pd.concat([s1,s2],axis=1,join='inner')


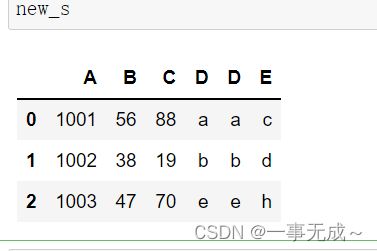
数据导出
导出数据为Excel文件
df.to_excel()
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
s1=pd.DataFrame(data={
'学号':[1001,1002,1003],
'语文':[56,38,47],
'数学':[88,19,70],
'英语':[96,78,81]
})
print(s1)
s1.to_excel('数据导出.xlsx',index=False)#index=False 不要索引
# s1.to_excel('数据导出.xlsx',index=False,sheet_name='demo1')#
print('----------------------------------------------导出到多个sheet表')
# 打开一个excel文件
work=pd.ExcelWriter('导出到多个sheet表.xlsx')
s1.to_excel(work,index=False,sheet_name='所有成绩表')#
s1[['学号','语文']].to_excel(work,index=False,sheet_name='语文成绩表')#
# 保存
work.save()
导出数据为CSV文件
df.to_csv(path_or_buf,sep=',',float_format=None,columns=None,header=True,index=True) 参数说明
path_or_buf:要保存的路径及文件名 sep:分隔符,默认为逗号
float_format:浮点数的输出格式
columns:指定要导出的列,用列名、列表表示,默认值为None. header:是否输出列名,默认值为True
index:是否输出索引,默认值为True
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
s1=pd.DataFrame(data={
'学号':['1001','1002','1003'],
'语文':[56.12,38.36,47.89],
'数学':[88,19,70],
'英语':[96,78,81]
})
print(s1)
s1.to_csv('数据导出.csv',index=False,columns=['学号','语文','数学','英语'],float_format='%.1f')日期数据处理
日期数据转换
pd.to_datetime()
多列组合日期



import pandas as pd
s=pd.DataFrame(data={
'原数据':['14-Feb-20','02/14/2020','2020.02.14','2020/02/14','20200214']
})
print(s)
print('--------------------------------------------日期转换')
s1=pd.to_datetime(s['原数据'])
print(s1)
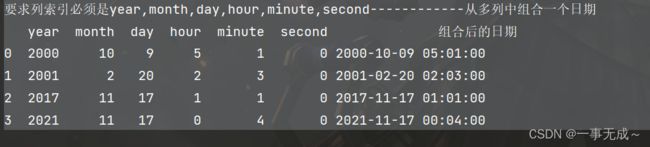
print('要求列索引必须是year,month,day,hour,minute,second------------从多列中组合一个日期')
s2=pd.DataFrame(data={
'year':[2000,2001,2017,2021],
'month':[10,2,11,11],
'day':[9,20,17,17],
'hour':[5,2,1,0],
'minute':[1,3,1,4],
'second':[0,0,0,0]
})
s2['组合后的日期']=pd.to_datetime(s2)
print(s2)dt对象的使用

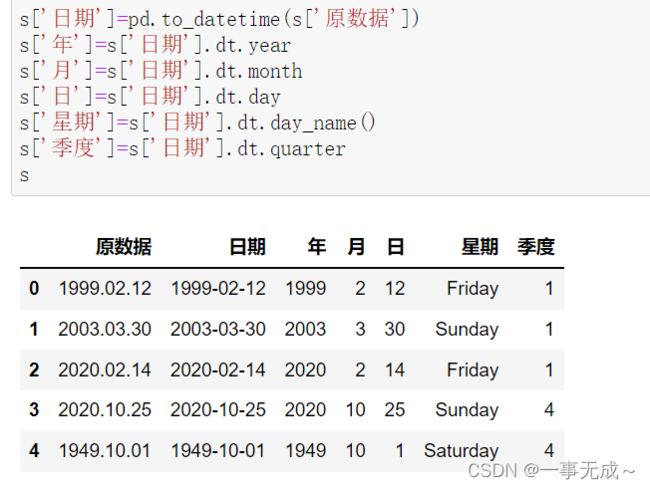
import pandas as pd
s=pd.DataFrame(data={
'原数据':['1999.02.12','2003.03.30','2020.02.14','2020.10.25','1949.10.01']
})
s
s['日期']=pd.to_datetime(s['原数据'])
s['年']=s['日期'].dt.year
s['月']=s['日期'].dt.month
s['日']=s['日期'].dt.day
s['星期']=s['日期'].dt.day_name()
s['季度']=s['日期'].dt.quarter

获取日期区间数据

获取1999年的数据
s.loc['1999']
获取某月数据
获取某段时间的数据



按时期统计并显示数据
按时期统计数据 df.resample()

import pandas as pd
s=pd.read_excel('d24_数据.xlsx')
s=s.sort_values(by=['日期'])
s=s.set_index('日期')
print(s)
print('------------------------------------------------------------------按年-')
s1=s.resample('AS').sum()
print(s1)
print('------------------------------------------------------------------按季度-')
s1=s.resample('Q').sum()
print(s1)
print('------------------------------------------------------------------按月-')
s1=s.resample('M').sum()
print(s1)
print('------------------------------------------------------------------按星期-')
s1=s.resample('W').sum()
print(s1)
print('------------------------------------------------------------------按天-')
s1=s.resample('D').sum()
print(s1)按时期显示数据 df.to_period()
import pandas as pd
s=pd.read_excel('d24_数据.xlsx')
s=s.sort_values(by=['日期'])
s=s.set_index('日期')
print(s)
print('------------------------------------------------------------------按年-')
s1=s.to_period('A')
print(s1)
print('------------------------------------------------------------------按季度-')
s1=s.to_period('Q')
print(s1)
print('------------------------------------------------------------------按月-')
s1=s.to_period('M')
print(s1)
print('------------------------------------------------------------------按星期-')
s1=s.to_period('W')
print(s1)
print('------------------------------------------------------------------按天-')
s1=s.to_period('D')
print(s1)
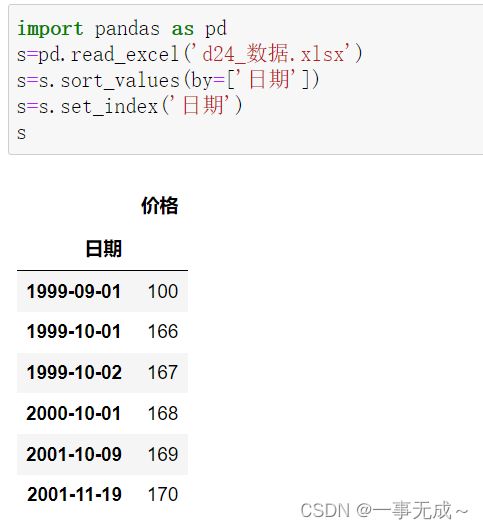
先统计后显示
import pandas as pd
s=pd.read_excel('d24_数据.xlsx')
s=s.sort_values(by=['日期'])
s=s.set_index('日期')
print(s)
价格
日期
1999-09-01 100
1999-10-01 166
1999-10-02 167
2000-10-01 168
2001-10-09 169
2001-11-19 170
print('------------------------------------------------------------------按年-')
s1=s.resample('AS').sum().to_period('A')
print(s1)
print('------------------------------------------------------------------按季度-')
s1=s.resample('Q').sum().to_period('Q')
print(s1)
print('------------------------------------------------------------------按月-')
s1=s.resample('M').sum().to_period('M')
print(s1)
print('------------------------------------------------------------------按星期-')
s1=s.resample('W').sum().to_period('W')
print(s1)
print('------------------------------------------------------------------按天-')
s1=s.resample('D').sum().to_period('D')
print(s1)时间序列 pandas.date_range()
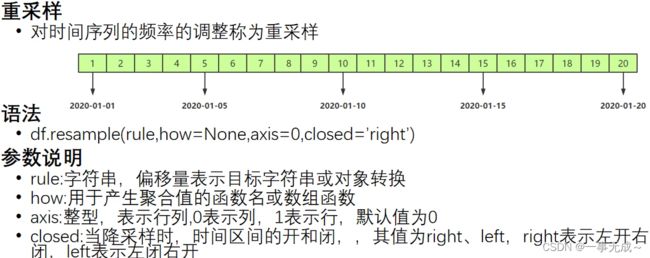
pandas.date_range()函数 生成一个固定频率的时间索引
语法
pd.date_range(start=None,end=None,periods=None,freq='D')
参数说明
必须指定start、end、periods中的两个参数值 periods:固定时期,取值为整数或None
freq:日期偏移量,取值为string或DateOffset,默认为'D',取值可为
D:日历日频率
W:每周频率 M:月末频率 H:每小时频率 T:分钟的频率 S:秒钟的频率
import pandas as pd
s=pd.date_range(start='2022-01-01',periods=10,freq='W')
k=pd.DataFrame(s)
print(k)
# 0
# 0 2022-01-02
# 1 2022-01-09
# 2 2022-01-16
# 3 2022-01-23
# 4 2022-01-30
# 5 2022-02-06
# 6 2022-02-13
# 7 2022-02-20
# 8 2022-02-27
# 9 2022-03-06时间序列重采样
import pandas as pd
s=pd.date_range(start='2022-1-1',periods=9,freq='T')
a=pd.Series(data=range(9),index=s)
print(a)
print('--------------------------------------产生3分钟的序列')
a=a.resample(rule='3T').sum()
print(a)

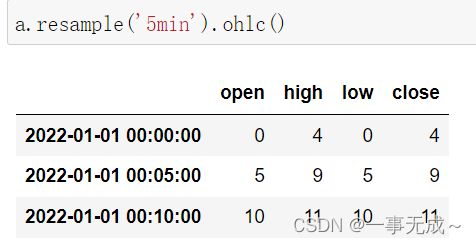
时间序列数据汇总 resample().ohlc()
import pandas as pd
s=pd.date_range(start='2022-1-1',periods=12,freq='T')
a=pd.Series(data=range(12),index=s)
aa.resample('5min').ohlc()

移动窗口数据计算 df.rolling()
df.rolling(windows,min_periods=None,axis=0)
import pandas as pd
s=pd.date_range(start='2022-1-1',periods=12,freq='D')
a=pd.Series(data=[2,6,4,5,6,9,7,3,2,4,5,6],index=s)
a
print('---------------------------------------计算3天的均值')
a.rolling(3,min_periods=1).mean()

