ApacheCon Asia 回顾|如何通过产品思维运营开源项目
在近日举办的 ApacheCon Asia 大会主题演讲上,Kyligence 联合创始人兼 CEO,Apache Kylin PMC 韩卿给大家带来了「From Open Source to Product,开源项目产品化的思考与实践」的演讲,分享了 Apache Kylin 的最新进展及未来规划,技术和产品思维的对比,以及如何通过产品思维去运营开源社区/项目等话题分享,想了解更多快往下看吧~
以下为韩卿在大会的演讲实录:
大家好!我是韩卿,非常高兴今天能够在 ApacheCon Asia 给大家分享。我记得上次参加 ApacheCon 是在 2016年的温哥华,当时 Apache Kylin 作为首个来自中国的顶级项目刚刚毕业,我们在 ApacheCon 上进行了分享,也参与到了国际社区中。在过去的五年中,我们看到很多来自中国的项目,不断进入孵化器,然后毕业成为顶级项目,整个社区我们的声音也越来越多,我很高兴看到,来自华人的力量、技术及内容越来越多地在全球开源社区里进行发声。
我相信今天有非常多的同学会带来开源文化、社区运营、技术等话题分享,我想从另外一个角度,也就是产品的角度,给大家分享一些我们的经验和看法,即如何用产品思维去运营一个开源项目。今天的分享主要是以下三部分:
- Apache Kylin 的简介及未来规划
- 开源项目中的技术 VS 产品
- 如何通过产品思维运营开源社区/项目

Apache Kylin 的简介及未来规划
Apache Kylin 是在 2014 年从 eBay 中国研发中心贡献到了 ASF,成为了孵化器项目,在2015年的12月,Apache Kylin 毕业成为了顶级项目,这也是第一个来自中国的顶级项目。IPMC 的 VP Ted Dunning 也当时给了我们非常高的评价,他说 Apache Kylin 代表了中国以及亚洲国家在国际开源社区里的贡献和参与。


Apache Kylin 诞生几年来,已经收获了超过 1500 多家客户,全球客户从我们的老东家 eBay,包括 Cisco、Walmart、Apple、Amazon、Microsoft,以及欧洲的 OLX Group 等;同时也有非常多的国内客户,规模以上的互联网公司很多都将 Apache Kylin 作为他们在整个大数据分析里面不可或缺的一个组件,我们也非常高兴看到越来越多社区朋友为 Apache Kylin 的演进与迭代持续做出了贡献。

Apache Kylin 用来做什么的呢?如架构图所示,Kylin 其实充当了传统的数据仓库中最核心的一块——数据集市或者说 OLAP 层,用户会在 Kylin 里面定义相应的数据模型,包括星形模型、雪花模型以及星座模型等,在今年初发布的 Kylin 4.0.0-beta 中我们已经去除了对 Hbase 的依赖,可直接使用 Parquet 作为存储,能在云原生时代更契合云上的应用,这也是我们接下来整个产品演进之一。
除此之外,Kylin 也有非常多其他演进,比如支持实时能力,包括使用 Flink 进行相应的处理。整个过程中,万变不离其宗,我们是为用户的 OLAP 能力所服务。最近业界技术也在不断发展,Kylin 社区也希望通过不断创新,能够兼并所长,为社区用户带来更多价值。各位同学如果对这些技术或话题感兴趣,欢迎加入到 Kylin 社区一起来讨论和贡献。
案例分享

介绍两个简单的案例。第一个案例是来自欧洲的电信公司。这个案例是我在西班牙做展会的时候认识的,他们当时做的是整个国家的网络质量的分析、通讯,包括使用手机的型号、版本以及相应的内容,来提升整个网络服务质量的监控和管理。他们仅需要一个非常小的 Hadoop 集群,在较小的成本下就可以支撑大量的应用。

第二个案例是来自德国的跨境电商平台 OLX 集团,OLX Group 是全球互联网巨头 Prosus 公司的一部分,Prosus 也投资了腾讯等公司,他们使用 K8s 来部署 Apache Kylin,同时使用 Amazon EMR 将 Kylin 的 HBase 集群与 Hadoop HDFS 托管在一起,并且将数据备份到 S3 中。该数据架构还拥有一个自动还原过程,当发现部署中发生崩溃时,该过程可以随时从 S3 恢复所有环境。OLX Group 将 OKTA 用作用户登录的 SAML 联邦身份认证,也把 OpenLDAP 用于用户授权。分析师和非技术用户可以使用一致、全面监控、稳定且可扩展的跨团队环境,轻松顺畅地构建多维数据集并使用 Apache Kylin。更多案例详情大家可以参考 Kylin on AWS 云上运维实践|揭秘 OLX Group 全球数据基础架构
Kylin 版本迭代
接下来介绍一下 Apache Kylin 现在的版本情况。

在今年发布的 Kylin 4.0.0-beta 中,我们已经去除了对 Hbase 的依赖,支持基于 Parquet 的存储,并且 Apache Kylin 4 已经在不同企业开始测试并上线,例如有赞等社区用户已经在 Meetup 中分享了一些性能优化和运维实践,效果还是相当不错的。
我们今年还会做几个比较重要的工作,一个是支持 Spark3,能够快速引入到 Spark 最新能力。另外,Apache Kylin 在很多时候是以性能著称,但大家对性能的追求永远没有终点。我们计划今年带来新的技术,包括 LocalCache 以及 SoftAffinity 等。存储和计算虽然分离,但又要在软亲和性能力上可以放到一起,这对我们来说是比较新的一块领域,也在不断地进行探索,希望各位有兴趣的点可以在这个上面,在社区里可以给我们进行进一步的探讨,我们已经做了相关的研究,我们可以看到这里能够带来的非常大的变化,能够不断地提升系统的性能和稳定性。
另外一方面,我们也会在接下来不断地想办法去除对整个 Hadoop 的依赖,虽然 Apache Kylin 在出生时是作为 Hadoop 上的 OLAP,但是随着这两年云计算的迅速发展,云原生已经是大势所趋,我们今年也会花比较大的精力去更好地拥抱云原生。
得益于 Apache Kylin 最早的可插拔架构,使得我们对于相应的依赖其实都是有条件随时更换底层存储的,我们也在逐步迁移到 K8s 上。

未来我们也会更多地在整个的 CloudNative 上不断进行一些投入。核心的目标,我们希望能够将 Apache Kylin 从原来依托于 Hadoop 做 OLAP,变成转换为一个纯 self-contained 的 OLAP 的能力。我们也会将整个资源的调度、依赖完全迁移到 K8s 方面上,我们会将存储更多面向到对象存储上,我们也希望将其他的一些组件不断地更换成更加通用的组件之后,使得整个的依赖会更少、部署更简单。
我们预期在明年做到,用户给到一堆机器,或者一些 K8s 的资源,我们就能够直接部署上、使用起来,不再需要任何 Hadoop 的依赖。好处在于,一方面我们会确保整个的系统会平滑地过渡,这对于现在使用 Hadoop 的客户来说,是非常重要的;客户在保护现有投资的同时,在向未来转变的过程中,不用担心很多事情重来一遍。我相信,在未来的三到五年,随着云计算、云原生的崛起,一定会对 Hadoop 带来一些影响。如何平滑地过渡?如何更好地将现有的这些应用以最小的成本、最小的代价迁移过去?我相信这是一个非常值得探讨和投入的方向。
技术 VS 产品
接下来,给大家分享我们在打造开源项目以及运营社区过程中得到的一些思考。在技术方面,这次大会有很多技术专家和行业大佬,但是在产品方面可能会被略微忽略,今天我想探讨技术和产品相关的话题。

借用这张图,大家可以看到产品和技术其实是不一样的。技术研发更多地是突破某一个技术上的挑战,然后去做创新,但是产品往往是将一些技术或者想法变成市场的行为,能够满足更多的用户和应用场景。两者的出发点其实也不一样,技术往往是从某一个点进行深入地研究和投入,但是产品可能首先要想市场情况、生产成本等问题,两者不一样,但又是紧密相连的。

技术是让自己爽,产品是让别人爽。技术让自己爽的原因在于,是说我们今天做了一个很好的算法、架构或者框架等,自己会有很大的成就感。但是我们做产品的时候,情况就不同了,因为只有自己爽是不够的,我们一定要让别人爽,用户要用得开心、用得舒服。
以 Apache Kylin 为例,刚做出来的时候我们都非常兴奋,但是在刚开源出来的前三个月,我们非常痛苦,因为社区里很多用户发现在兼容性、编译、适配等方面都出现了各种问题。在这两年我们的工作中,更大的感悟在于,如果只是把一个技术点做出来是远远不够的。我们如何让更多的人使用好你的技术?也就是,你的产品怎么让别人用得爽?这其实要思考的往往比技术角度要多得多,甚至很多事情是不得不去做的。

另外一点,我们讲技术更专注在问题本身,产品更专注在价值本身。技术往往是我们碰到了一些挑战,比如是性能、并发、或者某些算法等,通过一些技术、论文、能力,把它变成一个解决方案。但是从产品角度考虑,非常重要的是在技术解决了问题之后,我们如何把它变成一个有价值的产品。这里不是说要把项目变现,因为开源项目本身就是免费的,我们更应该关注的是,如何让用户能够获得从项目中获得价值?这其实是一个非常有挑战的点。
我最早去美国进行社区交流的时候,很多人会问为什么会把 GUI 都开源出来了?这是一个非常重要的点,如果我们只关注在技术本身,只有分享一个脚本能够解决问题吗?或许能解决,但是用户要花大量的工作去使用它。我们直接把 GUI 给开源出来,就是希望用户可以直接使用起来。当产品越来越容易使用,就能给用户带来更多价值,用户能关注到解决问题之后的业务价值,而不在于技术本身。大家对性能的追求是没有终点的,但是仍要通过一些创新的方式来追求技术和产品这两者的平衡。

我总结下来一句话叫做没有好的技术,产品一定没有竞争力,但是如果没有好的产品,技术就没有生命力。优秀的技术出来之后,一定需要产品让人去使用起来,好的技术需要好的产品来配合,同时好的产品也需要有技术来作为支撑。

我们可以看到,开源是目前最佳的、也是最快的让基于技术的产品不断打磨的方式,通过开源,能让一个项目更快地成熟、被使用、甚至教育市场等。尤其是这一两年,开源社区和项目得到了更多关注,也希望未来有更多朋友不断被激发,去从参与开源、贡献开源,不断壮大开源社区。

如何通过产品思维运营开源社区和项目
接下来分享如何像产品一样去运营开源项目。参与开源这么多年以来,给大家的建议是希望各位能够从技术角度之外做一些思考,因为即使是一个很简单的开源项目,甚至一个小工具,也需要不断地去宣传、演进,去找到用户。这其实和做一个产品本质上没有任何的区别,我们经常开玩笑说产品经理是一个产品的 CEO,其实对于一个开源项目的负责人来说,其实就是这个项目的 CEO,如何运营好产品和社区,已经超越了技术本身。


上图是 Product Led Growth,这个图常常被用来描述商业产品的发展阶段,但是其实开源项目也是一样,只不过整个过程中,可能不太需要市场和销售团队,因为开源社区本身已经可以做到了。
开源在这个阶段的好处是什么?当一个新技术或产品走向市场的时候,能以更早的时间、更低的成本让用户使用起来。但是,在后期阶段,有一点不容忽视,大家可以看到图上有一个 Customer Success Team,对应到开源社区就是去不断地做社区运营、用户支持等。
从 Apache Kylin 开源早期到现在,我们对社区的支持依然是非常繁忙的,其实大家也可以看到,在整个的过程中,我们的目的其实是让开源的用户用起来,和这个 Life Cycle 是高度重合的。
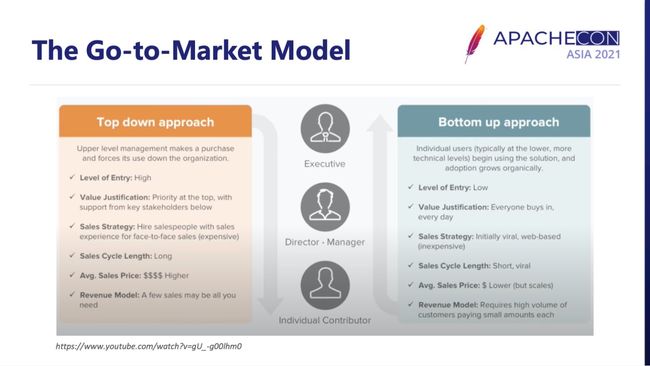
除此之外,如果你想把一个开源项目做大,我是非常推荐大家去看一下 A16Z 的 Go-to-Market Model 的,这里有两个不同的模式,一种叫 Top down,一种叫 Bottom up,其实是通过不同方式去打开方向,这里就不再多做介绍了。


开源一个项目其实只是开始,对于运营的负责人来说,不可能靠一个人就做到所有工作,必须通过相应方式去组队。最近,我也看到越来越多中国的开源项目在这方面上进行了巨大投入,的确也带来了巨大的影响和收获,也希望这张图给大家带来更多关于开源项目及产品的思考。
最近和很多做开源的朋友聊天,其实在运营开源项目中,我们很容易陷入一个点,例如很多人做了某个开源项目,收获了非常多的用户,但是如果想把它变成一个更大的梦想,往往会发现存在不少挑战。

这幅图可以帮我们去设置产品能力,匹配行业需求,解决客户真正的痛点,才能收获更多用户。以 Apache Kylin 为例,当时在 Hadoop 上做大规模的数据分析其实是非常难,而且是效率很低的。通过 Apache Kylin 的 OLAP Server,能让用户在最短时间内获得分析报告,无需花大量时间去跑各种脚本等,当用户有一个痛点,我也有一个非常好的解决方案,同时这个解决方案还有巨大的普适性,客户就会越来越多地使用起来。当我们设计自己的开源项目或者技术的时候,一定要回答产品价值、定位等问题,如果回答不出这些业务角度的问题,可能就会把产品带往错误的方向。

最后给大家分享一下死亡之谷。虽然这个常常用于评估创业公司,但对于开源项目来说,其实本质是一样的。任何一个开源项目都要自己的生命周期,当然,很多开源项目往往也躲不过死亡之谷。
最近,其实大家也看到很多 Apache 项目已经被淘汰了,其实是因为它在某种程度上可能失去了一些价值等。在运营开源项目的时候,希望大家一定要有这样的意识,不是说我们把它开源出来,就一定有人使用,或者是说它会长存,它一样会经历死亡之谷的过程,我们都能做的就是让开源项目去不断演进和迭代,给用户带来更大的价值。
举一个例子,在 Apache Kylin 开源的五年多来,如果我们还只是提供基于 Hadoop 的解决方案,可能再过几年就会慢慢消失了。在社区发展过程中,我们也是不断地探讨,希望抗过一个又一个的死亡之谷。从去年开始我们逐步拥抱云原生,这幅图希望大家给大家带来更多思考,尤其是每个开源项目的负责人,对自己和社区都负责任。
非常感谢各位,也希望有机会可以和大家聚一下,一起聊聊如何把开源做得更好,不仅在中国做大社区和影响力,甚至能够影响到全球。