一文讲透预训练模型的改进训练算法 ,轻松达到State of the Art


“随着BERT在NLP各种任务上取得骄人的战绩,预训练模型在不到两年的时间内得到了很大的发展。BERT和Open-GPT等预训练语言模型的引入,使整个自然语言研究界发生了革命性的变化。然而,与它们巨大的好处相比,研究人员对它们的理论和经验性质仍然知之甚少。本文回顾了有关预训练深度神经网络的相关文献及观点,以及带有词嵌入的微调策略。针对已有的两种主流算法NFT-TM和FT-NTM,综合考虑了在预训练语言模型上建立一个上层网络,并以适当的方式对两者进行微调的可能性,提出了一种新算法FT-TM。通过对一系列NLP任务的实验结果分析,比较了算法FT-TM和FT-NTM的效果,证明了新算法FT-TM的优势。

大数据产业创新服务媒体
——聚焦数据 · 改变商业
在NLP的预训练语言模型时代,针对已有的两种主流算法NFT-TM和FT-NTM,本文提出了一种新算法FT-TM。它首先在BERT的基础上建立一个上层神经网络(LSTM或者CNN等等),然后在适当的策略下对两者进行同时训练。该算法融合了NFT-TM和FT-NTM两种算法的优势,通过一系列NLP任务的实验结果表明,新算法FT-TM能取得更好的效果,而且在公开的Quora和SLNI两个问题语义等价数据集上,新算法FT-TM的效果都达到了目前的State of the Art。
01
引 言
诸如BERT[1]和Open-GPT[2]等预训练语言模型的引入,为NLP研究和工业界带来了巨大的进步,这些模型的贡献可以分为两个方面。首先,经过预训练的语言模型使建模人员可以利用少量数据获得合理的准确性,这种策略与经典的深度学习方法相反,经典的深度学习方法需要大量的数据才能达到可比的结果。其次,对于许多NLP任务,例如SQuAD [4],CoQA[5],命名实体识别[6],Glue[7],机器翻译[8],预训练的模型如果给定合理数量的标记数据,可以创造新的State of the Art。
在预训练语言模型时代,新的技术会遵循两个方向发展,第一个方向是改进预训练过程,例如ERNIE[9]和GPT2.0 [2]。第二个方向是在预先训练的语言模型之上构建新的神经网络结构。
目前有三种算法可以在预训练的语言模型之上训练带有上层神经网络的网络结构,如表1所示,其中,算法NFT-TM是指在BERT模型的上层添加复杂的网络结构,在训练时,固定BERT的参数,仅单独训练上层任务模型网络。算法FT-NTM是指在在BERT模型后接一个简单的特定任务层(如全连接网络),在训练时,根据任务的训练样本集对BERT进行fine-tune即可。Peter等[3]比较了算法FT-NTM和NFT-TM的可能性,并得出结论,算法FT-NTM比NFT-TM的效果更好。然而,Peter等[3]没有比较算法FT-TM和FT-NTM。另一方面,在预训练语言模型流行之前,研究人员经常使用与方法FT-TM类似的策略,也就是说,建模人员首先对模型进行训练,直到收敛为止,然后在几个训练周期内对词嵌入进行微调。由于预训练的语言模型类似于词嵌入,那么不考虑算法FT-TM将是不明智的。
在这项研究中,我们的目标是比较算法FT-TM和FT-NTM的效果,更具体地说,我们执行三个NLP任务,包括序列标记、文本分类和句子语义等价性。在第一个任务中,实验结果表明即使不修改网络结构,在预训练语言模型之上构建上层网络也可以提高准确性。在第二个任务中,实验结果表明通过集成不同的神经网络,甚至可以进一步提高微调方法FT-NTM的效果。在最后一项任务中,实验结果表明如果可以定制一个专门适合于预训练语言模型特征的上层神经网络,则可以进一步提高效果。因此,所有实验结果都表明算法FT-TM优于FT-NTM。
表1 基于预训练模型构建上层网络的方法

本文接下来的内容安排如下:首先,我们回顾了有关预训练深度神经网络的相关文献,包括Peter等人的观点[3]以及带有词嵌入的微调策略;其次,我们给出了三个实验的结果,并显示了算法FT-TM与FT-NTM相比,能达到更好的效果,证明了算法FT-TM的优势。
02
文献综述
在引入深度神经网络之前,NLP领域的研究人员一直在使用预训练模型。在它们当中,最著名的是词嵌入,它把每个单词映射到一个连续的向量中,而不是使用one-hot编码[10]。这样,我们不仅可以减少输入函数的维数(这有助于避免过拟合),而且还可以捕获每个单词的内部含义。
但是,由于每个单词在词嵌入中仅被赋予固定的数值矢量,因此词嵌入无法捕获单词在文本中的上下文含义。例如,考虑“苹果”一词,句子“我吃了一个苹果”和“我买了一个苹果电脑”。显然,“ 苹果”一词代表完全不同的含义,而词嵌入技术却无法捕捉到这种语义的差别。
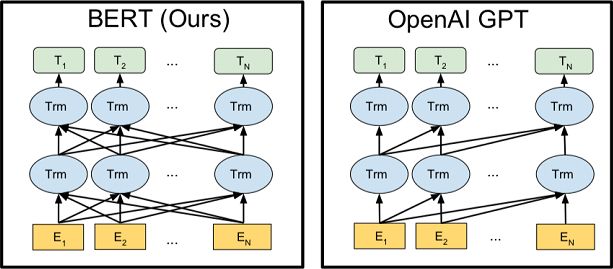
图1 BERT和Open-GPT模型的差异[1]
上述缺陷促使研究人员提出了一种深度神经网络,该网络能够以无监督的方式进行训练,同时能够捕获文本中包含单词的上下文含义。一些早期的尝试包括各种预训练模型,例如基于LSTM [13]构建的ELMo [11]和ULMFiT [12],但是,最成功的是BERT [1]和Open-GPT [2],与ELMo和ULMFiT不同,BERT和Open-GPT构建在Transformer[14]结构之上,不同之处在于BERT使用双向自注意力,而Open-GPT仅使用单向注意力,如图1所示。Transformer的结构与LSTM有两个重要不同,首先,它允许使用残余连接和批处理归一化来连接多层网络,从而允许自由梯度流动。其次,Transformer的核心计算单元是矩阵乘法,这使研究人员可以充分利用TPU的全部计算潜力[15]。经过大型语料库的训练后,BERT和Open-GPT都能够更新许多重要自然语言任务的基准,例如SQuAD [4],CoQA [5],命名为实体识别[6],Glue [7],机器翻译[8]。
在存在预训练语言模型的情况下,那么如何最好地利用预训练模型获得更好的效果呢?在这方面,Peters等[3]研究了如何使用预训练模型最佳地适应目标任务,并提出了两种不同的适应算法:特征提取算法和直接微调预训练模型算法,这对应于表1中的算法NFT-TM和FT-NTM,Peters等进行了五个实验,包括:(1)命名实体识别[6];(2)情绪分析[16];(3)自然语言推论[17];(4)复述检测[18];(5)语义文本相似度[19]。通过执行所有这些任务,Peters等得出的结论是,算法FT-NTM比NFT-TM的效果更好。
Peters等的工作展示了如何应用预训练语言模型,我们认为这方面还需要深入研究。在预训练语言模提出型之前,建模人员通常采用以下策略,首先,他们在词嵌入之上训练了语言模型,通常采用CNN或LSTM的形式,并固定单词嵌入,在训练过程收敛之后,再将词嵌入微调训练几个时期,实验结果显示出该策略可以提高整体预测精度。如果将预训练语言模型视为词嵌入的增强版本,那么可以类似的提高训练效果的算法,更具体地说,就是首先在预训练语言模型之上训练上层神经网络直到某个收敛点,然后联合训练整个神经网络(包括预训练语言模型),这会进一步改善结果。
03
改进训练算法FT-TM
在传统的NLP语言处理中,通常采用的方法是词向量加上层模型的方式。在这个训练的过程中,由于词向量是已经经过大量训练,而上层模型的参数初始化是随机的,所以一般来说,如果直接同时训练词向量的参数和上层模型的参数,其效果将会大打折扣。对于这种情况,常常采用的策略是,首先固定词向量,并训练上层模型若干轮数达到理想效果,然后训练词向量或词向量加上层模型少数epoch。
如果我们将以上思维应用于BERT的话,我们会发现如果我们仅仅是同时训练BERT和上层模型将会产生较差的效果。BERT相比于词向量具备更大的参数,因此如果我们同时训练上层模型和BERT,就会面临两种困境。如果我们采用较小的学习率,上层模型收敛就会较慢,其效果不好。如果我们采用较大的学习率,就会严重破坏已经预训练好的BERT结构。因此我们必须采用其他的方法进行训练。
根据刚刚的分析,我们在本文中提出了一种基于预训练模型和联合调参的改进训练算法FT-TM,在该算法中,首先固定BERT的参数,然后训练上层的模型。在这里上层的模型既可以是比较通用的,例如LSTM和CNN,也可以是其他的模型。当训练达到一定的精度后,再同时开始训练BERT和上层模型,我们发现FT-TM已经可以显著的提高训练的效果。
但是在训练的过程中,有一些问题需要注意,首先如果是对于词向量来说,一般的方法是训练上层模型直至其收敛,换句话说,直至其在验证集上达到的最高的准确率。但是在对BERT进行试验的时候我们发现,这种方法效果并不理想,通过分析其训练集和验证集的预测精度对比,我们发现问题的根源在于可能存在的过拟合现象,这也是有一定直观原因的,从参数数量来说,BERT的参数数量远大于上层模型和常用的NLP模型,所以如果在上层模型精度达到最高后再开始训练,BERT就很有可能导致严重的过拟合。
这点在具体的NLP任务实验中也是很明显的,在实验中,这样的做法下,训练集的精度甚至会达到接近100%,为了解决这个问题,FT-TM中的做法是,不在上层模型收敛后再开始训练BERT和上层模型,而是在其达到一定的准确度就开始这个过程。
除此之外,在训练BERT的时候还会有另外的一种情况,如果BERT预训练语料和目标语料差别较大,就可能BERT在fine-tune的时候收敛很慢。在这种情况下,采用以上的方法进行训练效果并不好,为了应对这种情况,FT-TM中采取的做法是:首先,采用BERT加上全连接层对BERT的参数进行fine-tune,然后再采用前面讲到的措施进行fine-tune。
同时,在句子语义等价的NLP任务上,我们对FT-TM算法进行了进一步的具体化,在具体的实现中,预训练模型采用BERT,上层神经网络基于BIMPM[27]进行了改进,在实验4.3部分会介绍这种方法的效果,目的是说明FT-TM这种联合训练的算法相比FT-NTM能达到更好的效果,甚至能达到业界的State of the Art。在具体介绍算法之前,首先对句子等价的任务进行说明。判断句子是否等价的任务要远远比单纯的词语匹配复杂。举例来说,问题“市政府的管辖范围是什么?”和“市长的管辖范围是什么?”仅有两个字的差异,但两者语义是不相同的,因此其回答也应该不一样的。另一方面来说,“市政府的职责是什么”和“请问,从法律上来讲,市政府究竟可以管哪些事情“这两个问题,除去在“市政府”一词外,几乎是没有任何重合的,但两者语义是等价的,因此其答案也应该是一样的。从这几个例子来看,句子匹配的任务需要模型能够真正理解其句子的语义。
在BERT等预训练模型出现之前,语义本身的表达一般是用word vector来实现。为了得到句子的深层语义表达,所采用的方法往往是在上层架设网络,以BIMPM为例,BIMPM是一种matching-aggregation的方法,它对两个句子的单元做匹配,如经过LSTM处理后得到不同的time step输出,然后通过一个神经网络转化为向量,然后再将向量做匹配。下面来详细介绍一下BiMPM的大体流程,如图中所示,从Word Representation Layer 开始,将每个句子中的每个词语表示成d维向量,然后经过Context Representation Layer 将上下文的信息融合到需要对比的P和Q两个问题中的每个time-step表示。Matching Layer 则会比较问题P和问题Q的所有上下文向量,这里会用到multi-perspective 的匹配方法,用于获取两个问题细粒度的联系信息,然后进入Aggregation Layer 聚合多个匹配向量序列,组成一个固定长度的匹配向量,最后用于Prediction Layer 进行预测概率。
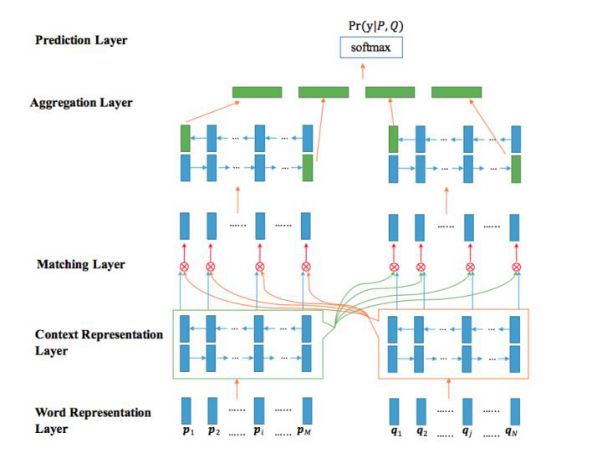
图2 BIMPM神经网络结构[27]
通过BIMPM模型可以捕捉到句子之间的交互特征,但是这样的匹配仅仅也只是在表层特征进行比较,并不涉及深层次的特征比较。为了进行深层次的特征比较,我们借鉴了图像中的MMD思想,Maximum Mean Discrepancy,即最大平均差异,通过深度神经网络的特征变换能力,对变换后的特征分布进行匹配。MMD的最大优点在于它不仅进行表层特征的匹配,还进行深层次特征的匹配,这样可以更精确地计算出特征之间的匹配程度,提升模型的效果。拿图像对比来举例,图像中所蕴含的信息不单单是由表层特征就可以来涵盖的,往往是通过表层、多个隐藏层以及它们之间不同的参数相加得到的结果。
BIMPM将每个句子中的每个词语表示成d维向量,然后经过Context Representation Layer,将上下文的信息融合到需要对比的P和Q两个句子中的time-step表示,最终比较句子P和句子Q的所有上下文向量,但它也只是对表层特征进行匹配,从而忽略很多额外的语义特征,但是BERT 预训练模型的流行,让深层特征匹配成为了现实。
如果我们将MMD的思想应用到句子匹配的任务上,并用BERT预训练深层模型来实现,就会得到一个重要的启发,MMD思想的主要效果来源于它将BERT预训练深层模型的不同层表示进行匹配,形象地来说,这是一种“向下匹配”的思维。而BIMPM由于在BERT之前出现,其语义表示只能通过词(字)向量和LSTM等网络进行,因此它捕捉特征表示的方法只能通过“向上匹配”。这是否意味着自从BERT出现以后,将这两种方式进行结合呢?
基于这个思路,我们在本文中提出了问题语义等价的FT-TM具体实现,它的思想是将特征“向下匹配”和“向上匹配”相结合。在具体的实现上,我们分别从BERT深层模型的最后几层中提取特征通过加法进行拼接,替代原始的字向量输入到BIMPM模型当中。这种做法是和MMD很相似的,只不过MMD中采用各种距离函数,而在这里我们采用的是多种匹配函数。除此之外,我们对BIMPM模型也做了以下修改:
首先,我们去掉了原始BIMPM模型中接在字向量层的Bi-LSTM模型,之所以这样做,其原因在于LSTM并没有设计机制保证梯度向深度模型的后向传导;
其次,我们用Transformer模型替代了BIMPM最上层的Bi-LSTM模型。这样做的原因主要是考虑到Bi-LSTM能够捕捉数据当中的序列特征。但是由于BIMPM采用多种匹配后,其序列性并不强,所以Transformer更适合该模型。
04
实 验
概述
本节内容会通过三个不同NLP任务的实验来检验我们的设想,首先,通过在BERT模型顶部添加Bi-LSTM来运行命名实体识别任务。在本实验中,我们希望测试通过对常用网络结构进行修改,提出的训练策略是否可以提高整体准确性。其次,我们进行文本分类实验,实验中训练了三个模型,并执行了模型集成。我们希望验证,如果添加的网络无法显著提高准确性,但可以通过模型集成来提高效果。最后,我们进行了文本语义相似性测试,实验结果表明,如果可以定制一个专门适合于预训练语言特征的网络,则可以期待更大的改进。
实验A:序列标注
在序列标记任务中,我们使用共享基准数据集CoNLL03数据集[6]探索实体识别子任务。文献[20],[21],[22]在此数据集上测试了它们的新网络结构。该实验以仅对BERT进行fine-tune(即方法FT-NTM)的结果为baseline,对比了在BERT基础上增加一个传统用于NER任务的Bi-LSTM网络(即方法FT-TM)的效果,实验结果如表2中所示。
表2 命名实体识别的结果
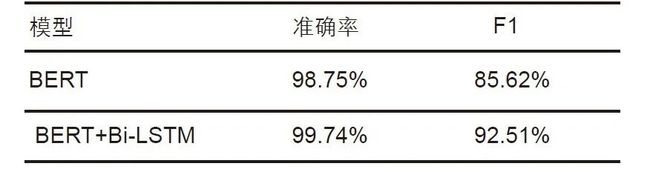
实验结果表明,结合BERT的fine-tune和上层神经网络的FT-TM算法在该任务上的F1值较baseline提升了近7个百分点。
实验B:文本分类
在文本分类任务中,我们使用了Yahoo Answer分类数据集. Yahoo Answers由10个类构成,但是由于数据集数量巨大,我们只选择其中两个。对于上层模型,我们选择DenseNet[23]和HighwayLSTM [24]。
DenseNet结构包含四个独立的块,每个块具有四个通过残差连接的CNN。我们使用BERT初始化词表示层中的词嵌入。我们将每个字符初始化为768维向量。在训练DenseNet的实验中,我们将使用[CLS]进行预测的DenseNet输出向量,隐藏大小设置为300。在所有实验中,我们还使用了dropout技巧以避免每个完全连接的层过度拟合,并将dropout率设置为0.5。
表3 文本分类的结果
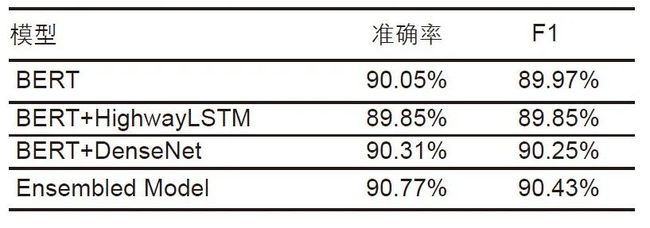
实验结果如表3中所示,可以看出,虽然模型集成后的效果并不十分明显,但也有一定的效果提升。
实验C:句子语义等价任务
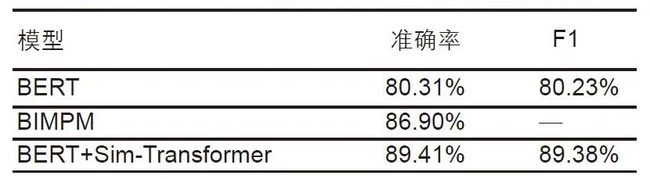
我们使用“Quora-Question-Pairs”标准数据集,这是一个包含40万个问题对的数据集,人工注释是否等效。由于数据集的质量很高,它是测试各种语义相似性模型效果的标准数据集,文献[25],[26],[27],[28]提出了在该数据集上进行效果测试的各种模型。我们提出的FT-TM算法在公开的Quora数据集达到了目前的State of the Art,这个数据集包括了超过400,000问题组,专门用来研究两个句子是否语义等价的二分问题。因为该数据集的标注质量非常高,它经常用来测试语义理解的模型效果,我们按照7:2:1的比例来分配训练集、验证集和测试集。
本次实验将仅对BERT进行fine-tune的方法FT-NTM为baseline,对比了在BERT之后接BIMPM网络的效果。同时以方法NFT-TM为baseline,对比了两种改进BIMPM之后模型结构的效果(移除BIMPM中的第一层Bi-LSTM模型和将BIMPM的matching层与transformer相结合的模型)。注意,在模型训练时有个重要的技巧,考虑到预训练模型本身的效果和其与顶层模型的融合问题,在训练模型时,需要分两步进行:先固定预训练模型的参数,仅训练其上层特定任务网络,第二步再将整个网络联合训练。实验结果如表4中所示,可以看出,由实验结果可得,Bert+Sim-Transformer结合fine-tune Bert的FT-TM算法效果相较仅对BERT进行fine-tune的方法FT-NTM,准确率提升了近5个百分点,达到了目前的State of the Art。
表4 句子语义相似任务在Quora数据集的结果
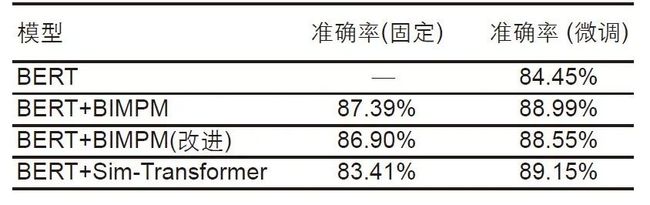
为了确保实验结论的有效性,除去Quora的数据集之外,我们还采用了SLNI数据集当中包含句子等价性的数据集,该数据集包括55万条训练集和10000条测试集。很多学者都用了这些数据来测试他们的模型包效果,对比这些模型,FT-TM算法的准确率上有将近两个点的提升,达到了目前的State of the Art,具体实验结果如下表所示:
表5 句子语义相似任务在SNLI数据集的结果
因此,从上面一系列的实验结果可以看出,我们提出的结合上层复杂模型和fine-tune的算法FT-TM是有效的,并且在NLP任务中优于fine-tune的算法FT-NTM,同时在BERT预训练模型上面集成的神经网络模型好坏也会影响到最终的任务效果。
参考文献
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1:8, 2019.
Matthew Peters, Sebastian Ruder, and Noah A Smith. To tune or not to tune? adapting pretrained representations to diverse tasks. arXiv preprint arXiv:1903.05987, 2019.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge. arXiv preprint arXiv:1808.07042, 2018.
Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050, 2003..
Alex Wang, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
Sébastien Jean, Orhan Firat, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. Montreal neural machine translation systems for wmt’15. In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 134–140, 2015.
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223, 2019.
Tomas Mikolov, Kai Chen, Gregory S Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. international conference on learning representations, 2013.
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher G Clark, Kenton Lee, and Luke S Zettlemoyer. Deep contextualized word representations. north american chapter of the association for computa- tional linguistics, 1:2227–2237, 2018.
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. meeting of the association for computational linguistics, 1:328–339, 2018.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
Kaz Sato, Cliff Young, and David Patterson. An in-depth look at google’s first tensor processing unit (tpu). Google Cloud Big Data and Machine Learning Blog, 12, 2017.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013
Adina Williams, Nikita Nangia, and Samuel R Bowman. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426, 2017.
WilliamBDolanandChrisBrockett.Automaticallyconstructingacorpusofsententialparaphrases.InProceedings of the Third International Workshop on Paraphrasing (IWP2005), 2015.
Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055,2017.
Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove:Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360, 2016.
Xuezhe Ma and Eduard Hovy. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354, 2016.
Hoa T Le, Christophe Cerisara, and Alexandre Denis. Do convolutional networks need to be deep for text classification? In Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
Yu Zhang, Guoguo Chen, Dong Yu, Kaisheng Yaco, Sanjeev Khudanpur,and James Glass. Highway long short-term memory rnns for distant speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5755–5759.IEEE, 2016.
Jonas Mueller and Aditya Thyagarajan. Siamese recurrent architectures for learning sentence similarity. In Thirtieth AAAI Conference on Artificial Intelligence, 2016.
Shuohang Wang and Jing Jiang. A compare-aggregate model for matching text sequences. arXiv preprint arXiv:1611.01747, 2016.
Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, Hui Jiang, and Diana Inkpen. Enhanced lstm for natural language inference. arXiv preprint arXiv:1609.06038, 2016.
Zhiguo Wang,Wael Hamza, and Radu Florian. Bilateral multi-perspective matching for natural language esentences. arXiv preprint arXiv:1702.03814, 2017.
—— / END / ——
职位热招中
①【北京】TalkingData
资深银行行业BD-华北/华东JD、资深非银行业BD-华东/华南JD、数据分析师JD丨点击“这里”了解详情
②【上海】数数科技
大数据运维支持工程师、大数据研发工程师、SDK研发工程师、数据分析师、销售经理(上海、北京、深圳)、高级数据产品经理、测试开发工程师丨点击“这里”了解详情
③【杭州+上海+北京+成都】蚂蚁金服大数据部
均为实习生招募—研发类:数据研发工程师、JAVA工程师、前端工程师丨算法类:机器学习算法工程师丨产品类:数据产品经理丨点击“这里”了解详情
④【杭州】阿里数据中台品牌团队
均为市场及品牌岗位:数据品牌管理、数据中台整合营销、数据中台内容运营、数据中台渠道策略运营丨点击“这里”了解详情
⑤【杭州】数字浙江
社招:JAVA开发工程师丨校招:数据开发工程师、JAVA开发工程师丨点击“这里”了解详情
提示:如贵公司近期有职位发布需求,可发送内容至数据猿寻求友情扩散[email protected]
2019数据猿年度榜单:
●2019大数据产业趋势人物榜TOP 10
●2019大数据产业创新服务企业榜TOP 15
●2019大数据产业创新服务产品榜TOP 40
数据猿
易观 “进化论”:智能用户运营助中小企业战“疫”

