生物医学图像处理系列1-GRUU-Net(pytorch实现)
GRUU-Net:《GRUU-Net: Integrated convolutional and gated recurrent neural network for cell segmentation》发在2019年Medical Image Analysis刊上,是该领域的顶刊,21年影响因子为8.545。

引文
在生物医学图像处理中,DL方法已经统治并取代了传统的一些分割方法。而用于分割的这些方法中,工作都是基于卷积神经网络特别是FCN、U-Net等这些网络展开,这也是基于卷积神经网络可以获得不同尺度上的聚合特征的优势所决定的。尤其是U型网络U-Net,已在这个领域中演化出十分多优秀的工作,比如U-Net++、Attention-U-Net等,这些网络本文作者也曾介绍过。
在较早的时候,DeepLab的作者通过条件随机场(CRF)来细化结果。在本文中,作者联想到循环神经网络(RNN)也可以实现如CRF的功能。
作者发现:
- CNN在捕获层次模式和提取抽象特征方面很有效,但是在分割中,对每个像素点单独分割时,则缺少全局的先验知识(这也是近年来语义分割领域一直在致力解决的问题)。
- 与CNN相反,RNN可以组合多个弱预测结果,使用多个结果先验来进行迭代更新,可以生成更加精确的结果。同时RNN的参数比CNN更少。比较可惜的是,目前还没有RNN用来实现多个尺度上的特征处理。
- 根据上面两点,作者提出了FRDU单元,来实现多个尺度上的CNN和RNN特征聚合。
模型
GRUU-Net模型结构同样基于U-Net,其中主要由FRDU、GRU和Res Block组成。
 图1 GRUU-Net结构
图1 GRUU-Net结构
GRU-Gated Recurrent Unit
我们先介绍原始的GRU,GRU(Gated Recurrent Unit)是循环神经网络的一种,和LSTM(Long-Short Term Memory)一样用来解决长期记忆的问题。
如果把GRU看成一个黑盒,那我们可以这么理解:输入前一时刻的状态![]() 和当前的输入
和当前的输入![]() ,得到下一个时刻状态
,得到下一个时刻状态![]() 和输出结果
和输出结果![]() 。
。
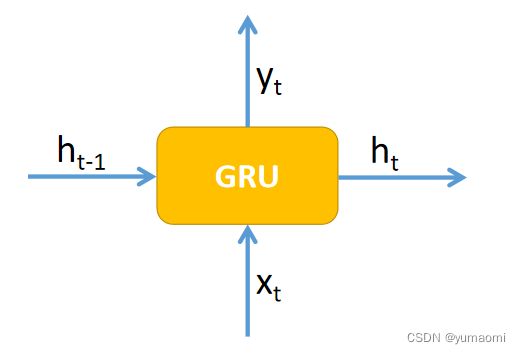 图2 GRU黑盒模型
图2 GRU黑盒模型
而对于其内部结构:圆圈o代表着矩阵乘法,圆圈+代表结果相加。其中![]() 是GRU的门控,用于选择记忆和遗忘。对于更多的GRU介绍,可以移步:《人人都能看懂的GRU》
是GRU的门控,用于选择记忆和遗忘。对于更多的GRU介绍,可以移步:《人人都能看懂的GRU》
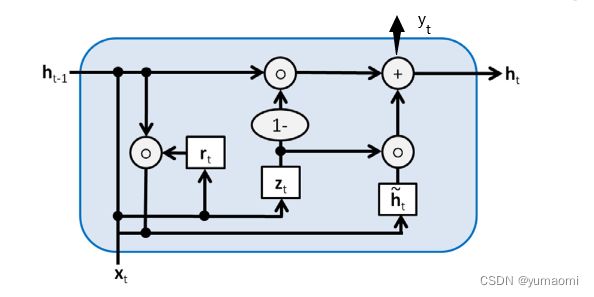 图3 GRU内部
图3 GRU内部
ConvGRU
由于本文模型需要结合CNN和GRU,而传统意义上的GRU是用来处理序列模型,所以需要把GRU内部的全连接层更改为卷积层。但总体结构上与GRU是一样的。
 图4 原文ConvGRU结构
图4 原文ConvGRU结构
对于其中的字母一些运算:
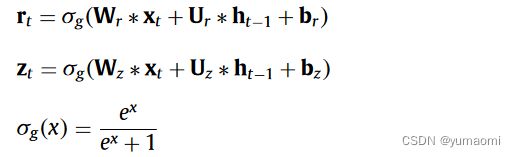
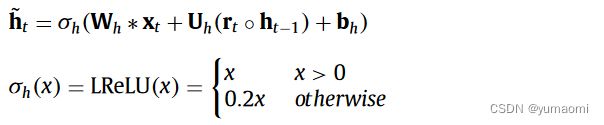
![]()
作者这里实现了原文中的ConvGRU并通过代码来帮助理解,所有字母都对应了图中的符号(忽略了bias)。
class ConvGRU(nn.Module):
def __init__(self, x_channels=64, channels=32):
super(ConvGRU, self).__init__()
self.channels = channels
self.x_channels = x_channels
self.conv_x_z = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_z = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_x_r = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_r = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_u = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
#self.conv_out = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.lReLU = nn.LeakyReLU(0.2)
def forward(self, x, h_t_1):
"""GRU卷积流程
args:
x: input
h_t_1: 上一层的隐含层输出值
shape:
x: [in_channels, channels, width, lenth]
"""
z_t = F.sigmoid(self.conv_x_z(x) + self.conv_h_z(h_t_1))
r_t = F.sigmoid((self.conv_x_r(x) + self.conv_h_r(h_t_1)))
h_hat_t = self.lReLU(self.conv(x) + self.conv_u(torch.mul(r_t, h_t_1)))
h_t = torch.mul((1 - z_t), h_t_1) + torch.mul(z_t, h_hat_t)
# 由于该模型中不需要输出y,这里注释掉
#y = self.conv_out(h_t)
return h_t
x = torch.randn(1, 128, 16, 16)
h_t_1 = torch.randn(1, 32, 16, 16)
conv = ConvGRU(x_channels=128)
h_3 = conv(x, h_t_1)
print(h_3.size())FRDU-Full-Resolution Dense Units
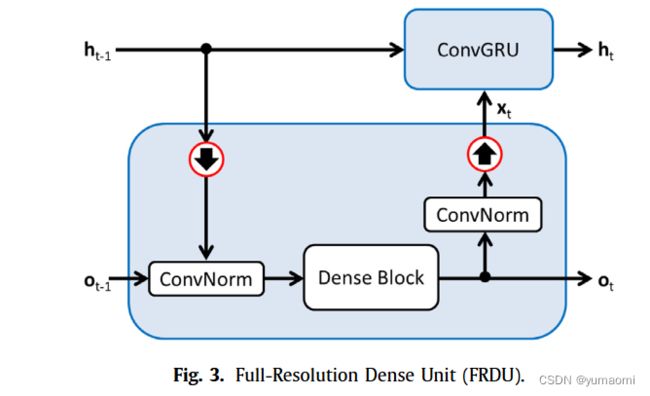 图5 FRDU结构
图5 FRDU结构
FRDU接受了上一个状态的![]() 和上一个输出结果
和上一个输出结果![]() ,需要注意的是,上一个状态的
,需要注意的是,上一个状态的![]()
和 ![]() 形状是不同的(主要体现在网络中),ConvGRU在于网络的顶层,其大小与输入的形状相同,而
形状是不同的(主要体现在网络中),ConvGRU在于网络的顶层,其大小与输入的形状相同,而![]() 则在不断的下采样。因此,
则在不断的下采样。因此,![]() 需要进行一个下采样来符合
需要进行一个下采样来符合![]() 。
。
FRDU需要融合上一个ConvGRU的输出和上一个FRDU的输出,所以新结果就是:
![]()
在特征融合之后,作者设计了一个Dense Block来实现特征处理,对于Dense Block,作者在U型网络的不同层次上设计了不同的Dense layer数量。
随后,就有:
![]()
![]()
![]()
输出下一个状态需要的输入,![]() 和
和![]() 。
。
对于FRDU,本文同样给出了代码。
class FRDU(nn.Module):
def __init__(self, in_channels, channels, factor=2):
super(FRDU, self).__init__()
self.maxpool = nn.MaxPool2d(2)
self.factor = factor
self.convNorm1 = nn.Sequential(
nn.Conv2d(in_channels+32, channels, 1),
nn.BatchNorm2d(channels)
)
self.convNorm2 = nn.Sequential(
nn.Conv2d(channels, channels, 1),
nn.BatchNorm2d(channels)
)
self.denseLayer = DenseNet(k = 3, in_features=channels, out_features=channels, bn_size=2)
self.ConvGRU = ConvGRU(x_channels=channels)
def forward(self, o_t_1, h_t_1):
"""
o_t_t: Ot-1输入
h_t_1: GRU的输出h_t_1
"""
h_t_ori = h_t_1
# 原文: We found that using bilinear interpolation instead of max pooling
# decreased the stability of the training.
h_t_1 = F.interpolate(h_t_1 , scale_factor=1/self.factor ,mode='bilinear')
o_t_1 = self.convNorm1(torch.cat([o_t_1, h_t_1], 1))
o_t = self.denseLayer(o_t_1)
x_t = self.convNorm2(o_t)
x_t = F.interpolate(x_t , scale_factor=self.factor ,mode='bilinear')
h_t = self.ConvGRU(x_t, h_t_ori)
return o_t, h_t模型流程
讲完ConvGRU和FRDU之后,我们重新看一下GRUU-Net的网络结构细节。输入通过一个5×5的Conv来实现,每一次FRDU都接受上一层的maxPool结果,在图中使用黑色红圈箭头表示(作者少画了第一个FRDU的maxPool),而最上层的GRU的输入输出形状都和原始输入相同,其中通道数固定为32。实际上,GRU已经添加在FRDU模块中,所以图中画的GRU模块是作者多余画的(而且应该是ConvGRU而不是GRU)。本文在FRDU代码中实现了这一效果。
其余结构类似于U-Net,编码端进行下采样,解码端进行上采样。这里上采样通过双线性插值来实现,而不是像U-Net中使用反卷积。
最后一个ConvGRU的输出,用一个Res Block来处理结果,通过1×1卷积来实现分割。
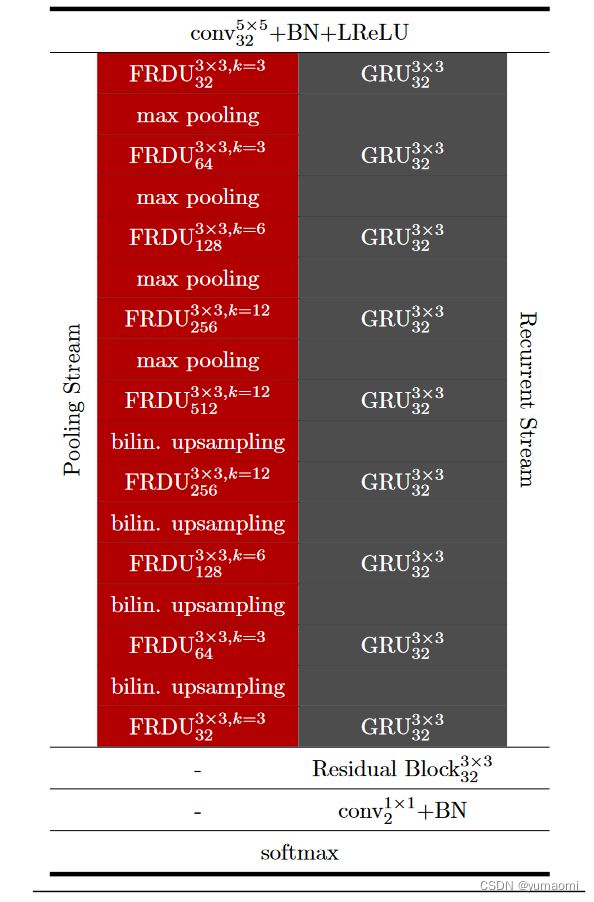 模型参数
模型参数
模型复现
Dense Block
import torch
import torch.nn as nn
import torch.nn.functional as F
class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
#self.add_module("pool", nn.AvgPool2d(2, stride=2))
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, k = 3, in_features=32, out_features=64, bn_size=1, drop_rate=0):
super(DenseNet, self).__init__()
self.features = nn.Sequential()
num_features = in_features
i = 0
num_layers = k
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
transition = _Transition(num_features, out_features)
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(out_features)
# final bn+ReLU
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True))
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
return features
# net = DenseNet(k = 3, in_features=256, out_features=256, bn_size=2)
# x = torch.randn((4,256,224,224))
# net(x).shapeConvGRU
class ConvGRU(nn.Module):
def __init__(self, x_channels=64, channels=32):
super(ConvGRU, self).__init__()
self.channels = channels
self.x_channels = x_channels
self.conv_x_z = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_z = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_x_r = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_h_r = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv = nn.Conv2d(in_channels=self.x_channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.conv_u = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
#self.conv_out = nn.Conv2d(in_channels=self.channels, out_channels=self.channels, kernel_size=3, stride=1, padding=1)
self.lReLU = nn.LeakyReLU(0.2)
def forward(self, x, h_t_1):
"""GRU卷积流程
args:
x: input
h_t_1: 上一层的隐含层输出值
shape:
x: [in_channels, channels, width, lenth]
"""
z_t = F.sigmoid(self.conv_x_z(x) + self.conv_h_z(h_t_1))
r_t = F.sigmoid((self.conv_x_r(x) + self.conv_h_r(h_t_1)))
h_hat_t = self.lReLU(self.conv(x) + self.conv_u(torch.mul(r_t, h_t_1)))
h_t = torch.mul((1 - z_t), h_t_1) + torch.mul(z_t, h_hat_t)
#y = self.conv_out(h_t)
return h_t
# x = torch.randn(1, 128, 16, 16)
# h_t_1 = torch.randn(1, 32, 16, 16)
# conv = ConvGRU(x_channels=128)
# h_3 = conv(x, h_t_1)
# print(h_3.size())FRDU
class FRDU(nn.Module):
def __init__(self, in_channels, channels, factor=2):
super(FRDU, self).__init__()
self.maxpool = nn.MaxPool2d(2)
self.factor = factor
self.convNorm1 = nn.Sequential(
nn.Conv2d(in_channels+32, channels, 1),
nn.BatchNorm2d(channels)
)
self.convNorm2 = nn.Sequential(
nn.Conv2d(channels, channels, 1),
nn.BatchNorm2d(channels)
)
self.denseLayer = DenseNet(k = 3, in_features=channels, out_features=channels, bn_size=2)
self.ConvGRU = ConvGRU(x_channels=channels)
def forward(self, o_t_1, h_t_1):
"""
o_t_t: Ot-1输入
h_t_1: GRU的输出h_t_1
"""
h_t_ori = h_t_1
# 原文: We found that using bilinear interpolation instead of max pooling
# decreased the stability of the training.
h_t_1 = F.interpolate(h_t_1 , scale_factor=1/self.factor ,mode='bilinear')
o_t_1 = self.convNorm1(torch.cat([o_t_1, h_t_1], 1))
o_t = self.denseLayer(o_t_1)
x_t = self.convNorm2(o_t)
x_t = F.interpolate(x_t , scale_factor=self.factor ,mode='bilinear')
h_t = self.ConvGRU(x_t, h_t_ori)
return o_t, h_tGRUUN-et
class GRUU_Net(nn.Module):
def __init__(self, num_classes=2):
super(GRUU_Net, self).__init__()
self.input = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2)
)
self.FRDU_1 = FRDU(32, 64,factor=2)
self.FRDU_2 = FRDU(64, 128,factor=4)
self.FRDU_3 = FRDU(128, 256,factor=8)
self.FRDU_4 = FRDU(256, 512,factor=16)
self.FRDU_5 = FRDU(512, 512,factor=32)
self.FRDU_6 = FRDU(512, 256,factor=16)
self.FRDU_7 = FRDU(256, 128,factor=8)
self.FRDU_8 = FRDU(128, 64,factor=4)
self.FRDU_9 = FRDU(64, 32,factor=2)
self.Resblock = nn.Sequential(
nn.Conv2d(32, 32, 3, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2)
)
self.cls_seg = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
x = self.input(x)
#FRDU1:
o_t, h_t = self.FRDU_1(o_t_1 = nn.MaxPool2d(2)(x), h_t_1 = x)
o_t, h_t = self.FRDU_2(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_3(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_4(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_5(o_t_1 = nn.MaxPool2d(2)(o_t), h_t_1 = h_t)
o_t, h_t = self.FRDU_6(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_7(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_8(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
o_t, h_t = self.FRDU_9(o_t_1 = F.interpolate(o_t, scale_factor=2, mode="bilinear"), h_t_1 = h_t)
h_t = self.Resblock(h_t) + h_t
out = self.cls_seg(h_t)
return out
#Net = GRUU_Net(3)
#o_t_1 = torch.randn((4,3,224,224))
#out = Net(o_t_1)数据集Camvid
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
from PIL import Image
import numpy as np
from albumentations.pytorch.transforms import ToTensorV2
import matplotlib.pyplot as plt
import albumentations as A
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'database/camvid/camvid/' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=True,drop_last=True)Train
model = GRUU_Net(num_classes=33).cuda()
#载入预训练模型
#model.load_state_dict(torch.load(r"checkpoints/Unet++_25.pth"),strict=False)
from d2l import torch as d2l
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5, last_epoch=-1)
#训练50轮
epochs_num = 100
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/GRUU-Net_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/GRUU-Net_{epoch+1}.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)Result
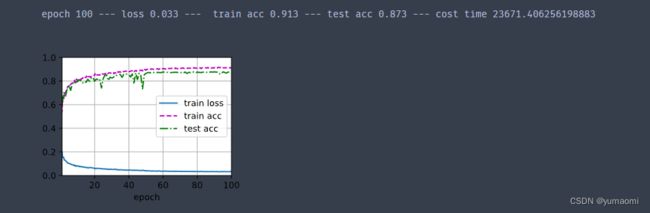
模型运行比较慢,但是效果还不错