第五周作业:卷积神经网络(Part3)
一、MobileNetV1网络
使用深度可分离卷积构建轻量级深层神经网络。
(1)MobileNet主要专注于优化延迟,但也会产生小型网络。
(2)深度可分离卷积:将标准卷积分解为深度卷积和1×1卷积(点态卷积)。深度卷积将单个滤波器应用于每个输入通道,逐点卷积应用1×1卷积将输出与深度卷积相结合。

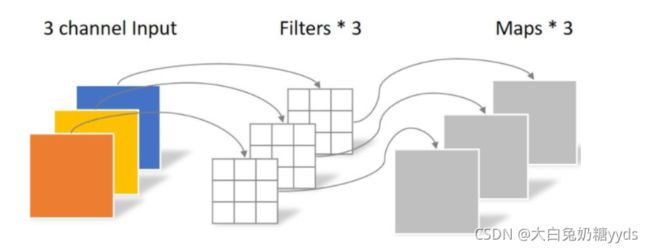
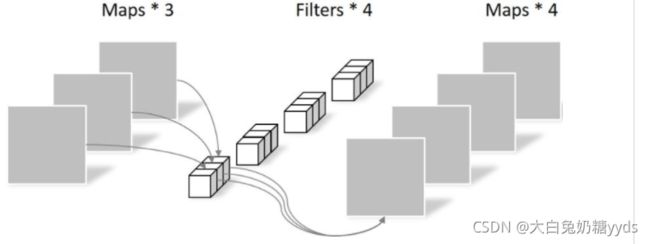
与标准卷积的区别:标准的卷积运算可以在一个步骤中将输入滤波并组合成一组新的输出。深度可分离卷积将其分为两层,一层用于滤波,另一层用于组合。标准卷积的花费:DK·DK·M·N·DF·DF(DK:卷积核大小,M输入通道数,N输出通道数,DF输入数据宽度)。MobileNet模型使用深度可分离卷积来打破输出通道数量和内核大小之间的相互作用,其花费为DK·DK·M·DF·DF+M·N·DF·DF。
(3)网络结构与简单实现:

# 自定义卷积块
class Block(nn.Module):
def __init__(self, in_planes, out_planes, stride=1):
super().__init__()
# 各层卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes,
bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# 1*1卷积
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, X):
out = F.relu(self.bn1(self.conv1(X)))
out = F.relu(self.bn2(self.conv2(out)))
return out
#网络模型
class MobileNetV1(nn.Module):
cfg = [(64, 1), (128, 2), (128, 1), (256, 2), (256, 1), (512, 2), (512, 1),
(1024, 2), (1024, 1)]
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out(4)降低网络成本的超参数:宽度倍增器(作用是在每一层均匀地薄化网络。对于给定的层和宽度乘数α,输入通道数M变为αM,输出通道数N变为αN)、分辨率乘数ρ(将其应用于输入图像,随后每个层的内部表示将通过相同的乘数进行缩减),两个超参数的影响后的成本DK·DK·αM·ρDF·ρDF+αM·αN·ρDF·ρDF
(5)计算量的减少:

二、MobileNetV2网络
(1)新的层模块:带线性瓶颈的反向残差。该模块将低维压缩表示作为输入,首先将其扩展到高维,并使用轻型深度卷积进行过滤。特征随后通过线性卷积投影回低维表示。
(2)改动:MobileNet V2 先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维;Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了。

class Block(nn.Module):
def __init__(self, in_planes, out_planes, expansion,stride=1):
super().__init__()
# 各层卷积
self.stride = stride
planes = expansion*in_planes
self.conv1 = nn.Conv2d(in_planes,planes,kernel_size=1,stride=1,padding=0,bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes,planes,kernel_size=3,stride=stride,padding=1,groups=planes,bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes,out_planes,kernel_size=1,stride=1,padding=0,bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
if stride == 1 and in_planes != out_planes:
self.shorcut = nn.Sequential(
nn.Conv2d(in_planes,out_planes,kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(out_planes)
)
if stride == 1 and in_planes == out_planes:
self.shorcut = nn.Sequential()
def forward(self, X):
out = F.relu(self.bn1(self.conv1(X)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.stride == 1:
return out+self.shorcut(X)
else:
return out
class MobileNetV1(nn.Module):
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320,1280,kernel_size=1,stride=1,padding=0,bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1] * (num_blocks - 1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out三、HybridSN 高光谱分类网络
学习论文:HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification
高光谱图像:在光谱的维度进行了细致的分割,不仅仅是传统的黑,白,或者R、G、B的区别,而是在光谱维度上也有N个通道,不仅可以获得图像上每个点的光谱数据,还可以获得任意一个谱段的影像信息。
数据集:IP(Indian Pines data set)具有145×145个空间维度的图像和224个波长范围为400至2500 nm的光谱带,其中覆盖吸水区域的24个光谱带已被丢弃。可用的地面真相被划分为16类植被。
(1)在高光谱图像分类的方法中了解到:仅使用二维卷积层会导致缺少通道信息,而仅使用三维卷积层则会导致模型过于复杂。主要原因是HSI是体积数据,并且具有光谱尺寸。仅二维CNN无法从光谱维度中提取具有良好辨别力的特征图。
(2)PCA:传统的主成分分析,将光谱带的数量从D减少到B,同时保持相同的空间维度(即宽度和高度)。我们只减少了光谱波段,这样就保留了空间信息。
(3)网络结构:三个三维卷积层、一个二维卷积层、一个全连接层。前三个卷积核尺寸为8×3×3×7×1,16×3×3×5×8,32×3×3×3×16,其中16×3×3×5×8表示所有8个三维输入特征图的16个3×3×5维三维核(即两个空间维和一个光谱维)。二维卷积核的维数为64×3×3×576(表示输入为576个通道的经过64个3*3卷积)。3-D卷积被应用三次,并且可以在输出体积中保留输入HSI数据的光谱信息。二维卷积在切分层之前应用一次,因为它可以在不损失光谱信息的情况下强烈区分不同光谱带内的空间信息。网络结构实现:
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Sequential(nn.Conv3d(1,8,(7,3,3)),
nn.BatchNorm3d(8),
nn.ReLU())
self.conv2 = nn.Sequential(nn.Conv3d(8,16,(5,3,3)),
nn.BatchNorm3d(16),
nn.ReLU())
self.conv3 = nn.Sequential(nn.Conv3d(16,32,(3,3,3)),
nn.BatchNorm3d(32),
nn.ReLU())
self.conv4 = nn.Sequential(nn.Conv2d(576,64,kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU())
self.net = nn.Sequential(nn.Flatten(),
nn.Linear(18496,256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256,128),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(128,16))
def forward(self,X):
X = self.conv1(X)
X = self.conv2(X)
X = self.conv3(X)
X = X.reshape((-1,576,19,19))
X = self.conv4(X)
X = self.net(X)
return X(4)思考:因为dropout每次丢弃部分神经元,所以结果会有不同,可以在测试的时候去掉该层。