推荐系统中的图形注意协同相似度嵌入
DASFAA 2021: Database Systems for Advanced Applications
1.引言:
提出了图注意协作相似性嵌入(GACSE),这是一种新的推荐框架,它利用用户-项目二部图中的协作信息进行表示学习。框架由两部分组成:第一部分是通过带有注意力机制的嵌入传播学习显式图协同过滤信息,例如用户-项目关联,第二部分是学习隐式图协同过滤信息,例如用户-用户相似度和项目项目相似度,通过辅助损失。设计了一个新的损失函数,将BPR损失与自适应边距和相似性损失相结合用于相似性学习。
2.介绍:
个性化推荐的核心方法是根据用户的历史行为分析用户的潜在偏好,衡量用户选择某个项目的可能性,并为用户定制推荐结果。
协同过滤(CF),矩阵分解(MF),神经协同过滤(NCF)。可学习的CF模型中有两个关键组成部分:1.通过向量表示用户和项目的嵌入。2.交互建模,根据嵌入制定历史交互。
上述模型不足以学习最佳嵌入,主要限制是嵌入没有显式的编码在用户项交互图中传播的写作信息。根据图嵌入中表示学习的思想,提出图神经网络(GNN),(NGCF)(KGAT)
受GNN在推荐方面的成功启发,我们构建了一个基于注意机制的嵌入传播和聚合体系结构来学习每个邻居的可变权重。权重明确表示二部图中用户与项目交互的相关性。
我们提出的(GACSE),在该框架中,嵌入是通过使用注意机制的嵌入传播从直接的用户-项目关联中学习的,以及通过辅助损失、用户-项目相似性在二部图中的间接、用户-用户相似性和项目-项目相似性来学习嵌入。同时结合BPR损失中的自适应余量和相似性损失来优化模型。
3.相关工作
3.1一般推荐
协同过滤根据用户的交互记录来建模用户的偏好。
在CF中:
基于项目的邻域方法通过使用项目到项目的相似度矩阵测量用户与交互历史项目中的项目相似度来估计用户对项目的偏好。
基于用户的邻域方法使用用户对用户的相似度矩阵查找与当前用户相似的用户,然后在其相似用户的交互历史中推荐项目。
MF:将用户和项目向量之间的内积来估计用户对项目的偏好,
基于深度学习的模型视图取代传统的矩阵分解。:神经协同过滤(NCF)通过MLP而不是内积来估计用户偏好。
3.2基于图的推荐
集成从用户项交互图学习的分布式表示。(GC-MC;HOP-Rec;NGCF,PinSage,Multi-GCCF)
4.本文模型
模型GACSE由三部分组成:
1.嵌入层:将用户和项目从一个热向量映射到初始嵌入。
2.嵌入传播层:由两个子层组成:预热层:以等权重传播和聚合图形嵌入;注意层:使用注意机制对相邻节点的嵌入执行非等权重聚合。
3.预测层:将嵌入层和注意层之间的嵌入连接起来,然后输出用户和项目之间的一致性得分。
下图描述为以用户为中心节点,也适用于以项目为中心节点。
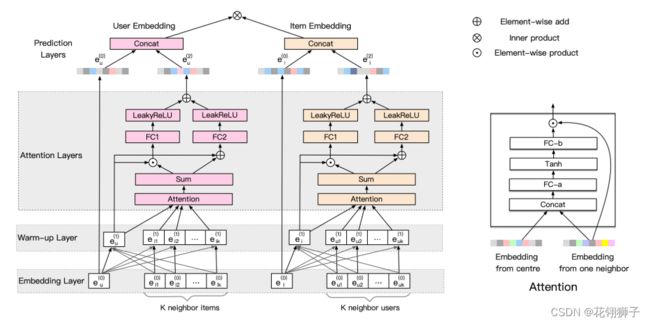
FC1和FC2是用户嵌入端和项目嵌入端的共享参数。左侧显示了注意力聚合的图示。
FC-a将连接的向量转换为新向量。FC-b将向量转换为注意力分数。
1.嵌入层:将用户u和项目i的id映射到嵌入向量e中。
N表示用户数,M表示项目数。

2.嵌入传播层:由两个部分组成:预热层和注意层。两层都有两个步骤:嵌入传播和聚合。
预热层:建立了基于GNN嵌入传播架构的预热层。预热传播在预热层中,我们将所有嵌入设置为具有相等的权重。
W是可训练的权重矩阵,用于在嵌入传播中提取重要信息。Π是i传递给u的嵌入权重。m(i->u)是从项目i到用户u的嵌入。m(u->u)是u的自连接。
每个用户交互项目的权重为相等的:Nu,Ni表示用户u和项目i的第一跳相邻节点。
预热聚合:收到邻居节点的嵌入后,需要对这些嵌入进行聚合。预热层中的用户u的嵌入聚合函数定义为:
σ是非线性激活函数,同样,我们可以得到项目i的嵌入e。
注意层:进一步对邻居的可变权重进行编码,我们构建了一个基于注意机制的嵌入传播和聚合架构。注意机制捕获了二部图中用户和项目之间交互的相关性。
注意传播:与用户交互的每个项目重要性不同,将注意力机制引入到嵌入传递函数中:Π代表注意力权重
本文的评分函数:图右侧attention部分
V,P是可训练参数。||表示串联运算,计算注意分数后,通过softmax对其进行归一化以获得注意权重:Su是在这个小批量中采样的一组用户u的单跳相邻项目,
注意力聚合:经过注意力传播后,聚合函数定义为:
σ是LeakyReLU非线性函数。W是可训练的参数。e2u不仅与e1i相关,而且对e1u和e1i之间的交互进行编码。交互信息由m(u->u)和m(i->u)之间的元素乘积表示。 类似的也能得到i的注意力层嵌入e2i。我们结合注意力机制来学习公式(5)中可变的权重Π。


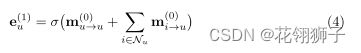

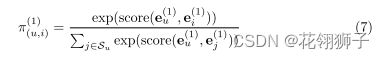
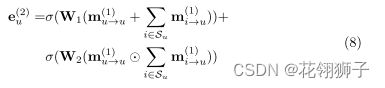
3.模型预测:
经过注意力机制嵌入传递和聚合后,得到了用户节点u的两种不同表示e0u,e2u。项目节点也是类似的。
||表示连接运算。通过内部产品预测用户和项目之间的匹配得分:
4.优化器:
损失函数由两个基本部分组成:具有自适应边距的BPR损失和相似性损失
1.BPR损失:考虑到了观察到的和未观察到的相互作用之间的相对顺序,
B表示小批量的采样数据,包含正负样本,σ是softplus函数,max()表示节点的正样本和负样本越相似,损失函数的余量越大
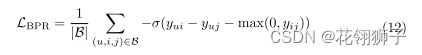
2.相似性损失:图中的u-u,i-i相似性也可以考虑用于嵌入学习。为u-u,i-i引入相似性损失可以通过增加用于表示学习的数据来减少稀疏性问题。将一对用户的2阶邻域接近度定义为相似性。
为了避免在嵌入传播中影响嵌入的相似性损失,我们只计算用户和项目的E和上下文映射嵌入矩阵之间的。上下文映射嵌入矩阵:
相似性损失:
σ是sigmoid函数,用户的正负样本和项目的正负样本。我们采用随机游走和负采样来构造正样本对和负样本对,来减少相似性损失。

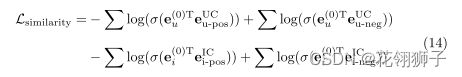
3.整体损失
整体损失函数:
Θ = {E,EUC,EIC,W0,W1,W2,V,P}。λ1控制BPR损失强度,λ2控制L2正则化强度,防止过度拟合。使用adam来优化模型并更新模型参数。
数据集

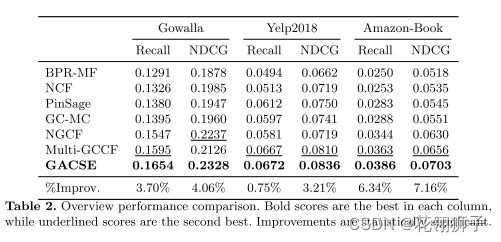
结果
结论:
提出了一个统一的表示学习框架GACSE,该框架通过注意传播从直接的用户-项目交互中学习嵌入,通过辅助损失和二部图中的用户-用户相似度和项目-项目相似度间接学习嵌入。将BPR损失和相似性损失中的自适应余量相结合,对GACSE进行优化。