写给小白的TensorFlow的入门课
文章目录
-
- 前言
- 学习AI的必要性
-
- 和业务的关系
- 最简单的例子
-
- 要做什么?
- 数据图形化展示
- 构建计算图形
- 计算图形
- 最小化误差
- MacOS 中配置运行环境
-
- 安装
- 验证安装
- 简单模型训练
- 识别数字图片的模型训练
-
- Softmax Regression算法
- 大概步骤
- 大致算法
- 实现
- 结语
- 参考链接
前言
深度学习就是从大量数据中寻找规律,学习什么?学习模型的各种参数。从训练模型到模型推理,都离不开深度学习框架。TensorFlow和PyTorch就是两个最主要的框架。
AI的模型训练其实就是: 对模型变量的值进行不断调整,直到训练模型对所有可能的变量求出的结果都无限接近目标值,而我们要做的工作就是给足够的数据进行训练,以及不断优化训练算法。
学习AI的必要性
自从2016年AlphaGo战胜李世石后,人工智能,深度学习成为最热门的话题。但是其实深度学习其实很早就有,在2012年的ImageNet图像分类竞赛中,深度学习系统AlexNet夺冠其实已经预示着深度学习开启的AI新时代即将到来。
作为一个IT从业人员,如何理解新的AI时代对我们的影响,先看一下下图的数据:
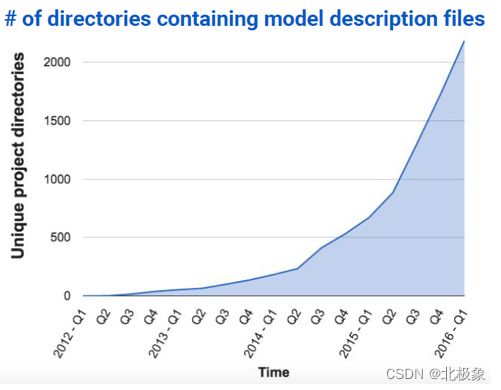
此图是google内部使用tensorflow(机器学习)的状况,整个以指数形进行增长。2016年Q1的时候已经超过2000的项目在使用。人工智能已经变成了一种基础设施,每一个开发&测试都应该有所了解。
和业务的关系
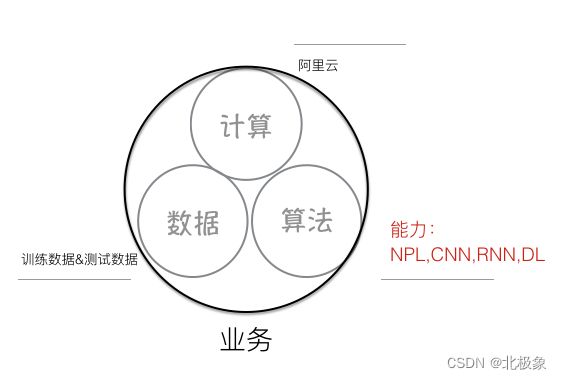
那作为普通的业务开发&测试人员,AI和我们关系如何呢?整理了一下AI对业务的关系,可以理解为如下图:
- 算法:根据不同的使用场景,使用不同的算法来进行支撑,因为tensorflow等开源框架的支持,这部分的成本已经大大降低。
- 计算:机器学习特别是深度学习需要巨大的计算能力,但是现在使用阿里云等云计算平台的计算成本大大减低,这块也逐渐不在成为瓶颈。
- 数据:这块和各个业务关联性比较大,也是各业务可以利用AI的能力来进行创新的关键,只要结合自己的业务和数据,利用AI能力就能带来很多不一样的突破。
最简单的例子
Tensorflow是google的开源的人工智能学习系统,下面是一个Tensorflow版本的Helloworld列子,让大家对其有个基本的了解。
要做什么?
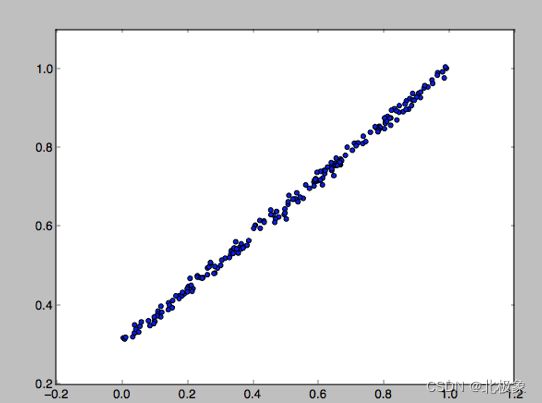
待预测的方程:y=0.7x+0.3+noise
模型:y=Wx+b
目标:通过给出足够的x,y,预测出W和b.
模拟数据准备:
import numpy as np
# 创建200个随机的值,为了模拟真实情况,增加noise y = x * 0.7 + 0.3
x_data = np.random.rand(200).astype(np.float32)
noise = np.random.normal(0,0.01,x_data.shape)
y_data = x_data * 0.7 + 0.3 + noise
数据图形化展示
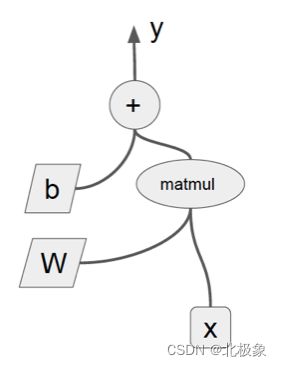
构建计算图形
import tensorflow as tf
x = tf.placeholder(shape=[None],
dtype=tf.float32,name=‘x')
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x + b
计算图形
最小化误差
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
计算图形如下:

MacOS 中配置运行环境
官方教程地址: https://www.tensorflow.org/install/install_mac#installing_with_virtualenv
一共有四种方式,根据官方推荐,我采用的是virtualenv
由于我的MBP没有NVIDIA CUDA GPU,因此这里我没有配GPU
安装
sudo easy_install pip
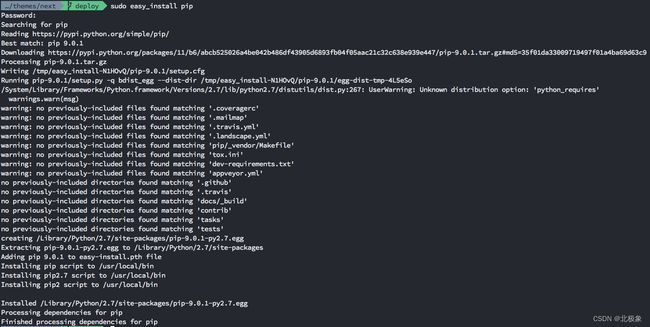
sudo pip install --upgrade virtualenv
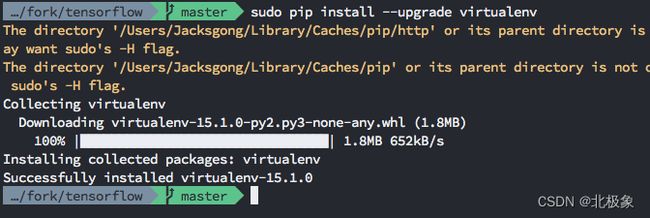
virtualenv --system-site-packages tensorflow

由于MacOS Sierra自带的Python是2.7.10版本,并且我的MBP没有支持GPU,因此执行:
pip install --upgrade tensorflow
如果是其他情况的请参照官方教程
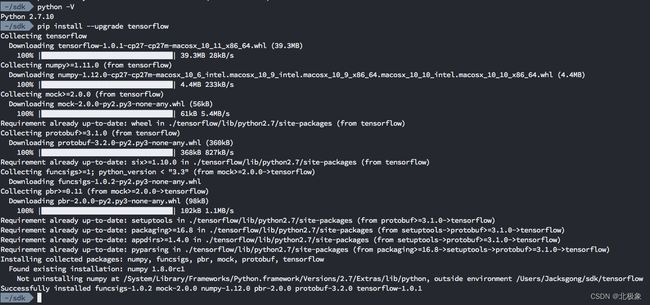
验证安装
官方地址: https://www.tensorflow.org/install/install_mac#ValidateYourInstallation

简单模型训练
该案例来自官方的入门案例: https://www.tensorflow.org/get_started/get_started
以tf引入tensorflow:
import tensorflow as tf
定义可训练模型变量W与b:
# 类型为tf.float32初始值为0.3的可训练模型变量W
W = tf.Variable([.3], tf.float32)
# 类型为tf.float32初始值为-0.3的可训练模型变量b
b = tf.Variable([-.3], tf.float32)
定义输出目标变量y:
y = tf.placeholder(tf.float32)
定义距离目标变量的损失值loss:
# 每个输出值与对应目标值差平方的和
loss = tf.reduce_sum(tf.square(linear_model - y))
定义优化器:
# 通过以精度0.01的梯度下降
optimizer = tf.train.GradientDescentOptimizer(0.01)
# 通过优化器,让其距离目标值逐渐减小
train = optimizer.minimize(loss)
准备训练用的数据:
# 输入变量x的值序列
x_train = [1,2,3,4]
# 需要能够对应输出的目标值序列
y_train = [0,-1,-2,-3]
开始训练:
# 初始化可训练变量
init = tf.global_variables_initializer()
# 创建一个session
sess = tf.Session()
# 复位训练模型
sess.run(init)
for i in range(1000):
# 喂训练数据
sess.run(train, {x:x_train, y:y_train})
输出训练结果:
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
# 最终结果当 W为-0.9999969、b为0.99999082,距离目标值(每个输出值与目标值差的平方和)为5.69997e-11
# 输出: W: [-0.9999969] b: [0.99999082] loss: 5.69997e-11
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))

该次模型训练的性能决定因素是: 优化器选择、精度选择、训练数据
通过高级的接口快速的实现上面的模型训练
import tensorflow as tf
# Numpy通常用于加载,维护与预处理数据
import numpy as np
# 需求队列(还有很多其他类型的column)
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# estimator是一个前端调用用于训练与评估的接口,这里有非常多预定义的类型,如Linear Regression, Logistic Regression, Linear Classification, Logistic Classification 以及各种各样的Neural Network Classifiers 与 Regressors. 这里我们用的是Linear Regression
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow有提供了许多工具方法来读写数据集,这里我们使用`numpy_input_fn`,我们不得不告诉方法一共有多少组(num_epochs),并且每组有多大(batch_size)
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# 我们可以通过传入训练所用的数据集调用1000次`fit`方法来一步步训练
estimator.fit(input_fn=input_fn, steps=1000)
# 评估目前模型训练的怎么样。实际运用中,我们需要一个独立的验证与测试数据集避免训练过渡(overfitting)
estimator.evaluate(input_fn=input_fn)
当然我们也可以通过tf.contrib.learn.Estimator这个高级接口,再使用低级接口来定制Linear Regressor算法模型(实际上内置的tf.contrib.learn.LinearRegressor也是继承自tf.contrib.learn.Estimator的)。当然我们不是通过继承,是通过提供model_fn来告诉他训练的步骤、如果评估等:
import numpy as np
import tensorflow as tf
# 定义需求队列(这里我们只需要一个featurex)
def model(features, labels, mode):
# 构建线性模型
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# 定义距离目标变量的距离
loss = tf.reduce_sum(tf.square(y - labels))
# 训练子图
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps用于将各参数串起来
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# 定义我们的训练用的数据集
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# 训练
estimator.fit(input_fn=input_fn, steps=1000)
# 评估训练模型
print(estimator.evaluate(input_fn=input_fn, steps=10))
识别数字图片的模型训练
该模型训练是通过MNIST数据,使用Softmax Regressio算法训练一个输入784像素的图片,识别出其对应数字的模型。
MNIST包含一个手写的数字,就好像:
这个案例是为了解答:
TensorFlow是怎么工作的?
机器学习的核心思想是什么?
你可以学习到:
MNIST数据、Softmax Regression算法
建立一个可以基于观察图片的每一个像素来识别数字的模型
通过模型浏览上千个案例来训练模型识别数字
通过测试数据,来验证模型的准确度
MNIST数据
数据是在Yann LeCun’s website: http://yann.lecun.com/exdb/mnist/
该数据分为三部分:
通过分离不同的数据,一部分用于训练,一部分用户测试,一部分用于学习,这样才能验证结果是训练的模型自己生成的。
mnist.train: 55_000个数据用于训练
mnist.test: 10_000个数据用于测试
minst.validation: 5_000个数据用于验证
每个数据有两部分:
手写数字的图片(x)(mnist.train.images、mnist.test.images): 28px * 28px = 784px
对应的标签(y)(mnist.train.labels、mnist.test.labels)
如数字1:
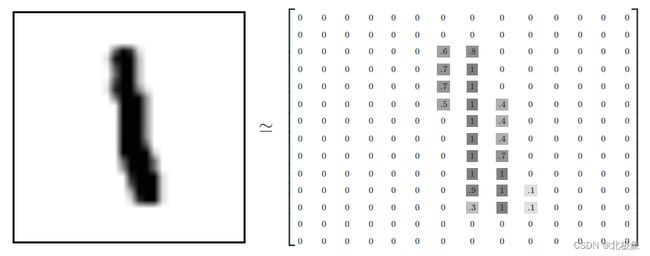
mnist.[train/test].images是一个tensor,由55_000个由784个点的二维数组组成,数组中的每个值代表每个像素点,像素点有色的根据浅到深是0到1,无色为0,每个数组所呈现的数字对应一个label,我们表示为[55000,784] 
minst.[train/test].labels也是一个tensor,由55_000个由10个值的一维数组组成,数组中有且仅有一个为1,其余为0,数组的index表示标签所代表的数字,如3表示为[0,0,0,1,0,0,0,0,0,0]],我们表示为[55000,10] tensorflow-mnist-
Softmax Regression算法
我们算法要尽量准确的通过图片(784个像素点)所呈现的,让结果中正确的数字所占的比例尽量的高,如给出的图片对应的数字是9,模型运算结果可能是: 80%的概率是9,5%概率是8,15%的概率是其他。
该算法使用场景: 从不同的事件中为一个对象分配可能性,因为该算法给我们一个0到1的列表,并且加起来等于1
大概步骤
总结输入的数据在各种分类中的证据(we add up the evidence of our input being in certain classes)
将证据转化为具体的可能性
做像素强度(intensities)的加权值,当图片的强度(intentsity)与某个分类不一致,其权重为负数,当有强有力的证据证明是在那个分类,其权重为正数
最终的模型权重
蓝色为正数权重,红色为负数
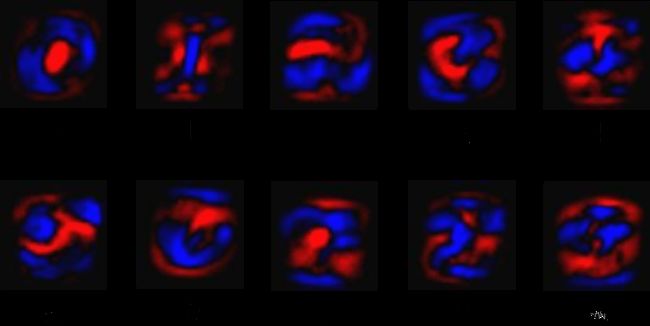
大致算法
下面算法图形中表示: 第i个类型、第j个像素、W为权重、x为输入的图片、b为偏移量
最终算法公式: y=softmax(Wx y = s o f t m a x ( W x + b)



实现
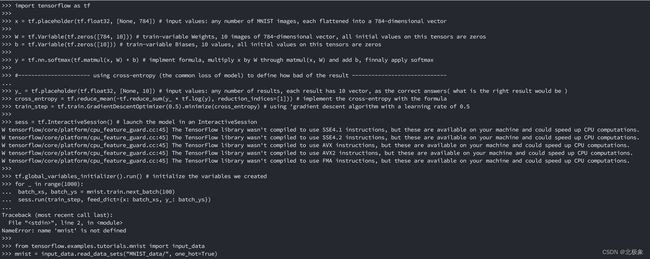
import tensorflow as tf
# 导入mnist数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 定义输入图片(tensor)变量x,其结构为任意个数的784个点的图片
x = tf.placeholder(tf.float32, [None, 784])
# 定义训练因素
W = tf.Variable(tf.zeros([784, 10])) # 定义权重W, 10张784个点的图片
b = tf.Variable(tf.zeros([10])) # 定义偏移量,0~9
# 导入公式 softmax(W * x + b)
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 使用cross-entropy(一个常见的loss模型)来定义结果有多差(定义一个标准,这样Tensorflow才能通过不断减少这个差值,来接近最终我们想要的模型)
y_ = tf.placeholder(tf.float32, [None, 10]) # 定义正确的
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) # 导入croos-entropy公式
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) # 使用"梯度减少"算法通过0.5的减少比率来学习
sess = tf.InteractiveSession() # 在InteractiveSession中启动模型
tf.global_variables_initializer().run() # 初始化我们创建的模型
# 每一步我们通过训练的集合生成100个随机的数据,通过train_step喂乳数据到图片x与对应的表示的数字y_
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 验证模型训练结果
# tf.argmax(y, 1)是对所有输入模型认为的最有可能的结果,tf.argmax(y_,1)实际上对所有输入最有可能的结果,然后通过tf.equal判断两个是否相等
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
# 由于correct_prediction计算出来的是一个Boolean数组,因此我们要通过tf.cast将其转为float,如[True, False, True, True]应该转为[1, 0, 1, 1]其中1占其中的0.75
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 最后输出通过模型计算出来的正确率,这个模型的正确率会在92%左右
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
这边的正确率是92%,是由于我们的模型非常简单,最好的模型能够达到99.7%的正确率,可以看看网上的不同模型的测试结果: http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html
结语
这是本人整理的入门资料,还很粗糙,后续继续完善。
参考链接
- MNIST For ML Beginners
- TensorFlow Api Doc
- Getting Started With TensorFlow