机器学习技法笔记
文章目录
- 1 -- Linear Support Vector Machine
-
-
-
- Large-Margin Separating Hyperplane
- Support Vector Machine
-
-
- 2 -- Dual Support Vector Machine
-
-
-
- Motivation of Dual SVM
- Messages behind Dual SVM
- 总结:
-
-
- 3 -- Kernel Support Vector Machine
-
-
-
- Polynomial Kernel
- Gaussian Kernel
- 总结:
- Comparison of Kernels
-
-
- 4 -- Soft-Margin Support Vector Machine
-
-
-
- Motivation and Primal Problem
- Dual Problem
- Messages behind Soft-Margin SVM
- Model Selection
-
-
- 5 -- Kernel Logistic Regression
-
-
-
- Soft-Margin SVM as Regularized Model
- SVM versus Logistic Regression
- SVM for Soft Binary Classification
- Kernel Logistic Regression
-
-
- 6 -- Support Vector Regression
-
-
-
- Kernel Ridge Regression
- Support Vector Regression Primal
- Support Vector Regression Dual
- Summary of Kernel Models
-
-
- 7 -- Blending and Bagging
-
-
-
- Motivation of Aggregation
- Uniform Blending
- Linear and Any Blending
- Bagging(Bootstrap Aggregation)
-
-
- 8 -- Adaptive Boosting
-
-
-
- Motivation of Boosting
- Diversity by Re-weighting
- Adaptive Boosting Algorithm
- Adaptive Boosting in Action
-
-
- 9 -- Decision Tree
-
-
-
- Decision Tree Hypothesis
- Decision Tree Algorithm
- Decision Tree Heuristics in C&RT
- Decision Tree in Action
-
-
- 10 -- Random Forest
-
-
-
- Random Forest Algorithm
- Out-Of-Bag Estimate
- Feature Selection
- Random Forest in Action
-
-
- 11 -- Gradient Boosted Decision Tree
-
-
-
- Adaptive Boosted Decision Tree
- Optimization View of AdaBoost
- Gradient Boosting
-
-
- 12 -- Neural Network
-
-
-
- 略
-
-
- 13 -- Deep Learning
-
-
-
- linear autoencoder & Principal Component Analysis
-
-
- 14 -- Radial Basis Function Network
-
-
-
- RBF Network Hypothesis
- RBF Network Learning
- k-Means Algorithm
- k-means and RBF Network in Action
-
-
- 15 -- Matrix Factorization
-
-
-
- LinearNetwork Hypothesis
-
-
- 参考文献
1 – Linear Support Vector Machine
Large-Margin Separating Hyperplane
下图三条直线都是由PLA/pocket算法得到,都满足分类要求,但第三条直线对数据误差容忍度明显更高,边界够宽,所以第三条直线最robust

所以要得到一条最 robust 的直线,要满足两个条件:

优化目标就变成了:
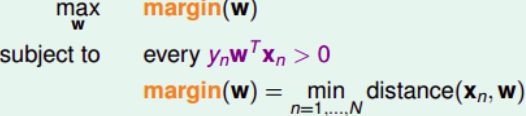
Standard Large-Margin Problem
w 0 w_0 w0 用 b b b 表示,点到分类平面的距离可表示为:

对目标形式做转换:
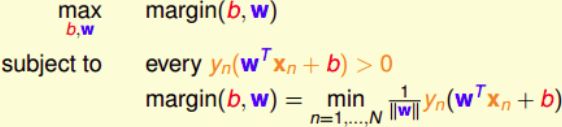
对 w w w 和 b b b 同时进行缩放,得到的还是同一分类面,那么可以令距离分类面最近的点满足
min n = 1 , ⋯ , N y n ( w T x n + b ) = 1 ⟹ m a r g i n ( b , w ) = 1 ∣ ∣ w ∣ ∣ \begin{aligned} &\min_{n=1,\cdots,N} y_n(w^Tx_n+b)=1\\ &\Longrightarrow margin(b,w)=\frac{1}{||w||} \end{aligned} n=1,⋯,Nminyn(wTxn+b)=1⟹margin(b,w)=∣∣w∣∣1
于是目标就简化成:
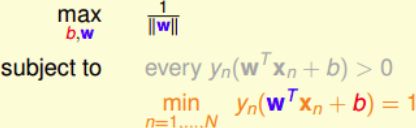
将最大化问题转化为最小化问题:

Support Vector Machine
分类面仅仅由分类面的两边距离它最近的几个点决定的,其它点对分类面没有影响。决定分类面的几个点称之为支持向量(Support Vector),利用Support Vector得到最佳分类面的方法,称之为支持向量机(Support Vector Machine)
SVM求解的条件和目标:

SVM求解是典型的二次规划问题 Quadratic Programming(QP)

线性SVM算法可总结为三步:
- 计算对应的二次规划参数 Q , p , A , c Q,p,A,c Q,p,A,c
- 根据二次规划库函数,计算 b , w b,w b,w
- 将 b b b 和 w w w 代入 g S V M g_{SVM} gSVM,得到最佳分类面
Linear Hard-Margin SVM Algorithm

如果是非线性的,可先进行特征变换,从非线性的 x x x 域映射到线性的 z z z 域空间,再用 Linear Hard-Margin SVM Algorithm求解
Reasons behind Large-Margin Hyperplane
SVM和正则化

Large-Margin会限制Dichotomies的个数,相当于把分类面变得更厚,能shatter的点就可能更少,VC Dimension也减少了。VC Dimension减少降低了模型复杂度,提高了泛化能力
2 – Dual Support Vector Machine
Motivation of Dual SVM
如果模型越复杂,求解QP问题在 z 域中的维度 d ^ + 1 \hat{d}+1 d^+1 越大,当 d ^ + 1 \hat{d}+1 d^+1 无限大的时候,问题将会变得难以求解。于是需要一种方法就是使SVM的求解过程不依赖 d ^ \hat{d} d^:

把问题转化为对偶问题(’Equivalent’ SVM),变量个数变成N个,有 N+1 个限制条件。对偶SVM的好处就是问题只跟 N 有关,与 d ^ \hat{d} d^ 无关
\qquad\qquad\qquad\qquad\qquad  \qquad
\qquad 
如何将条件问题转换为非条件问题?
令拉格朗日因子为 a n a_{n} an(区别于regularization),构造一个拉格朗日函数
L ( b , w , a ) = 1 2 w T w + ∑ n = 1 N a n ( 1 − y n ( w T z n + b ) ) L_{(b,w,a)}=\frac{1}{2}w^{T}w+\sum_{n=1}^{N}a_{n}(1-y_{n}(w^{T}z_{n}+b)) L(b,w,a)=21wTw+n=1∑Nan(1−yn(wTzn+b))

利用拉格朗日函数,把SVM构造成一个非条件问题:

- 如果没有达到最优解,即有不满足 ( 1 − y n ( w T z n + b ) ) ≤ 0 (1-y_{n}(w^{T}z_{n}+b))\leq0 (1−yn(wTzn+b))≤0的情况,因为 a n > 0 a_{n}>0 an>0,那么必然有
∑ n a n ( 1 − y n ( w T z n + b ) ) ≥ 0 \sum_na_n(1-y_n(w^Tz_n+b))\geq0 ∑nan(1−yn(wTzn+b))≥0,其最大值是无解的。 - 如果所有点满足 ( 1 − y n ( w T z n + b ) ) ≤ 0 (1-y_{n}(w^{T}z_{n}+b))\leq0 (1−yn(wTzn+b))≤0的情况,那么必然有 ∑ n a n ( 1 − y n ( w T z n + b ) ) ≤ 0 \sum_na_n(1-y_n(w^Tz_n+b))\leq0 ∑nan(1−yn(wTzn+b))≤0,有最大值。因此,这种转化为非条件的SVM构造函数的形式是可行。
Lagrange Dual SVM
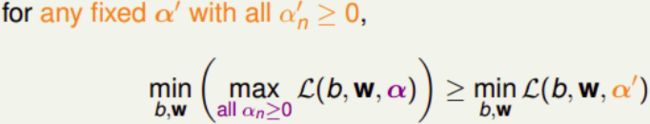
对上述不等式右边取最大值,不等式同样成立:

上述不等式关系称为 Lagrange dual problem,等式右边是SVM问题的下界
已知 ≥ \geq ≥是一种弱对偶关系,在二次规划QP问题中,如果:
- 函数是凸的(convex primal)
- 函数有解(feasible primal)
- 条件是线性的(linear constraints)
那么,上述不等式关系就变成强对偶关系 ≥ \geq ≥变成 = ,即一定存在满足条件的解 ( b , w , a ) (b,w,a) (b,w,a),使等式左边和右边都成立,SVM的解就转化为右边的无条件形式

括号里面的是对拉格朗日函数 L ( b , w , α ) L(b,w,α) L(b,w,α)计算最小值,而最小值位置满足梯度为零
对参数 b 求偏导: ∂ L ( b , w , α ) ∂ b = 0 = − ∑ n = 1 N α n y n \frac{\partial L(b,w,\alpha)}{\partial b}=0=-\sum_{n=1}^N\alpha_ny_n ∂b∂L(b,w,α)=0=−n=1∑Nαnyn
把得到的条件 ∑ n = 1 N α n y n = 0 \sum_{n=1}^N\alpha_ny_n=0 ∑n=1Nαnyn=0 带入max条件,消去了参数b:
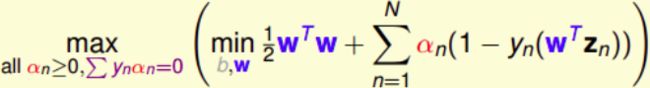
参数 w w w求偏导: ∂ L ( b , w , α ) ∂ w = 0 = w − ∑ n = 1 N a n y n z n \frac{\partial L(b,w,\alpha) }{\partial w}=0=w-\sum_{n=1}^{N}a_ny_nz_n ∂w∂L(b,w,α)=0=w−n=1∑Nanynzn
把 w = ∑ n = 1 N α n y n z n w=\sum_{n=1}^{N}\alpha_ny_nz_n w=∑n=1Nαnynzn这个条件代入并进行化简:
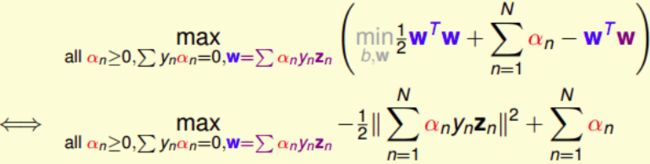
得到三个条件:
- α n ≥ 0 \alpha_n\geq0 αn≥0
- ∑ n = 1 N α n y n = 0 \sum_{n=1}^N\alpha_ny_n=0 ∑n=1Nαnyn=0
- w = ∑ n = 1 N α n y n z n w=\sum_{n=1}^N\alpha_ny_nz_n w=∑n=1Nαnynzn
于是SVM最佳化形式转化为只与 α n \alpha_n αn 有关:


Solving Dual SVM
前面已经得到了dual SVM的简化版,将 max 问题转化为 min 问题:

这显然是一个 convex 的QP问题,且有 N 个变量 α n \alpha_n αn,限制条件有N+1个:

注意: q n , m = y n y m z n T z m q_{n,m}=y_ny_mz^T_nz_m qn,m=ynymznTzm,大部分值是非零的,称为dense。当 N 很大的时候,例如N=30000,那么对应的 Q D Q_D QD的计算量将会很大,存储空间也很大,一般需要使用一些特殊的方法。

得到 α n \alpha_n αn后,再根据 KKT 条件计算出 w w w 和 b b b
计算 b b b 值, α n > 0 \alpha_n>0 αn>0时,有 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1成立。 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1正好表示的是该点在SVM分类线上,即fat boundary。满足 α n > 0 \alpha_n>0 αn>0的点一定落在fat boundary上,这些点就是Support Vector。
Messages behind Dual SVM
分类线上的点不一定都是支持向量,但是满足 α n > 0 \alpha_n>0 αn>0 的点,一定是支持向量


SVM 和 PLA的 w w w 公式:
\qquad\qquad\qquad\qquad  \qquad
\qquad 
二者在形式上是相似的。 w S V M w_{SVM} wSVM由fattest hyperplane边界上所有的SV决定, w P L A w_{PLA} wPLA由所有当前分类错误的点决定 . w S V M w_{SVM} wSVM 和 w P L A w_{PLA} wPLA 都是原始数据点 y n z n y_nz_n ynzn 的线性组合形式.


总结:
- Primal Hard-Margin SVM 有 d ^ + 1 \hat{d}+1 d^+1个参数,有N个限制条件。当 d ^ + 1 \hat{d}+1 d^+1 很大时,求解困难.
- 而 Dual Hard_Margin SVM 有 N N N 个参数, N + 1 N+1 N+1 个限制条件。当数据量 N N N 很大时,也同样会增大计算难度。两种形式都能得到 w w w 和 b b b,求得 fattest hyperplane。通常情况下,如果 N N N 不是很大,一般使用 Dual SVM。
Dual SVM是否真的消除了对 d ^ \hat{d} d^的依赖呢?
- 其实并没有,因为在计算 q n , m = y n y m z n T z m q_{n,m}=y_ny_mz^T_nz_m qn,m=ynymznTzm 的过程中,由 z 向量引入了 d ^ \hat{d} d^,实际上复杂度已经隐藏在计算过程中!
3 – Kernel Support Vector Machine
dual SVM中: z n T z m = Φ ( x n ) Φ ( x m ) z_n^Tz_m =\Phi(x_n)\Phi(x_m) znTzm=Φ(xn)Φ(xm), z z z 是经过
- ’特征转换为 Φ ( x n ) \Phi(x_n) Φ(xn)和 Φ ( x m ) \Phi(x_m) Φ(xm)
- 然后计算 Φ ( x n ) \Phi(x_n) Φ(xn)和 Φ ( x m ) \Phi(x_m) Φ(xm)的内积
先转换再计算内积的方式,必然会引入 d ^ \hat d d^ 参数, d ^ \hat d d^ 很大时影响计算速度
如果把这两个步骤联合起来,是否可以有效地减小计算量?
二阶多项式转换例子: Φ 2 ( x ) = ( 1 , x 1 , x 2 , … , x d , x 1 2 , x 1 x 2 , … , x 1 x d , x 2 x 1 , x 2 2 , … , x 2 x d , … , x d 2 ) \Phi_{2}(\mathbf{x})=\left(1, x_{1}, x_{2}, \ldots, x_{d}, x_{1}^{2}, x_{1} x_{2}, \ldots, x_{1} x_{d}, x_{2} x_{1}, x_{2}^{2}, \ldots, x_{2} x_{d}, \ldots, x_{d}^{2}\right) Φ2(x)=(1,x1,x2,…,xd,x12,x1x2,…,x1xd,x2x1,x22,…,x2xd,…,xd2)
把 x 0 = 1 x_0 = 1 x0=1、 x 1 x 2 x_1x_2 x1x2和 x 2 x 1 x_2x_1 x2x1包含进来,’转换之后再做内积并进行推导:
Φ 2 ( x ) T Φ 2 ( x ′ ) = 1 + ∑ i = 1 d x i x i ′ + ∑ i = 1 d ∑ j = 1 d x i x j x i ′ x j ′ = 1 + ∑ i = 1 d x i x i ′ + ∑ i = 1 d x i x i ′ ∑ j = 1 d x j x j ′ = 1 + x T x ′ + ( x T x ′ ) ( x T x ′ ) \begin{aligned} \Phi_{2}(x)^{T} \Phi_{2}\left(x^{\prime}\right) &=1+\sum_{i=1}^{d} x_{i} x_{i}^{\prime}+\sum_{i=1}^{d} \sum_{j=1}^{d} x_{i} x_{j} x_{i}^{\prime} x_{j}^{\prime} \\ &=1+\sum_{i=1}^{d} x_{i} x_{i}^{\prime}+\sum_{i=1}^{d} x_{i} x_{i}^{\prime} \sum_{j=1}^{d} x_{j} x_{j}^{\prime} \\ &=1+x^{T} x^{\prime}+\left(x^{T} x^{\prime}\right)\left(x^{T} x^{\prime}\right) \end{aligned} Φ2(x)TΦ2(x′)=1+i=1∑dxixi′+i=1∑dj=1∑dxixjxi′xj′=1+i=1∑dxixi′+i=1∑dxixi′j=1∑dxjxj′=1+xTx′+(xTx′)(xTx′)
Φ 2 ( x ) \Phi_2(x) Φ2(x)和 Φ 2 ( x ′ ) \Phi_2(x') Φ2(x′)内积的复杂度由原来的 O ( d 2 ) O(d^2) O(d2)变成 O ( d ) O(d) O(d),只与 x x x空间的维度 d d d有关,而与z空间的维度 d ^ \hat d d^无关
合并特征转换和计算内积这两个步骤的操作叫做Kernel Function
kernel trick
1、在dual SVM中,二次项系数 q n , m q_{n,m} qn,m中有z的内积计算,就可以用kernel function替换: q n , m = y n y m z n T z m = y n y m K ( x n , x m ) q_{n,m}=y_ny_mz_n^Tz_m=y_ny_mK(x_n,x_m) qn,m=ynymznTzm=ynymK(xn,xm)
直接计算出 K ( x n , x m ) K(x_n,x_m) K(xn,xm),再代入上式,就能得到 q n , m q_{n,m} qn,m的值
2、通过QP得到拉格朗日因子 α n \alpha_n αn。下一步就是计算b(取 α n > 0 \alpha_n>0 αn>0的点,即SV),b的表达式中包含z: b = y s − w T z s = y s − ( ∑ n = 1 N α n y n z n ) T z s = y s − ∑ n = 1 N α n y n ( K ( x n , x s ) ) b=y_s-w^Tz_s=y_s-(\sum_{n=1}^N\alpha_ny_nz_n)^Tz_s=y_s-\sum_{n=1}^N\alpha_ny_n(K(x_n,x_s)) b=ys−wTzs=ys−(n=1∑Nαnynzn)Tzs=ys−n=1∑Nαnyn(K(xn,xs))
这样b也可以用kernel function表示,与z空间无关
3、最终得到: g S V M ( x ) = s i g n ( w T Φ ( x ) + b ) = s i g n ( ( ∑ n = 1 N α n y n z n ) T z + b ) = s i g n ( ∑ n = 1 N α n y n ( K ( x n , x ) ) + b ) g_{SVM}(x)=sign(w^T\Phi(x)+b)=sign((\sum_{n=1}^N\alpha_ny_nz_n)^Tz+b)=sign(\sum_{n=1}^N\alpha_ny_n(K(x_n,x))+b) gSVM(x)=sign(wTΦ(x)+b)=sign((n=1∑Nαnynzn)Tz+b)=sign(n=1∑Nαnyn(K(xn,x))+b)
引入kernel funtion后:

每个步骤的时间复杂度为:
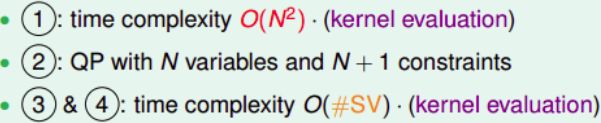
引入kernel function的SVM称为kernel SVM,是基于dual SVM推导而来的
Polynomial Kernel
二次多项式的kernel形式是多种的:

系数不同,内积就会有差异,代表有不同的距离,最终可能会得到不同的SVM margin。第三种 Φ 2 ( x ) \Phi_2(x) Φ2(x)(绿色标记)简单一些,更加常用

自由度 γ \gamma γ影响margin和SV:
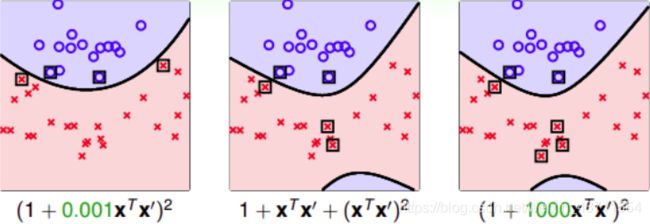
通过改变不同的系数,得到不同的SVM margin和SV,选择正确的kernel非常重要
总之:引入 ζ ≥ 0 \zeta\geq 0 ζ≥0和 γ > 0 \gamma>0 γ>0,对于Q次多项式一般的kernel形式可表示为:

使用高阶多项式kernel的两个优点:
1、得到最大SVM margin,SV数量不会太多,分类面不会太复杂,防止过拟合,减少复杂度
2、计算过程避免了对 d ^ \hat d d^的依赖,大大简化了计算量
多项式阶数Q=1时,那么对应的kernel就是线性的
Gaussian Kernel
Q阶多项式kernel的阶数是有限的,即特征转换的 d ^ \hat d d^有限。如果是无限维转换 Φ ( x ) \Phi(x) Φ(x),是否还能通过kernel简化SVM计算呢?
假设原空间是一维的,只有一个特征 x x x,构造一个kernel function为高斯函数: K ( x , x ′ ) = e − ( x − x ′ ) 2 K(x,x')=e^{-(x-x')^2} K(x,x′)=e−(x−x′)2
构造的过程正好与二次多项式kernel的相反,利用反推法,先将上式分解并做泰勒展开:

其中:
Φ ( x ) = e − x 2 ⋅ ( 1 , 2 1 ! x , 2 2 2 ! x 2 , ⋯ ) \Phi(x)=e^{-x^2}\cdot (1,\sqrt \frac{2}{1!}x,\sqrt \frac{2^2}{2!}x^2,\cdots) Φ(x)=e−x2⋅(1,1!2x,2!22x2,⋯)
Φ ( x ) \Phi(x) Φ(x)是无限多维的,可以作特征转换的函数,且 d ^ \hat d d^是无限的.
Φ ( x ) \Phi(x) Φ(x)得到的核函数即为Gaussian kernel
推广到多维,引入缩放因子 γ > 0 \gamma>0 γ>0,应的Gaussian kernel表达式为:
K ( x , x ′ ) = e − γ ∣ ∣ x − x ′ ∣ ∣ 2 K(x,x')=e^{-\gamma||x-x'||^2} K(x,x′)=e−γ∣∣x−x′∣∣2
前面由 K 计算得到 α n \alpha_n αn 和 b,进而得到矩 g S V M g_{SVM} gSVM。将核函数 K 用高斯核函数代替:
g S V M ( x ) = s i g n ( ∑ S V α n y n K ( x n , x ) + b ) = s i g n ( ∑ S V α n y n e ( − γ ∣ ∣ x − x n ∣ ∣ 2 ) + b ) g_{SVM}(x)=sign(\sum_{SV}\alpha_ny_nK(x_n,x)+b)=sign(\sum_{SV}\alpha_ny_ne^{(-\gamma||x-x_n||^2)}+b) gSVM(x)=sign(SV∑αnynK(xn,x)+b)=sign(SV∑αnyne(−γ∣∣x−xn∣∣2)+b)
上式可以看出, Φ ( x ) \Phi(x) Φ(x) g S V M g_{SVM} gSVM有n个高斯函数线性组合而成,其中n是SV的个数,通常也把高斯核函数称为径向基函数(Radial Basis Function, RBF)
总结:
kernel SVM 可以获得 large-margin 的 hyperplanes,并且可以通过高阶的特征转换使 E i n E_{in} Ein 尽可能小。kernel的引入大大简化了dual SVM的计算量。而且Gaussian kernel能将特征转换扩展到无限维,并使用有限个SV数量的高斯函数构造出矩 Φ ( x ) \Phi(x) Φ(x)。

缩放因子 γ \gamma γ取值不同,会得到不同的高斯核函数,hyperplanes不同,分类效果也有很大的差异:、

所以,SVM也会出现过拟合现象, γ \gamma γ的正确选择尤为重要,不能太大。
Comparison of Kernels
Linear Kernel:
最简单最基本的核,平面上对应一条直线,三维空间里对应一个平面。Linear Kernel可以使用Dual SVM中的QP直接计算得到
优点:
- 计算简单、快速
- 可以直接使用QP快速得到参数值
- 从视觉上分类效果非常直观,便于理解
缺点:
- 如果数据不是线性可分的情况,Linear Kernel就不能使用了

Polynomial Kernel
hyperplanes是由多项式曲线构成
优点:
- 阶数Q可以灵活设置
- 相比linear kernel限制更少
- 更贴近实际样本分布
缺点:
- Q很大时,K的数值范围波动很大
- 参数个数较多,难以选择合适的值
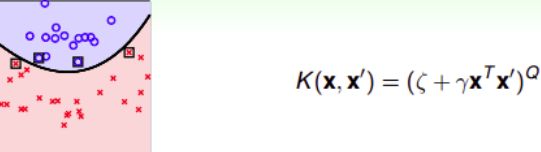

Gaussian Kernel
优点:
- 边界更加复杂多样,能最准确地区分数据样本
- 数值计算K值波动较小
- 只有一个参数,容易选择
缺点:
- 由于特征转换到无限维度中,w没有求解出来
- 计算速度要低于linear kernel,而且可能会发生过拟合
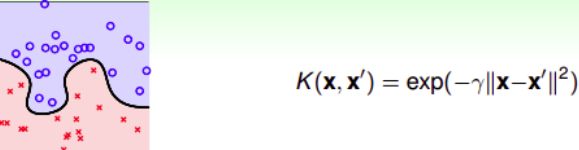

有效的kernel还需满足几个条件(Mercer 定理):
- K是对称的
- K是半正定的

4 – Soft-Margin Support Vector Machine
Kernel SVM不仅能解决简单的线性分类问题,也可以求解非常复杂甚至是无限多维的分类问题,关键在于核函数选择。但前面的这些方法都是Hard-Margin SVM,即必须将所有的样本都分类正确才行。这往往需要更多更复杂的特征转换,甚至造成过拟合。
Motivation and Primal Problem
SVM同样可能会造成overfit:
- SVM模型(即kernel)过于复杂,转换的维度太多
- 要将所有的样本都分类正确,即不允许错误存在,造成模型过于复杂
如何避免过拟合?
- 可以用类似pocket算法的思想,允许有错误点存在,但是尽量让错误点个数变少

SVM允许犯错误的点:

- 对于分类正确的点,仍需满足 y n ( w T z n + b ) ≥ 1 y_n(w^Tz_n+b)\geq 1 yn(wTzn+b)≥1
- 对于noise点,满足 y n ( w T z n + b ) ≥ − ∞ y_n(w^Tz_n+b)\geq -\infty yn(wTzn+b)≥−∞,即没有限制
- 修正后的目标除了 1 2 w T w \frac12w^Tw 21wTw项,还添加了 y n ≠ s i g n ( w T z n + b ) y_n\neq sign(w^Tz_n+b) yn=sign(wTzn+b),即noise点的个数。参数C的引入是为了权衡目标第一项(large margin)和第二项(noise tolerance)的关系,C小表示可以容忍更多的错误点个数,倾向于得到更宽的边界。
对上述条件修正合并得到:

上述式子存在两个不足:
- 最小化目标中第二项是非线性的,不满足QP的条件,所以无法使用dual或者kernel SVM来计算
- 对于犯错误的点,有的离边界很近,即error小,而有的离边界很远,error很大,上式条件和目标没有区分small error和large error
继续修正:引入新参数 ξ n \xi_n ξn 表示每个点犯错误程度 ( ξ n ≥ 0 \xi_n\geq0 ξn≥0),越大表示错得越离谱,即点距离边界(负的)越大。通过使用 error 值的大小代替是否有error,让问题变得易于求解,满足QP形式要求

最终的Soft-Margin SVM的目标为:
m i n ( b , w , ξ ) 1 2 w T w + C ⋅ ∑ n = 1 N ξ n min(b,w,\xi)\ \frac12w^Tw+C\cdot\sum_{n=1}^N\xi_n min(b,w,ξ) 21wTw+C⋅n=1∑Nξn
条件是:
y n ( w T z n + b ) ≥ 1 − ξ n y_n(w^Tz_n+b)\geq 1-\xi_n yn(wTzn+b)≥1−ξn
ξ n ≥ 0 \xi_n\geq0 ξn≥0
对应的QP问题中,由于新的参数 ξ n \xi_n ξn 的引入,总共参数个数为 d ^ + 1 + N \hat d+1+N d^+1+N,限制条件添加了 ξ n > 0 \xi_n>0 ξn>0,则总条件个数为 2N

Dual Problem
由于引入了 ξ n \xi_n ξn,原始问题有两类条件,所以包含了两个拉格朗日因子 α n \alpha_n αn和 β n \beta_n βn:

将Soft-Margin SVM问题转换为如下形式:
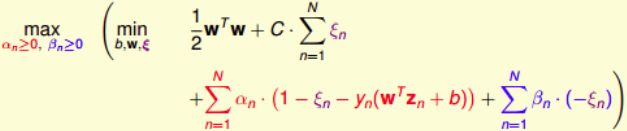
对上式括号里的拉格朗日函数 L ( b , w , ξ , α , β ) L(b,w,ξ,α,β) L(b,w,ξ,α,β) 计算最小值。根据梯度下降算法思想:最小值位置满足梯度为零。
令 ξ n \xi_n ξn偏微分等于0:
∂ L ∂ ξ n = 0 = C − α n − β n \frac {\partial L}{\partial \xi_n}=0=C-\alpha_n-\beta_n ∂ξn∂L=0=C−αn−βn
得到 β n = C − α n \beta_n=C-\alpha_n βn=C−αn,因为有 β n ≥ 0 βn≥0 βn≥0,所以限制 0 ≤ α n ≤ C 0≤\alpha_n≤C 0≤αn≤C。将 β n = C − α n \beta_n=C-\alpha_n βn=C−αn 带入上式, β n β_n βn和 ξ n \xi_n ξn都被消去了:

令 b b b 和 w w w 偏导数为零,分别得到:
∑ n = 1 N α n y n = 0 w = ∑ n = 1 N α n y n z n \begin{aligned} \sum^N_{n=1}\alpha_ny_n=0\\ w=\sum^N_{n=1}\alpha_ny_nz_n \end{aligned} n=1∑Nαnyn=0w=n=1∑Nαnynzn
最终标准的Soft-Margin SVM的Dual形式:
min α 1 2 ∑ n = 1 N ∑ m = 1 N α n α m y n y m z n T z m − ∑ n = 1 N α n subject to ∑ n = 1 N y n α n = 0 0 ≤ α n ≤ C , for n = 1 , 2 , … , N implicitly w = ∑ n = 1 N α n y n z n β n = C − α n , for n = 1 , 2 , … , N \begin{array}{ll}{\min\limits_{\alpha}} & {\frac{1}{2} \sum_{n=1}^{N} \sum\limits_{m=1}^{N} \alpha_{n} \alpha_{m} y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}-\sum\limits_{n=1}^{N} \alpha_{n}} \\ {\text { subject to }} & {\sum\limits_{n=1}^{N} y_{n} \alpha_{n}=0} \\ {} & {0 \leq \alpha_{n} \leq C, \text { for } n=1,2, \ldots, N} \\ {\text { implicitly }} & {\mathbf{w}=\sum\limits_{n=1}^{N} \alpha_{n} y_{n} \mathbf{z}_{n}} \\ {} & {\beta_{n}=C-\alpha_{n}, \text { for } n=1,2, \ldots, N}\end{array} αmin subject to implicitly 21∑n=1Nm=1∑NαnαmynymznTzm−n=1∑Nαnn=1∑Nynαn=00≤αn≤C, for n=1,2,…,Nw=n=1∑Nαnynznβn=C−αn, for n=1,2,…,N
Hard-Margin SVM Dual中 α n ≥ 0 \alpha_n\geq0 αn≥0,而Soft-Margin SVM Dual中 0 ≤ α n ≤ C 0≤\alpha_n≤C 0≤αn≤C,且新的拉格朗日因子 β n = C − α n β_n=C−\alpha_n βn=C−αn
在QP问题中,Soft-Margin SVM Dual的参数 α n \alpha_n αn同样是 N N N 个,但是条件由Hard-Margin SVM Dual中的 N + 1 N+1 N+1 个变成 2 N + 1 2N+1 2N+1 个,因为多了 N N N 个 α n \alpha_n αn 的上界条件。

Messages behind Soft-Margin SVM

如何根据 α n \alpha_n αn的值计算 b b b呢?
- 在Hard-Margin SVM Dual中,有complementary slackness条件: α n ( 1 − y n ( w T z n + b ) ) = 0 \alpha_n(1-y_n(w^Tz_n+b))=0 αn(1−yn(wTzn+b))=0
- 找到SV,即 α s > 0 \alpha_s>0 αs>0的点,计算得到: b = y s − w T z s b=y_s−w^Tz_s b=ys−wTzs
在Soft-Margin SVM Dual中,相应的 complementary slackness 条件有两个(因为两个拉格朗日因子 α n \alpha_n αn和 β n β_n βn):
α n ( 1 − ξ n − y n ( w T z n + b ) ) = 0 β n ξ n = ( C − α n ) ξ n = 0 \begin{aligned} &\alpha_n(1-\xi_n-y_n(w^Tz_n+b))=0\\ &\beta_n\xi_n=(C-\alpha_n)\xi_n=0 \end{aligned} αn(1−ξn−yn(wTzn+b))=0βnξn=(C−αn)ξn=0
找到SV,即 α s > 0 \alpha_s>0 αs>0的点,由于 ξ n \xi_n ξn的存在,还不能完全计算出 b b b 的值。
根据第二个complementary slackness条件,如果令 C − α n ≠ 0 C−\alpha_n\neq0 C−αn=0,即 α n ≠ C \alpha_n≠C αn=C,则一定有 ξ n = 0 \xi_n=0 ξn=0,代入到第一个 complementary slackness 条件,即可计算得到 b = y s − w T z s b=y_s−w^Tz_s b=ys−wTzs, 0 < α s < C 0<\alpha_s
b = y s − ∑ S V α n y n K ( x n , x s ) b=y_s-\sum_{SV}\alpha_ny_nK(x_n,x_s) b=ys−SV∑αnynK(xn,xs)
上面求解 b 提到的一个假设是 α s < C α_s
- 一般情况下,至少存在一组SV使 α s < C α_s
αs<C 的概率是很大的。如果出现没有free SV的情况,那么 b 通常会由许多不等式条件限制取值范围,值是不确定的,只要能找到其中满足KKT条件的任意一个 b 值就可以了。

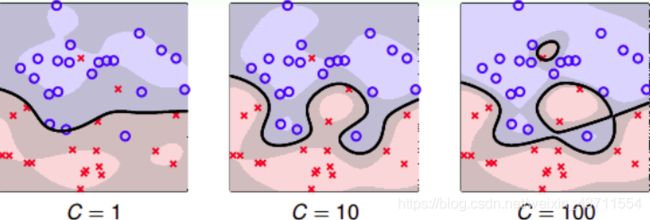
C 取不同的值对margin的影响:
α n \alpha_n αn取不同值对应的物理意义
已知 0 ≤ α n ≤ C 0≤α_n≤C 0≤αn≤C满足两个complementary slackness条件:
α n ( 1 − ξ n − y n ( w T z n + b ) ) = 0 β n ξ n = ( C − α n ) ξ = 0 \begin{aligned} &\alpha_n(1-\xi_n-y_n(w^Tz_n+b))=0\\ &\beta_n\xi_n=(C-\alpha_n)\xi=0 \end{aligned} αn(1−ξn−yn(wTzn+b))=0βnξn=(C−αn)ξ=0
- 若 α n = 0 \alpha_n=0 αn=0,得 ξ n = 0 ξ_n=0 ξn=0, ξ n = 0 ξ_n=0 ξn=0表示该点没有犯错, α n = 0 \alpha_n=0 αn=0表示该点不是SV。所以对应的点在margin之外(或者在margin上),且均分类正确。
- 若 0 < α n < C 0<α_n
0<αn<C ,得 ξ n = 0 ξ_n=0 ξn=0,且 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1。 ξ n = 0 ξ_n=0 ξn=0表示该点没有犯错, y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1表示该点在margin上。这些点即 free SV,确定了 b b b 的值。 - 若 α n = C α_n=C αn=C,不能确定 ξ n = 0 ξ_n=0 ξn=0 是否为零,且得到 1 − y n ( w T z n + b ) = ξ n 1-y_n(w^Tz_n+b)=\xi_n 1−yn(wTzn+b)=ξn,这个式表示该点偏离margin的程度, ξ n \xi_n ξn越大,偏离margin的程度越大。只有当 ξ n = 0 ξ_n=0 ξn=0时,该点落在margin上。所以这种情况对应的点在margin之内负方向(或者在margin上),有分类正确也有分类错误的。这些点称为bounded SV。
所以,在Soft-Margin SVM Dual中,根据 α n \alpha_n αn的取值,就可以推断数据点在空间的分布情况。

Model Selection
在Soft-Margin SVM Dual中,kernel的选择、C等参数的选择都非常重要,直接影响分类效果。例如,对于Gaussian SVM,不同的参数 ( C , γ ) (C,γ) (C,γ),会得到不同的margin:
\qquad 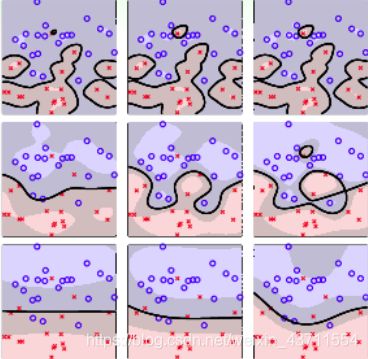 \qquad
\qquad 
横坐标是C逐渐增大的情况,纵坐标是 γ \gamma γ逐渐增大的情况,不同的 ( C , γ ) (C,γ) (C,γ)组合,margin的差别很大。
如何选择最好的 ( C , γ ) (C,γ) (C,γ)等参数呢?
- V-Fold cross validation:将由不同 ( C , γ ) (C,γ) (C,γ)等参数得到的模型在验证集上进行cross validation,选取 E c v E_{cv} Ecv最小的对应的模型就可以了,如上图左下角。
V-Fold cross validation的一种极限就是Leave-One-Out CV,也就是验证集只有一个样本。对于SVM问题,它的验证集Error满足:
E l o o c v ≤ S V N E_{loocv}\leq\frac{SV}{N} Eloocv≤NSV
即,留一法验证集Error大小不超过支持向量SV占所有样本的比例(因为:1、留下的一个验证集非SV,分类必定正确;2、验证集为SV,可能对也可能错)。
一般来说,SV越多,表示模型可能越复杂,越有可能会造成过拟合。所以,通常选择SV数量较少的模型,然后在剩下的模型中使用cross-validation,比较选择最佳模型。
5 – Kernel Logistic Regression
Soft-Margin SVM as Regularized Model

Soft-Margin Dual SVM有两个应用非常广泛的工具包,分别是Libsvm和Liblinear:
Welcome to Chih-Jen Lin’s Home Page
Soft-Margin SVM用 ξ n ξ_n ξn来表示margin violation(犯错时: ξ n = 1 − y n ( w T z n + b ) > 0 \xi_n=1-y_n(w^Tz_n+b)>0 ξn=1−yn(wTzn+b)>0),即犯错值的大小(也可以理解为点到 y n ( w T z n + b ) = 1 y_n(w^Tz_n+b)=1 yn(wTzn+b)=1边界有多远),没有犯错对应的 ξ n = 0 ξ_n=0 ξn=0。然后将有条件问题转化为对偶dual形式,使用QP来得到最佳化的解。将犯错和没犯错的情况整合到一个表达式:
ξ n = m a x ( 1 − y n ( w T z n + b ) , 0 ) \xi_n=max(1-y_n(w^Tz_n+b),0) ξn=max(1−yn(wTzn+b),0)
Soft-Margin SVM最小化问题可变成如下形式:
1 2 w T w + C ∑ n = 1 N m a x ( 1 − y n ( w T z n + b ) , 0 ) \frac12w^Tw+C\sum_{n=1}^Nmax(1-y_n(w^Tz_n+b),0) 21wTw+Cn=1∑Nmax(1−yn(wTzn+b),0)


unconstrained form SVM与L2 Regularization的形式类似,但却不能直接用L2 Regularization的方法来解决unconstrained form SVM的问题。因为:
1、这种无条件的最优化问题无法通过QP解决(对偶推导和kernel都无法使用);
2、包含max()项造成函数不能处处可导,这种情况难以用微分方法解决。


接下来将尝试是否能把SVM作为一个regularized的模型进行扩展,来解决其它一些问题
SVM versus Logistic Regression

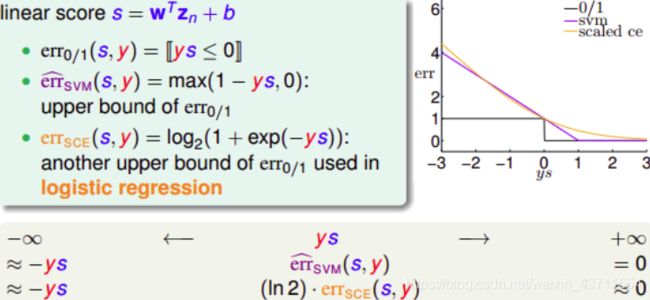
logistic regression中的error function: e r r s c e = l o g 2 ( 1 + e x p ( − y s ) ) err_{sce}=log_2(1+exp(-ys)) errsce=log2(1+exp(−ys))
- e r r ^ s v m \hat{err}_{svm} err^svm在 e r r 0 / 1 err_{0/1} err0/1的上面,所以 e r r ^ s v m \hat{err}_{svm} err^svm可以代替 e r r 0 / 1 err_{0/1} err0/1解决二元线性分类问题
- e r r s c e err_{sce} errsce也在 e r r 0 / 1 err_{0/1} err0/1的上面,而且 e r r s c e err_{sce} errsce和 e r r ^ s v m \hat{err}_{svm} err^svm相近,所以可以把SVM看成是L2-regularized logistic regression
Logistic Regression对应的 e r r s c e err_{sce} errsce优点:
- 是凸函数便于最优化求解
- 有regularization,可以避免过拟合
缺点:
- y s y_s ys很小(负值)时,上界变得更宽松,不利于最优化求解
Soft-Margin SVM对应的 e r r ^ s v m \hat{err}_{svm} err^svm 和 Logistic Regression 类似,而且分类线比较“粗壮”一些。

SVM for Soft Binary Classification
如何将SVM的结果应用在Soft Binary Classification中,得到是正类的概率值?

- 方法一:先得到SVM的解 ( b s v m , w s v m ) (b_{svm},w_{svm}) (bsvm,wsvm),然后直接代入到logistic regression中,得到 g ( x ) = θ ( w s v m T x + b s v m ) g(x)=\theta(w_{svm}^Tx+b_{svm}) g(x)=θ(wsvmTx+bsvm)。直接使用了SVM和logistic regression的相似性,但没有用到logistic regression好的性质和方法。
- 方法二:先得到SVM的解 ( b s v m , w s v m ) (b_{svm},w_{svm}) (bsvm,wsvm),把 ( b s v m , w s v m ) (b_{svm},w_{svm}) (bsvm,wsvm)作为logistic regression的初始值,进行迭代训练修正(速度比较快),把修正后的 ( b , w ) (b,w) (b,w)带入到 g ( x ) = θ ( w T x + b ) g(x)=\theta(w^Tx+b) g(x)=θ(wTx+b)中,但并没有体现出比直接用logistic regression有优势
总之,两种方法都没有融合SVM和logistic regression各自的优势
- 方法三:用 ( b s v m , w s v m ) (b_{svm},w_{svm}) (bsvm,wsvm)、放缩因子A和平移因子B构造一个可以融合SVM和logistic regression优势的模型:
g ( x ) = θ ( A ⋅ ( w s v m T Φ ( x ) + b s v m ) + B ) g(x)=\theta(A\cdot(w_{svm}^T\Phi(x)+b_{svm})+B) g(x)=θ(A⋅(wsvmTΦ(x)+bsvm)+B)如果 ( b s v m , w s v m ) (b_{svm},w_{svm}) (bsvm,wsvm)较为合理,一般满足A>0且 B ≈ 0 B\approx0 B≈0。

新构造的 logistic regression 表达式为:

总体做法可分为三步:

Kernel Logistic Regression
logistic regression怎么用kernel转化为QP问题来解决?
- 如果 w w w 可以表示为 z z z 的线性组合,即 w ∗ = ∑ n = 1 N β n z n w_*=\sum_{n=1}^N\beta_nz_n w∗=∑n=1Nβnzn的形式,那么 w ∗ T z = ∑ n = 1 N β n z n T z = ∑ n = 1 N β n K ( x n , x ) w_*^Tz=\sum_{n=1}^N\beta_nz_n^Tz=\sum_{n=1}^N\beta_nK(x_n,x) w∗Tz=∑n=1NβnznTz=∑n=1NβnK(xn,x),其中包含了z的内积。即:w 可以表示为 z 的线性组合是 kernel trick 可行的关键。
前面的SVM、PLA包扩logistic regression都可以表示成 z 的线性组合:

对于L2-regularized linear model,如果它的最小化问题形式为如下的话,那么最优解 w ∗ = ∑ n = 1 N β n z n w_*=\sum_{n=1}^N\beta_nz_n w∗=∑n=1Nβnzn
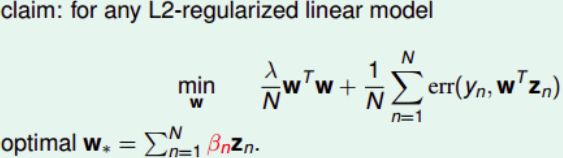
证明:
假设最优解 w ∗ = w ∣ ∣ + w ⊥ w_*=w_{||}+w_{\bot} w∗=w∣∣+w⊥

所以,任何L2-regularized linear model都可以使用kernel来解决
求解:
将 w ∗ = ∑ n = 1 N β n z n w_*=\sum_{n=1}^N\beta_nz_n w∗=∑n=1Nβnzn代入到L2-regularized logistic regression最小化问题中:


上式中,所有的 w w w项都换成 β n \beta_n βn来表示,变成了没有条件限制的最优化问题(把这种问题称为kernel logistic regression),即引入kernel,将求 w w w的问题转换为求 β n \beta_n βn的问题
上式 log 项里的 ∑ m = 1 N β m K ( x m , x n ) \sum_{m=1}^N\beta_mK(x_m,x_n) ∑m=1NβmK(xm,xn)可以看成是变量 β \beta β 和 K ( x m , x n ) K(x_m,x_n) K(xm,xn) 的内积。 ∑ n = 1 N ∑ m = 1 N β n β m K ( x n , x m ) \sum_{n=1}^N\sum_{m=1}^N\beta_n\beta_mK(x_n,x_m) ∑n=1N∑m=1NβnβmK(xn,xm) 可以看成是关于 β \beta β的正则化项 β T K β \beta^TK\beta βTKβ。所以,KLR是 β \beta β的线性组合,其中包含了kernel内积项和kernel regularizer,与SVM是相似的。
但是,KLR中的 β n \beta_n βn与SVM中的 α n \alpha_n αn是有区别的。SVM中的 α n \alpha_n αn大部分为零,SV的个数通常是比较少的;而KLR中的 β n \beta_n βn通常都是非零值。
6 – Support Vector Regression
soft-binary classification 使用 2-level learning,先利用SVM得到参数 b 和 w ,再用 logistic regression 迭代优化,对参数 b 和 w 进行微调,得到最佳解。
前面提到可以通过Representer Theorem,在 z 空间中引入SVM的kernel技巧,直接对logistic regression进行求解。
如何将SVM的kernel技巧应用到 regression 问题上?
Kernel Ridge Regression
如何将kernel技巧引入到岭回归(ridge regression)中去,得到与之对应的analytic solution?
Kernel Ridge Regression问题:

因为最佳解 w ∗ w_∗ w∗必然是 z z z的线性组合
把 w ∗ = ∑ n = 1 N β n z n w_∗=\sum^N_{n=1}\beta_nz_n w∗=∑n=1Nβnzn代入到ridge regression中,将z的内积用kernel替换,把求 w ∗ w_∗ w∗的问题转化成求 β n \beta_n βn的问题:

ridge regression可以写成矩阵的形式,其中第一项可以看成是 β n \beta_n βn的正则项,而第二项可以看成是 β n \beta_n βn的error function。
变成求解 β n \beta_n βn:
E a u g ( β ) = λ N β T K β + 1 N ( β T K T K β − 2 β T K T y + y T y ) ∇ E a u g ( β ) = 2 N ( λ K T I β + K T K β − K T y ) = 2 N K T ( ( λ I + K ) β − y ) \begin{aligned} E_{\mathrm{aug}}(\beta) &=\frac{\lambda}{N} \beta^{T} \mathrm{K} \beta+\frac{1}{N}\left(\beta^{T} \mathrm{K}^{T} \mathrm{K} \beta-2 \beta^{T} \mathrm{K}^{T} \mathbf{y}+\mathbf{y}^{T} \mathbf{y}\right) \\ \nabla E_{\mathrm{aug}}(\beta) &=\frac{2}{N}\left(\lambda \mathrm{K}^{T} \mathrm{I} \beta+\mathrm{K}^{T} \mathrm{K} \beta-\mathrm{K}^{T} \mathbf{y}\right)=\frac{2}{N} \mathrm{K}^{T}((\lambda \mathrm{I}+\mathrm{K}) \beta-\mathbf{y}) \end{aligned} Eaug(β)∇Eaug(β)=NλβTKβ+N1(βTKTKβ−2βTKTy+yTy)=N2(λKTIβ+KTKβ−KTy)=N2KT((λI+K)β−y)
令 ∇ E a u g ( β ) \nabla E_{aug}(\beta) ∇Eaug(β)等于零, ( λ I + K ) (\lambda I+K) (λI+K)的逆矩阵存在,则可得到 β \beta β一种解析解为:
β = ( λ I + K ) − 1 y \beta=(\lambda I+K)^{-1}y β=(λI+K)−1y
K K K满足Mercer’s condition,它是半正定的,而且 λ > 0 λ>0 λ>0,所以 ( λ I + K ) (\lambda I+K) (λI+K)一定是可逆的, ( λ I + K ) (\lambda I+K) (λI+K)大小是 N ∗ N N*N N∗N,时间复杂度是 O ( N 3 ) O(N^3) O(N3)由于核函数 K K K表征的是 z z z空间的内积,除非两个向量互相垂直,否则一般情况下 K K K不等于零。 ( λ I + K ) (\lambda I+K) (λI+K)是dense matrix, β \beta β 的解大部分都是非零值。

- 左边是linear ridge regression:只能拟合直线,它的训练复杂度是 O ( d 3 + d 2 N ) O(d^3+d^2N) O(d3+d2N),预测的复杂度是 O ( d ) O(d) O(d),如果 N N N比 d d d大很多时,这种模型就更有效率。
- 右边是kernel ridge regression:非线性模型更加灵活,训练复杂度是 O ( N 3 ) O(N^3) O(N3),预测的复杂度是 O ( N ) O(N) O(N),均只与 N N N有关。当 N N N很大的时候,计算量也大。

Support Vector Regression Primal
kernel ridge regression应用在classification就叫做least-squares SVM(LSSVM)
对比soft-margin Gaussian SVM和Gaussian LSSVM:
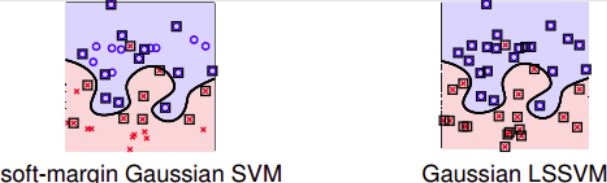
两者分类线几乎相同,但是如果看Support Vector的话(图中方框标注的点)
- 左边SV不多,因为soft-margin Gaussian SVM中的 α n α_n αn大部分是等于零, α n > 0 α_n>0 αn>0的点只占少数,所以SV少。
- 而右边基本上每个点都是SV,因为 β \beta β的解大部分都是非零值,所以对应的每个点基本上都是SV
SV太多会带来一个问题,就是做预测的矩 g ( x ) = ∑ n = 1 N β n K ( x n , x ) g(x)=\sum^N_{n=1}\beta_nK(x_n,x) g(x)=∑n=1NβnK(xn,x),如果 β \beta β非零值较多,那么 g g g的计算量也比较大,soft-margin Gaussian SVM更有优势。

能不能使用一些方法来的得到sparse β \beta β?
- 引入Tube Regression:在分类线上下分别划定一个区域(中立区),如果数据点分布在这个区域内,则不算分类错误,只有误分在中立区域之外的地方才算error
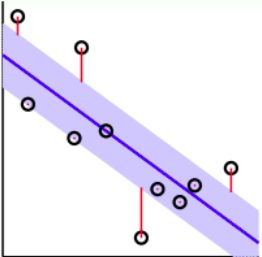

将L2-regularized tube regression做类似于soft-margin SVM的推导,从而得到sparse β \beta β
tube regression中的error与squared error:

e r r ( y , s ) err(y,s) err(y,s)与 s s s的关系曲线:

而在 ∣ s − y ∣ |s-y| ∣s−y∣比较大的区域,squared error的增长幅度要比tube error大很多。error的增长幅度越大,表示越容易受到noise的影响,不利于最优化问题的求解。从这个方面来看,tube regression的这种error function要更好一些。
L2-Regularized Tube Regression:
min w λ N w T w + 1 N ∑ n = 1 N max ( 0 , ∣ w T z n − y ∣ − ϵ ) \min _{\mathbf{w}} \quad \frac{\lambda}{N} \mathbf{w}^{T} \mathbf{w}+\frac{1}{N} \sum_{n=1}^{N} \max \left(0,\left|\mathbf{w}^{T} \mathbf{z}_{n}-y\right|-\epsilon\right) wminNλwTw+N1n=1∑Nmax(0,∣∣wTzn−y∣∣−ϵ)
上式含max项,不是处处可微,不适合用GD/SGD来求解。虽然满足representer theorem,有可能通过引入kernel来求解,但并不能保证得到sparsity β \beta β。可以把这个问题转换为带条件的QP问题,仿照dual SVM的推导方法,引入kernel,得到KKT条件,从而保证解 β \beta β是sparse的。

把L2-Regularized Tube Regression写成类似SVM的形式:

λ \lambda λ越大对应 C C C越小, λ \lambda λ越小对应 C C C越大。而且上式把 w 0 w_0 w0即 b b b单独拿了出来。
有了Standard Support Vector Regression的初始形式,还需要转化成标准的QP问题:

右边即标准的QP问题, ξ n ∨ \xi_n^\vee ξn∨和 ξ n ∧ \xi_n^\wedge ξn∧分别表示upper tube violations和lower tube violations。这种形式叫做Support Vector Regression(SVR) primal。
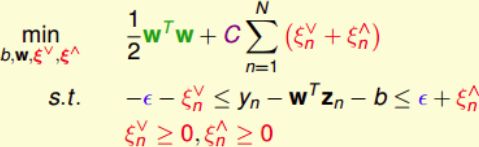
SVR的QP形式共有 d ^ + 1 + 2 N \hat d+1+2N d^+1+2N个参数, 2 N + 2 N 2N+2N 2N+2N个条件。
- C:表示的是regularization和tube violation之间的权衡。large C倾向于tube violation,small C则倾向于regularization。
- ϵ \epsilon ϵ:表征了tube的区域宽度,即对错误点的容忍程度。 ϵ \epsilon ϵ越大,则表示对错误的容忍度越大

Support Vector Regression Dual
接下来将推导SVR的Dual形式
先令拉格朗日因子 α n ∨ \alpha_n^\vee αn∨和 α n ∧ \alpha_n^\wedge αn∧,分别是与 ξ n ∨ \xi_n^\vee ξn∨和 ξ n ∧ \xi_n^\wedge ξn∧不等式相对应

令相关参数偏微分为零,得到相应的KKT条件:

观察SVM primal与SVM dual的参数对应关系,直接从SVR primal推导出SVR dual的形式:

SVR dual形式下推导的解 w w w为:
w = ∑ n = 1 N ( α n ∧ − α n ∨ ) z n w=\sum_{n=1}^N(\alpha_n^{\wedge}-\alpha_n^{\vee})z_n w=n=1∑N(αn∧−αn∨)zn
相应的complementary slackness为:
α n ∧ ( ϵ + ξ n ∧ − y n + w T z n + b ) = 0 α n ∨ ( ϵ + ξ n ∨ + y n − w T z n − b ) = 0 \begin{aligned} \alpha_{n}^{\wedge}\left(\epsilon+\xi_{n}^{\wedge}-y_{n}+\mathbf{w}^{T} \mathbf{z}_{n}+b\right) &=0 \\ \alpha_{n}^{\vee}\left(\epsilon+\xi_{n}^{\vee}+y_{n}-\mathbf{w}^{T} \mathbf{z}_{n}-b\right) &=0 \end{aligned} αn∧(ϵ+ξn∧−yn+wTzn+b)αn∨(ϵ+ξn∨+yn−wTzn−b)=0=0
对于分布在tube中心区域内的点,满足 ∣ w T z n + b − y n ∣ < ϵ |w^Tz_n+b−y_n|<\epsilon ∣wTzn+b−yn∣<ϵ,此时忽略错误, ξ n ∨ \xi_n^\vee ξn∨和 ξ n ∧ \xi_n^\wedge ξn∧都等于零。则complementary slackness两个等式的第二项均不为零,必然得到 α n ∨ = 0 \alpha_n^\vee=0 αn∨=0和 α n ∧ = 0 \alpha_n^\wedge=0 αn∧=0,即 β n = α n ∧ − α n ∨ = 0 \beta_n=\alpha_n^{\wedge}-\alpha_n^{\vee}=0 βn=αn∧−αn∨=0
所以,对于分布在tube内的点,得到的解 β n = 0 \beta_n=0 βn=0,是sparse的。而分布在tube之外的点, β n ≠ 0 \beta_n\neq0 βn=0。
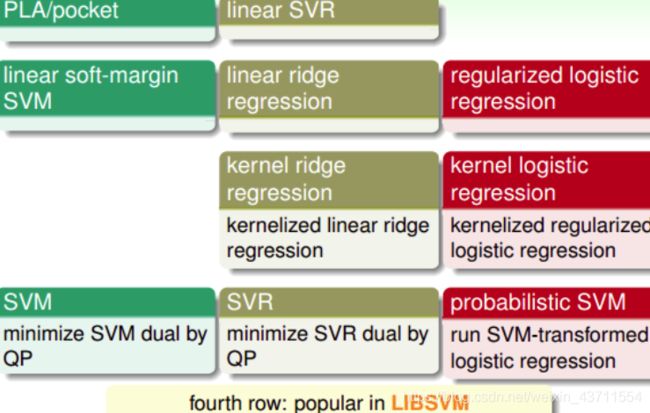
Summary of Kernel Models

上图中相应的模型也可以转化为dual形式,引入kernel:
7 – Blending and Bagging
介绍Aggregation Models,即如何将不同的hypothesis和features结合起来,让模型更好
主要介绍两个方法:Blending和Bagging
Motivation of Aggregation
不同的hypothesis相当于给出了很多不同的的选择,所以选择方法也很重要,一般有:
- 直接选择在验证集上犯错误最小的模型,不能发挥集体的智慧
- 无差别地考虑所有的hypothesis,有点像所谓的民主国家的一人一票
- 考虑所有的hypothesis,但是分配不同的权重
- 权重不是固定的,根据不同的条件,给予不同的权重
就像问朋友买股票的建议

对应以下四个数学模型:
G ( x ) = g t ∗ ( x ) w i t h t ∗ = arg min t ∈ 1 , 2 , ⋯ , T E v a l ( g t − ) G ( x ) = s i g n ( ∑ t = 1 T 1 ⋅ g t ( x ) ) G ( x ) = s i g n ( ( ∑ t = 1 T α t ⋅ g t ( x ) ) w i t h α t ≥ 0 G ( x ) = s i g n ( ( ∑ t = 1 T q t ( x ) ⋅ g t ( x ) ) w i t h q t ( x ) ≥ 0 \begin{aligned} &G(x)=g_{t_*}(x)\ with\ t_*=\argmin\limits_{t\in{1,2,\cdots,T}}\ E_{val}(g_t^-)\\ &G(x)=sign\left(\sum_{t=1}^T1\cdot g_t(x)\right)\\ &G(x)=sign\left((\sum_{t=1}^T\alpha_t\cdot g_t(x)\right)\ with\ \alpha_t\geq0\\ &G(x)=sign\left((\sum_{t=1}^Tq_t(x)\cdot g_t(x)\right)\ with\ q_t(x)\geq0 \end{aligned} G(x)=gt∗(x) with t∗=t∈1,2,⋯,Targmin Eval(gt−)G(x)=sign(t=1∑T1⋅gt(x))G(x)=sign((t=1∑Tαt⋅gt(x)) with αt≥0G(x)=sign((t=1∑Tqt(x)⋅gt(x)) with qt(x)≥0

为什么Aggregation能表现得更好?
\qquad\qquad\qquad 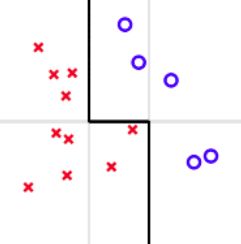 \qquad
\qquad 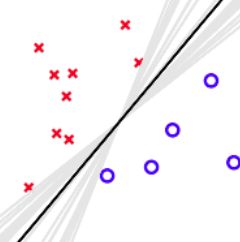
-
如左图:如果要求只能用一条水平的线或者垂直的线进行分类,那不论怎么选取直线,都不能将点完全分开,但如果用水平的和垂直的线组合就可以得到更好地分类效果。这表明:将不同的hypotheses均匀地结合起来,得到了比单一hypothesis更好的预测模型。
-
如右图的PLA算法:将所有可能的hypothesis结合起来,以投票的方式进行组合选择,最终会发现投票得到的分类线就是中间黑色那条。这表明:aggregation也起到了正则化(regularization)的效果,让预测模型更具有代表性。
feature transform和regularization是对立的,aggregation却能将feature transform和regularization各自的优势结合起来。
Uniform Blending
将每一个可能的矩赋予权重1,进行投票,得到的 G ( x ) G(x) G(x)表示为:
g ( x ) = s i g n ( ∑ t = 1 T 1 ⋅ g t ( x ) ) g(x)=sign(\sum_{t=1}^T1\cdot g_t(x)) g(x)=sign(t=1∑T1⋅gt(x))
这种方法对应三种情况:

如果是regression回归问题,uniform blending的做法就是将所有的矩 g t g_t gt求平均值:
G ( x ) = 1 T ∑ t = 1 T g t ( x ) G(x)=\frac1T\sum_{t=1}^Tg_t(x) G(x)=T1t=1∑Tgt(x)
uniform blending for regression对应两种情况:

不同矩 g t g_t gt的组合和集体智慧,都能得到比单一矩 g t g_t gt更好的模型。
证明: ·························································································
1、对单一样本 x x x
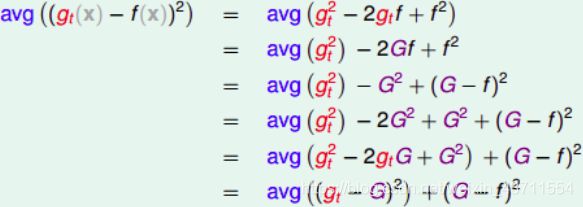
注意: G ( t ) = a v g ( g t ) G(t)=avg(g_t) G(t)=avg(gt)
a v g ( ( g t ( x ) − f ( x ) ) 2 ) − ( G − f ) 2 = a v g ( ( g t − G ) 2 ) > 0 ⟶ g t avg((g_t(x)-f(x))^2)-(G-f)^2=avg((g_t−G)^2)>0\longrightarrow g_t avg((gt(x)−f(x))2)−(G−f)2=avg((gt−G)2)>0⟶gt的平均 G ( t ) = a v g ( g t ) G(t)=avg(g_t) G(t)=avg(gt)表现更好。
2、对整个样本 x x x分布

a v g ( E o u t ( g t ) ) ≥ E o u t ( G ) avg(E_{out}(g_t))\geq E_{out}(G) avg(Eout(gt))≥Eout(G)证明了计算 g t g_t gt的平均值 G ( t ) G(t) G(t)要比单一的 g t g_t gt更接近目标函数 f f f,regression效果更好。
证毕 ·························································································
对 g t g_t gt求平均得到 G G G,当做无限多次,即目标数 T T T趋向于无穷大时:
g ‾ = lim T → ∞ G = lim T → ∞ 1 T ∑ t = 1 T g t = ϵ D A ( D ) \overline{g}=\lim_{T\rightarrow \infty}\ G=\lim_{T\rightarrow \infty}\ \frac1T\sum_{t=1}^Tg_t=\mathop{\epsilon}\limits_DA(D) g=T→∞lim G=T→∞lim T1t=1∑Tgt=DϵA(D)
当T趋于无穷大的时候, G = g ‾ G=\overline{g} G=g,则有如下等式成立:

一个演算法的平均表现可以看成所有 g t g_t gt的共识 + + +不同 g t g_t gt之间的差距,即:bias+variance。因此,uniform blending求平均的过程,削减了variance,使得算法表现更好、更稳定。
- 左边表示演算法误差的期望值,
- 右边第一项表示不同 g t g_t gt与共识的差距是多少,反映 g t g_t gt之间的偏差,用方差 v a r i a n c e variance variance表示;
- 右边第二项表示不同 g t g_t gt的平均误差共识,用偏差bias表示。
Linear and Any Blending
linear blending,每个 g t g_t gt赋予的权重 α t \alpha_t αt并不相同( α t ≥ 0 \alpha_t\geq0 αt≥0),最终得到的预测结果等于所有 g t g_t gt的线性组合:
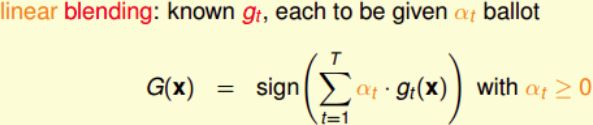
如何确定 α t \alpha_t αt的值,方法是利用误差最小化的思想,找出最佳的 α t \alpha_t αt,使 E i n ( α ) E_{in}(\alpha) Ein(α)取最小值。
例如:
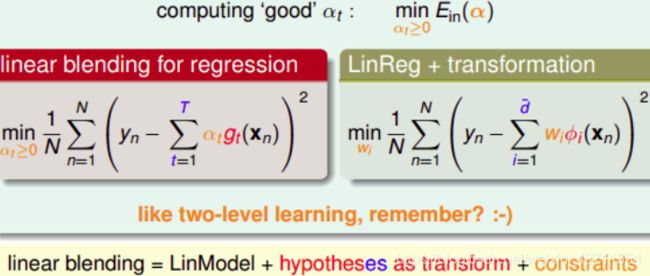
求解 α t \alpha_t αt的方法类似之前的two-level learning,先计算 g t ( x n ) g_t(x_n) gt(xn),再进行linear regression得到 α t \alpha_t αt值。
linear blending由三个部分组成:LinModel,hypotheses as transform,constraints,其实计算过程中可以把 g t g_t gt当成feature transform,求解过程就跟之前没有什么不同

如果 α t < 0 \alpha_t<0 αt<0,会怎么样呢?
- 其实 α t < 0 \alpha_t<0 αt<0并不会影响分类效果,只需要将正类看成负类,负类当成正类即可。这样就可以去掉约束条件了

Linear Blending中的 g t g_t gt是通过模型选择得到的,利用validation,从 D t r a i n D_{train} Dtrain中得到 g 1 − , g 2 − , ⋯ , g T − g_1^-,g_2^-,\cdots,g_T^- g1−,g2−,⋯,gT−,然后将 D t r a i n D_{train} Dtrain中各个矩计算每个数据点得到的值代入到相应的linear blending计算公式中,迭代优化得到对应 α \alpha α值。最终,再利用所有样本数据,得到新的 g t g_t gt代替 g t − g_t^− gt−,则 G ( t ) G(t) G(t)就是 g t g_t gt的线性组合而不是 g t − g_t^− gt−,系数是 α t α_t αt。


除了linear blending之外,还可以使用任意形式的blending。linear blending中, G ( t ) G(t) G(t)是 g ( t ) g(t) g(t)的线性组合;any blending中, G ( t ) G(t) G(t)可以是 g ( t ) g(t) g(t)的任何函数形式(非线性),这种形式的blending也叫做Stacking。
any blending:
- 优点:是模型复杂度提高,更容易获得更好的预测模型
- 缺点:是复杂模型也容易带来过拟合的危险。通过采用regularization的方法,让模型具有更好的泛化能力。
Bagging(Bootstrap Aggregation)
blending的做法就是将已经得到的矩 g t g_t gt进行aggregate的操作。具体的aggregation形式包括:uniform,non-uniforn和conditional

如何得到不同的 g t g_t gt呢?

前面讲的bias-variance:一个演算法的平均表现可以被拆成两项,一个是所有 g t g_t gt的共识(bias),一个是不同 g t g_t gt之间的差距是多少(variance)。每个 g t g_t gt都是需要新的数据集的。只有一份数据集的情况下,如何构造新的数据集?

其中, g ‾ \overline g g是在矩个数T趋向于无穷大的时候,不同的 g t g_t gt计算平均得到的值。
为了得到 g ‾ \overline g g,可以用两个近似条件:
- 有限的T
- 由已有数据集D构造出 D t − P N D_t - P^N Dt−PN,独立同分布(这个近似条件的做法就是bootstrapping)
bootstrapping是统计学工具,从已有数据集D中模拟出其他类似的样本 D t D_t Dt:
- 假设有 N 笔资料,先从中选出一个样本,再放回去,再选择一个样本,再放回去,共重复 N N N 次。就得到了一个新的 N N N笔资料,新的 D ˘ t \breve D_t D˘t中可能包含原 D D D里的重复样本点,也可能没有原 D D D里的某些样本, D ˘ t \breve D_t D˘t 与 D D D 类似但又不完全相同。

用bootstrap进行aggragation的操作就被称为bagging

Bagging Pocket算法的例子如下:
- 先通过bootstrapping得到25个不同样本集,再使用pocket算法得到25个不同的 g t g_t gt,每个pocket算法迭代1000次。最后,再利用blending,将所有的 g t g_t gt融合起来,得到最终的分类线(黑线)
- bootstrapping会得到差别很大的分类线(灰线),但是经过blending后,得到的分类线效果不错,所以bagging通常能得到很好的分类模型。
- 注意:只有当演算法对数据样本分布比较敏感的情况下,才有比较好的表现。

8 – Adaptive Boosting
Motivation of Boosting
将简单的hypotheses g t g_t gt很好地融合,可以得到更好的预测模型G。例如,二维平面上简单的hypotheses(水平线和垂直线),有效组合可以很好地将正负样本完全分开。
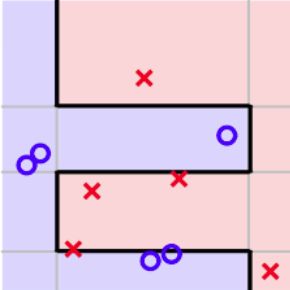
Diversity by Re-weighting
Bagging的核心是bootstrapping,通过对原始数据集 D D D不断进行bootstrap的抽样动作,得到与 D D D类似的数据集 D ^ t \hat D_t D^t,每组 D ^ t \hat D_t D^tt都能得到相应的 g t g_t gt,从而进行aggregation操作。
假如:~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~

对于新的 D ^ t \hat D_t D^t,base algorithm找出 E i n E_{in} Ein最小时对应的 g t g_t gt:
E i n 0 / 1 ( h ) = 1 4 ∑ n = 1 4 [ y ≠ h ( x ) ] E_{in}^{0/1}(h)=\frac14\sum_{n=1}^4[y\neq h(x)] Ein0/1(h)=41n=1∑4[y=h(x)]
由于 D ^ t \hat D_t D^t完全是 D D D经过bootstrap得到的,其中各个样本出现次数不同。引入一个参数 u i u_i ui来表示原 D D D中第 i i i个样本在 D ^ t \hat D_t D^t中出现的次数:
E i n u ( h ) = 1 4 ∑ n = 1 4 u n ( t ) ⋅ [ y n ≠ h ( x ) ] E_{in}^{\color{blue}u}(h)=\frac14\sum_{n=1}^4{\color{blue}u_n}^{(t)}\cdot [y_n\neq h(x)] Einu(h)=41n=1∑4un(t)⋅[yn=h(x)]

参数 u u u相当于是权重因子, D ^ t \hat D_t D^t中第 i i i个样本出现的次数越多,对应的 u i u_i ui越大,表示在error function中对该样本的惩罚越多
所以,bagging其实就是通过bootstrap的方式得到这些 u i u_i ui值,再用base algorithn最小化包含 u i u_i ui的error function,得到不同的 g t g_t gt。这个error function被称为bootstrap-weighted error。
最小化bootstrap-weighted error的算法叫做Weightd Base Algorithm:
minimize (regularized) E in u ( h ) = 1 N ∑ n = 1 N u n ⋅ err ( y n , h ( x n ) ) \begin{array}{l}{\text { minimize (regularized) }} \\ {\qquad E_{\text { in }}^{\mathrm{u}}(h)=\frac{1}{N} \sum_{n=1}^{N} {\color{blue}u_{n}} \cdot \operatorname{err}\left(y_{n}, h\left(\mathbf{x}_{n}\right)\right)}\end{array} minimize (regularized) E in u(h)=N1∑n=1Nun⋅err(yn,h(xn))
weightd base algorithm和之前算法类似,如:
- soft-margin SVM引入允许犯错的项,同样可以将每个点的error乘以权重因子 u n u_n un。加上该项前的参数 C C C,经过QP,最终得到 0 ≤ α n ≤ C u n 0≤\alpha_n≤Cu_n 0≤αn≤Cun。有别于之前的 0 ≤ α n ≤ C 0≤\alpha_n≤C 0≤αn≤C。这里的 u n u_n un相当于每个犯错的样本的惩罚因子,并会反映到 α n \alpha_n αn的范围限定上。
- 同样在logistic regression中,对每个犯错误的样本乘以相应的 u n u_n un作为惩罚因子。 u n u_n un表示该错误点出现的次数, u n u_n un越大,则对应的惩罚因子越大,则在最小化error时就应该更加重视这些点。

由上节可知: g t g_t gt越不一样,其aggregation的效果越好,即每个人的意见越不相同,越能运用集体的智慧,得到好的预测模型。不同的 u u u组合经过base algorithm得到不同的 g t g_t gt。那么如何选取 u u u,使得到的 g t g_t gt之间有很大的不同呢?
先看看 g t g_t gt和 g t + 1 g_{t+1} gt+1怎么得到:

如上所示, g t g_t gt是由 u n t u^t_n unt得到的, g t + 1 g_{t+1} gt+1是由 u n ( t + 1 ) u^{(t+1)}_n un(t+1)得到的。如果 g t g_t gt代入 u n ( t + 1 ) u^{(t+1)}_n un(t+1)时得到的error很大,即预测效果非常不好,那就表示由 u n ( t + 1 ) u^{(t+1)}_n un(t+1)计算的 g t + 1 g_{t+1} gt+1会与 g t g_t gt有很大不同
具体怎么做呢?
- 如果在 g t g_t gt作用下, u n ( t + 1 ) u^{(t+1)}_n un(t+1)中的表现(即error)近似为0.5的时候,表明 g t g_t gt对 u n ( t + 1 ) u^{(t+1)}_n un(t+1)的预测分类没有什么作用,最大限度地保证 g t + 1 g_{t+1} gt+1会与 g t g_t gt有较大的差异性:

- 做一些等价处理,其中分式中分子是 g t g_t g