【单目3D目标检测】MonoCon论文精读与代码解析
文章目录
- Preface
- Abstract
- Contributions
- Pipeline
- Regression Heads
- The Auxiliary Context Regression Heads
-
- Quantization Residual
- Bug
-
- Install
Preface
[AAAI2022] Liu X, Xue N, Wu T. Learning auxiliary monocular contexts helps monocular 3D object detection[C]. In Proceedings of the AAAI Conference on Artificial Intelligence. 2022: 1810-1818.
Paper
Code
MonoCon (AAAI 2022):使用「辅助学习」的单目3D目标检测框架
Abstract
本文提出了一种无需借助任何额外信息,而是学习单目Contexts来辅助训练过程的方法,称为MonoCon。其关键思想是,目标带有注释的 3D 边界框,可以产生大量可用的良好投影的 2D 监督信号(例如投影的角点关键点及其相关的偏移向量相对于 2D 边界框的中心),这应该在训练中用作辅助任务。MonoCon由三个组件组成:基于深度神经网络 (DNN) 的特征主干、许多回归头分支,用于学习 3D 边界框预测中使用的基本参数,以及用于学习辅助上下文的许多回归头分支。训练后,丢弃辅助上下文回归分支以获得更好的推理效率
从整体上来看,MonoCon是在MonoDLE的基础上,加入了投影的2D辅助学习模块以及对所有的Head加入了AN(Attentive Normalization)模块,从实验结果来看,这些trick的效果是非常work的,如下图所示

Contributions
- 在训练时加入辅助学习模块,在推理时去掉
- MonoDLE中有一句话“In this way, the 2D detection serves as an auxiliary task that helps to learn better 3D aware features.”不知道是不是MonoCon的灵感出发点??
- 把Regression Heads中所有的BN替换为AN,同时将Regression Heads中的第一个Cond模块的out-channel由MonoDLE的256变为64( d = 64 d=64 d=64)
F ⟹ d × 3 × 3 × D C o n v + A N + R e L U F d × h × w ⟹ C o n v c × 1 × 1 × d H c × h × w b F \stackrel{C o n v+A N+R e L U}{\underset{d \times 3 \times 3 \times D}{\Longrightarrow}} \mathbb{F}_{d \times h \times w} \underset{c \times 1 \times 1 \times d}{\stackrel{C o n v}{\Longrightarrow}} \mathcal{H}_{c \times h \times w}^b Fd×3×3×D⟹Conv+AN+ReLUFd×h×wc×1×1×d⟹ConvHc×h×wb - 对应的代码如下所示:
AttnBatchNorm2d(64, eps=0.001, momentum=0.03, affine=False, track_running_stats=True
(attn_weights): AttnWeights(
(attention): Sequential(
(0): Conv2d(64, 10, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): HSigmoidv2()
)
)
)
Pipeline

Backbone:DLA34(CenterNet)
Neck:DLAUP
Head:两部分
- 常规的Regression Head
- 本文创新点:辅助学习Regression Head(四部分)
Loss:五部分,配置文件中的对应代码如下:
loss_center_heatmap=dict(type='CenterNetGaussianFocalLoss', loss_weight=1.0),
loss_wh=dict(type='L1Loss', loss_weight=0.1),
loss_offset=dict(type='L1Loss', loss_weight=1.0),
loss_center2kpt_offset=dict(type='L1Loss', loss_weight=1.0),
loss_kpt_heatmap=dict(type='CenterNetGaussianFocalLoss', loss_weight=1.0),
loss_kpt_heatmap_offset=dict(type='L1Loss', loss_weight=1.0),
loss_dim=dict(type='DimAwareL1Loss', loss_weight=1.0),
loss_depth=dict(type='LaplacianAleatoricUncertaintyLoss', loss_weight=1.0),
loss_alpha_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
loss_alpha_reg=dict(type='L1Loss', loss_weight=1.0),
- Heatmap:Gaussian kernel weighted focal loss
- Depth estimation:Laplacian aleatoric uncertainty loss function(MonoPair&MonoDLE&MonoFlex&GUPNet),公式如下所示:
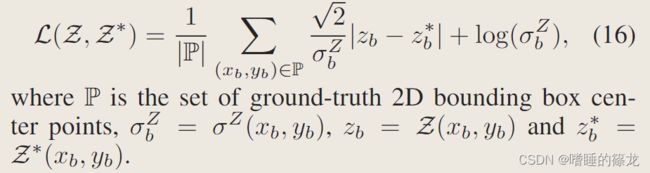
- 对应代码如下所示
mmdetection3d-0.14.0\mmdet3d\models\losses\uncertainty_loss.py:
class LaplacianAleatoricUncertaintyLoss(nn.Module):
"""
Args: reduction (str): Method to reduce losses. The valid reduction method are none, sum or mean. loss_weight (float, optional): Weight of loss. Defaults to 1.0. """ def __init__(self, loss_weight=1.0):
super(LaplacianAleatoricUncertaintyLoss, self).__init__()
self.loss_weight = loss_weight
def forward(self,
input,
target,
log_variance):
log_variance = log_variance.flatten()
input = input.flatten()
target = target.flatten()
loss = 1.4142 * torch.exp(-log_variance) * torch.abs(input - target) + log_variance
return loss.mean() * self.loss_weight
- 3D Size:Dimension-Aware L1 Loss(MonoDLE)
- Observation angles[bin index]: Standard Cross-Entropy Loss
- Offsets&Observation angles[residual]&2D Size&Quantization Residual:Standard L1 Loss
- 总损失是所有损失项的和,每个损失项都有一个权衡权重参数
loss_weight。为了简单起见,除了2D尺寸L1损失使用0.1外,我们对所有损失项都使用1.0
Regression Heads
- heatmap:借鉴自CenterNet,预测C类目标(KITTI中为3类:Car,Pedestrian,Cyclist)的2D框中心点坐标 ( x b , y b ) (x_b,y_b) (xb,yb),[c, h, w]
- offset:2D框中心坐标 ( x b , y b ) (x_b,y_b) (xb,yb)到3D框中心坐标 ( x c , y c ) (x_c,y_c) (xc,yc)的偏移 ( Δ x b c , Δ y b c ) \left(\Delta x_b^c, \Delta y_b^c\right) (Δxbc,Δybc)
- depth:预测深度值以及其不确定性,其中深度值采用逆Sigmoid进行处理:
Z 1 × h × w = 1 Sigmoid ( g ( F ; Θ Z ) [ 0 ] ) + ϵ − 1 \mathcal{Z}_{1 \times h \times w}=\frac{1}{\operatorname{Sigmoid}\left(g\left(F ; \Theta^Z\right)[0]\right)+\epsilon}-1 Z1×h×w=Sigmoid(g(F;ΘZ)[0])+ϵ1−1 - dimensions:3D框的尺寸
- observation angle:观测角,采用multi-bin策略,分成24个区间,前12个用于分类(粗略预测),后12个用于回归(精细预测)将直接回归问题转化为先分类,再回归的问题
The Auxiliary Context Regression Heads
辅助学习学了四件事:
- The heatmaps of the projected keypoints:8个投影角点和3D框的投影中心
- The offset vectors for the 8 projected corner points:8个投影角点到2D框中心的offsets
- The 2D bounding box size:2D框的尺寸
- The quantization residual of a keypoint location:由于backbone降采样的存在,原始图像目标中心点的位置和backbone输出feature map中的位置之间,存在量化误差。假设目标在原始图像中的位置为 ( x b ∗ , y b ∗ ) (x_b^{*}, y_b^{*}) (xb∗,yb∗),在feature map中的位置为 ( x b = ⌊ x b ∗ s ⌋ , y b = ⌊ y b ∗ s ⌋ ) \left(x_b=\left\lfloor\frac{x_b^*}{s}\right\rfloor, y_b=\left\lfloor\frac{y_b^*}{s}\right\rfloor\right) (xb=⌊sxb∗⌋,yb=⌊syb∗⌋),那么就可以定义量化残差为: δ x b = x b ∗ − x b , δ y b = y b ∗ − y b \delta x_b=x_b^*-x_b, \quad \delta y_b=y_b^*-y_b δxb=xb∗−xb,δyb=yb∗−yb,MonoCon分别对2D中心 ( x b , y b ) (x_b,y_b) (xb,yb)和9个投影点 ( x k , y k ) (x_k,y_k) (xk,yk)进行量化误差建模
Quantization Residual
这部分单独拿出来着重讨论以下两个问题:
1、论文中给出的量化残差计算公式与源码中的对应实现不一致
- 论文中的计算公式如上所示,对于9个关键点的量化残差,target取值是 x b ∗ x_b^{*} xb∗与 ⌊ x b ∗ s ⌋ \left\lfloor\frac{x_b^*}{s}\right\rfloor ⌊sxb∗⌋的差值
- 而在代码中,target取值是 x b ∗ s \frac{x_b^*}{s} sxb∗与 ⌊ x b ∗ s ⌋ \left\lfloor\frac{x_b^*}{s}\right\rfloor ⌊sxb∗⌋的差值,也就是在feature map中关键点自身的offsets
- 具体代码在这里
- 在我看来,代码中的实现似乎更加合理,不知道是作者后来又改了源码还是本来就这么写的
2、对9个投影点 ( x k , y k ) (x_k,y_k) (xk,yk)进行量化误差建模时,MonoCon采用了keypoint-agnostic方式,即关键点无关建模
- 在前向推理阶段,网络对于9个关键点的量化残差的预测输出shape为[bs, 2, f_h ,f_w],也就是只预测了一对offsets,不是9对全部预测
- 在计算Loss阶段,targets中包含全部9个关键点的offsets(shape为[bs, max_objs, 18]),为了顺利计算Loss,这里对预测的量化残差进行了以下处理:
# kpt heatmap offset
# [8, 2, 96, 312] --> [8, 270, 2]
kpt_heatmap_offset_pred = transpose_and_gather_feat(kpt_heatmap_offset_pred, indices_kpt)
# [8, 270, 2] --> [8, 30, 18]
kpt_heatmap_offset_pred = kpt_heatmap_offset_pred.reshape(batch_size, self.max_objs, self.num_kpt * 2)
- 将预测的量化残差处理成和targets中一样的shape,这样就可以直接计算Loss
- 对应于网络框架中的
Projected keypoints Quantization Residual(2×h×w)部分
Bug
Install
- 官方给的安装步骤中
timm版本未指定:
# 指定timm版本,不然会更新torch==1.10.0
pip install timm==0.4.5
- 不知道什么原因出现报错:
numba.cuda.cudadrv.error.NvvmError: Failed to compile- 解决办法:issue
Note: To solve this issue, install numba==0.53.0 using conda, dont use pip
Example: conda install numba==0.53.0