屠榜语义分割和全景分割!FAIR提出MaskFormer:语义分割是像素分类问题吗?
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Bowen Cheng | 已授权转载(源:知乎)
https://zhuanlan.zhihu.com/p/389457610

论文“Per-Pixel Classification is Not All You Need for Semantic Segmentation”解读!
论文: https://arxiv.org/abs/2107.06278
代码(刚刚开源):
https://github.com/facebookresearch/MaskFormer
写这篇文章的主要目的是想介绍“Per-Pixel Classification is Not All You Need for Semantic Segmentation”背后的主要思想,而不是MaskFormer的具体实现。对实验细节感兴趣的小伙伴欢迎看我们的paper或者code。
TL;DR
图片语义分割(semantic segmentation)问题一直以来都被当做一个像素级分类(per-pixel classification)问题解决的。我们发现,把语义分割看成一个mask classification问题不仅更自然的把语义级分割(semantic-level segmentation)和实例级分割(instance-level segmentation)联系在了一起,并且在语义分割上取得了比像素级分类方法更好的方法。我们提出的MaskFormer模型在语义分割(ADE20K, 55.6 mIoU)和全景分割(COCO-panoptic, 52.7 PQ)上都取得了新的state-of-the-art结果。
1. 语义分割是像素分类问题吗?
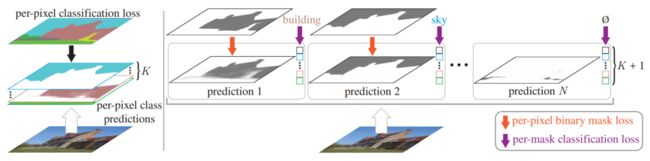
Figure 1: Per-pixel classification (left) v.s. mask classification (right)
自从Fully Convolution Networks (FCNs)问世以来,语义分割问题就被默认当做一个像素分类问题来解决了(Figure 1 左边图)。像素分类极大的简化了语义分割,把它从一个分割(segmentation,或者是pixel grouping)的问题变成了一个分类(classification,或者是recognition)的问题。不可否认,这种简化是相当聪明的,但是从另一方面来看,也限制了人们的想象空间。这里引用去年知乎上特别火的一个关于语义分割的提问,我们会发现大部分的回答都是停留在像素分类这个框架下讨论语义分割还有什么可以做的。
语义分割该如何走下去?
https://www.zhihu.com/question/390783647
但是如果我们把语义分割真的当做一个“分割”问题来看的话,会发现“像素分类”本身有很多limitations。其中最大的问题就是它永远只能输出固定个数的segmentation masks(这个固定的个数等于数据集定义的类别数),所以“像素分类”很难解决实例分割这样更难的问题。
反观实例分割,一直以来都是被以Mask R-CNN为代表的基于mask classification的方法来解决的(Figure 1 右边图)。Mask classification和per-pixel classification最大的不同在于:mask classification里面的每一个binary mask都只需要一个global的类别(而不是每个像素都需要类别)。我们认为mask classification是一种更general的分割方法,并且mask classification一度在FCN之前“霸榜”过Pascal VOC semantic segmentation challenge (O2P, R-CNN, SDS等基于mask proposal的方法)。但是因为更简单的FCN的出现,大家放弃了mask classification这条路。
所以在这篇paper里,我们想验证以下两个问题:
能否找到一个简洁通用的mask classification模型同时解决语义分割和实例分割问题?
这个mask classification模型在语义分割上的结果能否超越传统的像素分类模型?
我们给出的答案是肯定的:
mask classification模型可以同时解决语义分割和实例分割问题,并且我们发现这个模型甚至不用做任何改动:包括模型结构(model architecture),训练的loss,以及训练方法。
mask classification模型在语义分割上不仅比像素分类模型的结果更好,而且需要更少的参数和计算量。
并且我们提出了一个非常简单的MaskFormer模型来验证这两点。
如果你还在纠结语义分割该怎么走下去,欢迎试用我们的MaskFormer模型。所有代码和模型都已经开源:
https://github.com/facebookresearch/MaskFormer
2. MaskFormer模型简介
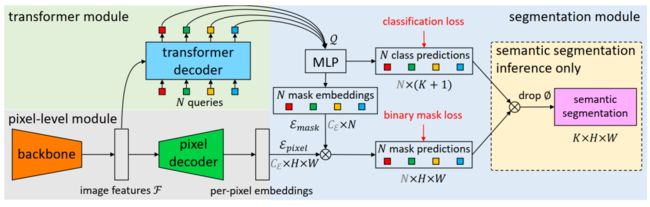
Figure 2: MaskFormer architecture
这里简单的介绍一下MaskFormer。首先声明:我们这篇paper的主要目的是对语义分割这条路该怎么走的重新思考,而不是为了追求“novelty”去提出一个fancy的模型。所以我们追求的是用最简单的模型来验证mask classification这条路的可行性。
受到DETR的启发,我们也用“object query”的概念去预测binary mask以及每个binary mask的类别。这里想强调的一点是:虽然语义分割有固定个数的类别(Figure 2中的K是类别数),我们发现query的个数(Figure 2中的N是query个数)不一定需要等于类别数。相反,在我们之后的实验中我们发现最优的query个数其实跟类别数没有关系。
因为query个数和类别数不一样,所以我们也借鉴了DETR中bipartite matching loss的设计思想来训练我们的模型。具体设计细节欢迎大家参考我们的paper和code。
3. 实验结果
我们发现semantic segmentation很多数据集上的variance都很大,所以我们所有的semantic segmentation结果都是同一个模型训练三次取中位数,并且我们还report了这三个结果的standard deviation。
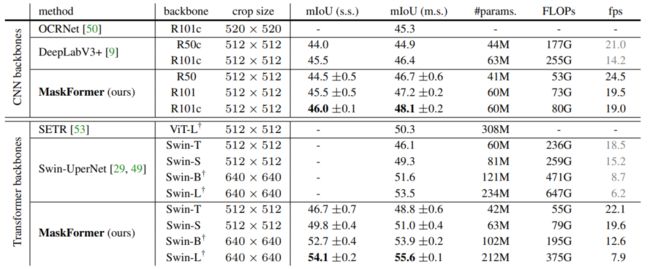
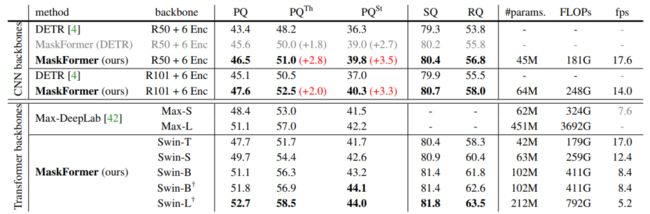
Table 2: Panoptic segmentation on COCO val
Table 1和2中列出了semantic segmentation (ADE20K)和panoptic segmentation (COCO)的主要结果。这里就不多展开讲了,MaskFormer不仅结果更好,而且速度更快参数更少。所以不要犹豫了,赶快试试MaskFormer吧!Table 1和2中MaskFormer的所有模型都已经开源。
4. 讨论
这里主要讨论两个很有意思的发现,文章中有更多的ablation study这里就不全部讲了。做实验的时候我们也思考过mIoU是不是最优指标,我们发现用PQ(这里把所有类别都当做了stuff类)来衡量semantic segmentation可能会给我们更多insight。
4.1 Mask classification什么时候比per-pixel classification好?
 Table 3: Semantic segmentation on 4 datasets
Table 3: Semantic segmentation on 4 datasets
为了验证mask classification是否比per-pixel classification好我们在5个semantic segmentation数据集上做了实验(这里只放了四个结果,还有Mapillary Vistas的结果可以在paper appendix里面找到)。这里ADE20K-Full的意思是我们用了ADE20K里面的所有annotation,而不是只用前150类。这里backbone用的是ResNet-50(Cityscpaes用了ResNet-101)。
Table 3中有一个很有意思的结果:当类别越多的时候mask classification模型的提升越大(这里PerPixelBaseline+指和MaskFormer相同的结构但是通过per-pixel classification loss来训练,细节见paper)。这就说明了每一个binary mask预测一个类别(而不是每个pixel一个类别)可以更好的学习区分更加fine-grained的区域。所以在实际应用中mask classification可能会更加有价值。
我们还发现,虽然Cityscapes上mIoU和baseline一样,但是MaskFormer的PQ还是要高不少。我们发现PQ的增长主要来自RQ (recognition quality),和baseline相比SQ (segmentation quality)反而更低。所以mask classification模型(或者是MaskFormer)面临主要问题是如何生产更高质量的binary mask(这可能跟我们仅仅用了FPN decoder有关)。这也说明了semantic segmentation还有提升的空间。
4.2 Query的个数和类别个数有关吗?
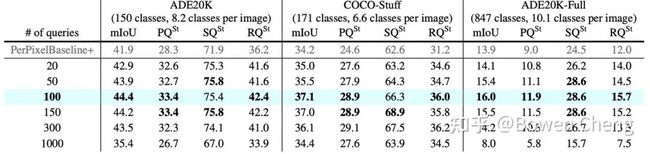 Table 4: Semantic segmentation with different number of queries
Table 4: Semantic segmentation with different number of queries
为了回答这个问题,我们在三个数据集(ADE20K, COCO-Stuff, ADE20K-Full)上训练了不同query个数的MaskFormer(Cityscapes上的结论也是类似的,因为篇幅问题没有放到paper里面)。我们发现用100个query在这三个数据集上都是最优的(虽然他们有不同的类别)。我们的猜想是query的个数可能跟平均每张图片里出现的类别数相关(毕竟ADE20K里的150类不可能在每张图片里都出现)。
5. 总结
我们觉得mask classification是一切分割问题的未来,因为:
我们验证了mask classification不仅取得了更好的结果,而且速度更快
Mask classification可以同时解决语义分割和实例分割
我们的paper只是一个proof of concept,我们相信还有更多机会和挑战
最后再宣传一波:代码已经开源!欢迎大家用我们的MaskFormer探索图像分割的新问题!
MaskFormer论文和代码下载
后台回复:MaskFormer,即可下载上述论文和代码
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看