An Image is worth 16x16 Words: Transformer for image recognition at scale(论文阅读笔记)
An Image is worth 16x16 Words: Transformer for image recognition at scale
An Image is worth 16x16 words:
1、Abstract
Transformer架构在NLP任务重应用广泛,但在计算机视觉领域受限较多。在视觉领域中,注意力一般都是与卷积网络联合使用,或者是替代卷积神经网络中的某一元件,但整体架构是不变的。本文说明了CNN不是必要的,单独完全使用transformer也可以在图像分类任务中取得很好的成绩。由于是先在大规模的数据集上做pre-train,随后迁移到小型数据集中,其效果可以和最好的卷积神经网络相媲美。
2、Introduction
自注意力架构,尤其是Transformer基本是已经是NLP领域中的必选模型。主流的方式是先去大规模数据集中做pre-train,随后fine-tune在小规模数据集中。Transformer训练的高效性、可拓展性,现在已经可以训练100B参数的模型了。随着模型和数据集的增加,Transoformer的性能却没有饱和的现象。
在计算机视觉中,卷积架构还是占据着主导模型,但是由于Transoformer在NLP领域中如此成功,所以有很多的工作是将CNN和Self-attention结合起来了(Non-local neural networks:使用像素点直接当注意力的输入计算量太大,那么就将中间的特征图当作输入,eg14x14,先卷积再transformer),有些是完全的替换的卷积操作( (Ramachandran et al., 2019;孤立自注意力:利用小窗口代替用一整张图像,类似卷积。 Wang et al., 2020a:轴注意力,图片大小是HxW是一个2d的矩阵,将其拆分成俩个1d的,分别在高宽上做注意力机制))。后者(完全的替换的卷积操作)只是在理论上是高效的,但其并没有在现在的硬件上去加速,导致其很难训练处一个很大的模型。所以,在大规模的图像识别、分类中,传统的ResNet网络仍然效果是最好的。
我们尽量使用NLP中完整的Transformer架构,尽可能少的针对视觉任务的针对性修改。首先将一张图片划分成一个个patchs,然后将这些patchs通过fc laye得到linear embeddings,输入Transformer当中,其中一个patch相当于NLP中的一句中的一个word。我们使用有有监督的方法训练这个模型在图像分类任务中。

比如在ImageNet数据集上训练,没有加强的约束,Vit相比参差网络的模型是要低几个点的,Transformer相比于卷积网络缺少了归纳偏置(inductive biases:一种先验知识, 对于卷积神经网络来说,一般有俩个inductive biases,一个是locality,假设图片上相邻区域有相邻的特征,另一个是平移等变形(translation quivariance), f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x)),就是无论先平移再卷积还是先卷积再平移,其结果都是一样的。因为卷积核是一样的,无论桌子在哪里,只要输入桌子,卷积计算之后的结果都是一样的。)。由于CNN有这些先验信息,所以所需的数据量比Transformer要少很多。
所以使用了大数据集ImageNet 21k和JFT300M数据集训练,训练结果显然非常好。Vit在有足够的数据做与训练之后,在下游任务重活的很好的迁移学习效果。
3、Conclusion
直接拿NLP领域中标准的Transformer来做图像识别。与先前使用自注意力工作不同的是,我们除了在抽取图像块、以及位置编码的时候使用了一些图像特有的归纳偏置,除此之外,在没有使用归纳偏置。
我们可以直接将一张图片理解为一个序列的图像块,而每个图像块相当于一个单词,这样就可以直接输入标准的Transformer的encoder当中。这个简单、拓展性好的方法在大规模的数据集上pre-train之后其效果非常好,甚至超过了之前最好的方法。
Vit可以拓展到其他视觉任务类型当中,分割、检测。也可以探索自监督的pre-train方案。
4、Related work
自Transformer问世以来,在NLP领域中一直都是一个(the state of the art)先进的模型。其一般都是在大规模数据集上pre-train,然后在小规模数据集上fine-tune。有俩个比较经典的模型,BERT:denosing self-supervised, 就是一个完整的句子,认为划掉某些单词,让模型预测它。GPT:language modeling,就是已经有一个句子,预测下一个单词。这种人为制定的方式称为自监督。
5、Model
我们尽可能的使用原始的Transformer模型,因为这样就可以将NLP领域当中比较好的模型、实现直接引用。
5.1 vision Transformer
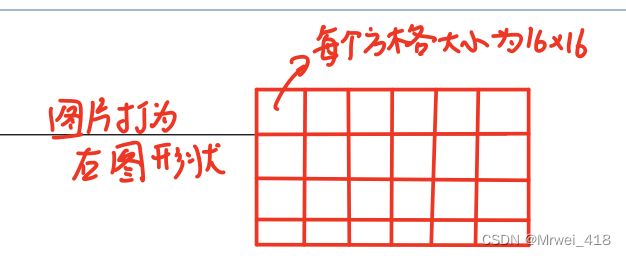
Transformer接受的是1D的token序列,对于2D的图像,我们需要将其变为一个个patch,patch的个数N=HW/P2,P为Patch的大小(默认16x16)。Transformer中vector的维度一直都保持在D(D=768),所以我们flatten the patches and map to D dimensions with a trainable linear projection。输出称为patch embedding。
为了最后的分类,借鉴了BERT中的 [class]token(cls),一个特殊的token。它是可以学习的。 它经过Transformer encoder之后,作为了图像的整体特征,通过MLP从而得到分类的结果。
位置信息使用的是与Bert相同的1D position embedding,当然由于图片具有空间信息,尝试使用了2D-aware position embedding,没有发现明显的效果提升。
Vision Transformer主要用的是multiheaded self-attention和MLP blocks, LN,以及residudal connections。整体流程用公式表示为:
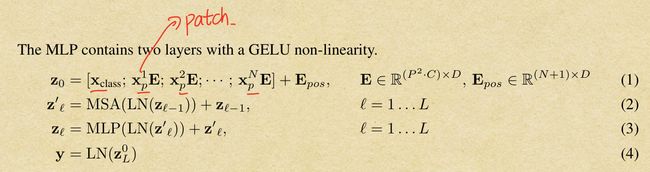
Inductive bias:Vit模型没有怎么使用归纳偏置,不像CNN中,几乎每一层都用到了归纳偏置(locality、 translation equivariance),在Vit中只有在MLP中用到了这俩个归纳偏置,其他地方基本没有用到,也就是说Vit对于图像的各种信息几乎都是从头开始学的,(no information about the 2D position),这也解释了为什么Vit模型需要非常大的数据集来训练的原因。
Hybrid Architecture: 首先将图片正常输入给CNN,CNN输出特征图维度正好是14x14(我认为这里的channel=D,eg:768 ),也就是196,正好可以输入Transformer。然后就和上面一样。
5.2 Fine-tuning and higher resolution
Vit在大数据集上pre-train之后,想要处理higher resolution的图片,需要进行一些微调。我们移除pre-train的预测头,增加了用zero-initialized DxK的FC,K是迁移数据集的类别个数。保持patch size大小不变,那么就会增加序列的长度,虽然Transformer理论上是可以训练任意长度的序列的,但是长度增加可能会导致之前训练好的位置编码参数不能使用,所以我们对位置编码使用了2D interpolation,但这也增加了Vit模型使用了一些归纳偏置。