生成式对抗网络GAN模型搭建
生成式对抗网络GAN模型搭建
- 目录
-
- 一、理论部分
-
- 1、GAN基本原理介绍
- 2、对KL散度的理解
- 3、模块导入命令
- 二、编程实现
-
- 1、加载所需要的模块和库,设定展示图片函数以及其他对图像预处理函数
-
- 1)模块导入
- 2)设置图像属性
- 3)设置展示图片函数
- 2、数据下载、载入、装载及预览
-
- 1)类ChunkSampler
- 2)datasets.MNIST()
- 3)torch.utils.data.DataLoader()
- 4)获取其中一个数据进行预览
- 3、定义噪声函数
- 4、定义平铺函数和反平铺函数,用于对图像中数据的处理
- 5、Discriminator实现
-
- 1)包含的网络层
- 2)inplace=True
- 6、Generator实现
-
- 包含的网络层
- 7、定义损失函数和优化函数
- 8、计算损失值
- 9、定义训练函数
- 10、训练模型
- 三、训练结果
- 四、参考
目录
一、理论部分
1、GAN基本原理介绍
参见另一篇博文:生成式对抗网络(Generative Adversarial Nets,GAN)
2、对KL散度的理解
- 基本原理:KL散度
- 在GAN中为何需要使用KL散度?
假设我们现在知道样本的真实分布 p d a t a ( x ) p_{data}(x) pdata(x)和由生成器生成的数据的分布 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)。GAN的目标是得到一个能生成尽可能逼真的图片的生成器G,因此,我们希望 p d a t a ( x ) p_{data}(x) pdata(x)和 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)之间的差距越小越好。
那么,如何训练G,优化参数 θ \theta θ,使得 p d a t a ( x ) p_{data}(x) pdata(x)和 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)之间的差距缩小呢?
现在我们可以从训练集抽取一组真实图片来训练 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)分布中的参数 θ \theta θ使其能逼近于真实分布。因此,现在从 p d a t a ( x ) p_{data}(x) pdata(x)中抽取 m 个真实样本 { x 1 x^{1} x1, x 2 x^{2} x2, x 3 x^{3} x3, …, x m x^{m} xm}(注:其中符号[ ∧ \wedge ∧]代表上标,即 x 中的第 i 个样本。)对于每一个真实样本,我们可以计算 p g ( x i ; θ ) p_{g}(x^{i}; \theta) pg(xi;θ),即在由 θ \theta θ确定的生成分布中, x i x^{i} xi 样本所出现的概率。因此,我们就可以构建似然函数:
L = ∏ i = 1 m p g ( x i ; θ ) L = \prod^{m}_{i=1}p_{g}(x^{i}; \theta) L=i=1∏mpg(xi;θ)
其中[ ∏ \prod ∏]代表累乘, p g ( x i ; θ ) p_{g}(x^{i}; \theta) pg(xi;θ) 代表第 i 个样本在生成分布出现的概率。从该似然函数可知,我们抽取的 m 个真实样本在 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)分布中全部出现的概率值可以表达为 L。又因为若 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)分布和 p d a t a ( x ) p_{data}(x) pdata(x)分布相似,那么真实数据很可能就会出现在 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)分布中,因此 m 个样本都出现在 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ)分布中的概率就会十分大。
下面我们就可以最大化似然函数 L 而求得离真实分布最近的生成分布(即最优的参数 θ \theta θ):

这一个积分就是 KL 散度的积分形式,因此,如果我们需要求令生成分布 p g ( x ; θ ) p_{g}(x; \theta) pg(x;θ) 尽可能靠近真实分布 p d a t a ( x ) p_{data}(x) pdata(x)的参数 θ \theta θ,那么我们只需要求令 KL 散度最小的参数 θ \theta θ。若取得最优参数 θ \theta θ,那么生成器生成的图像将显得非常真实。
3、模块导入命令
- import 模块名
- import 模块名 as 新名字
- from 模块名 import 函数名
import 模块名和from 模块名 import 函数名的区别:
- 其中,使用import是将整个模块导入,而使用from则是将模块中某一个函数或名字导入,而不是整个模块;
- 使用import导入的模块,要使用模块中的函数则必须以模块名加“.”,然后是函数名的形式调用函数,而使用from导入模块中的某个函数,则可以直接使用函数名调用,不用在前面加上模块名称;
- 此外,使用from导入时,函数名处可以只用一个“*”来表示导入该模块中所有的代码,但要注意导入的模块中不要与此文件中的代码重复。
导入一个模块时,会创建新的命名空间,就可以使用命名空间来调用其中的代码;同时,还会在新创建的命名空间中执行模块中包含的代码,如果有输出也可以在控制台看到。
二、编程实现
1、加载所需要的模块和库,设定展示图片函数以及其他对图像预处理函数
1)模块导入
import torch
import torch.nn as nn
from torch.nn import init
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.utils.data import sampler
from torch.autograd import Variable
import torchvision
import torchvision.transforms as T
import torchvision.datasets as dset
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
%matplotlib inline
模块简介
- torch
包 torch 包含了多维张量的数据结构以及基于其上的多种数学操作。另外,它也提供了多种工具,其中一些可以更有效地对张量和任意类型进行序列化。 - torch.nn
PyTorch中的torch.nn包提供了很多与实现神经网络中的具体功能相关的类,这些类涵盖了深度神经网络模型在搭建和参数优化过程中的常用内容,比如神经网络中的卷积层、池化层、全连接层这类层次构造的方法、防止过拟合的参数归一化方法、Dropout方法,还有激活函数部分的线性激活函数、非线性激活函数相关方法,等等。 - torch.nn.init
提供各种初始化函数 - torch.optim
PyTorch的torch.optim包中提供了非常多的可实现参数自动优化的类,比如SGD、AdaGrad、RMSProp、Adam等。 - torch.utils.data
数据装载。 - torch.utils.data.DataLoader
创建数据集,有__getitem__(self, index)函数来根据索引序号获取图片和标签, 有__len__(self)函数来获取数据集的长度。 - torch.utils.data.sampler
创建一个采样器, class torch.utils.data.sampler.Sampler是所有的Sampler的基类,其中iter(self)函数来获取一个迭代器,对数据集中元素的索引进行迭代,len(self)方法返回迭代器中包含元素的长度。 - torch.autograd
torch.autograd包的主要功能是完成神经网络后向传播中的链式求导。实现自动梯度功能的过程大概为:先通过Tensor数据类型的变量在神经网络的前向传播过程中生成一张计算图,然后根据这个计算图和输出结果准确计算出每个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。 - torch.autograd.Variable
在实践中完成自动梯度需要用到Variable类对我们定义的数据类型变量进行封装,在封装后,计算图中的各个节点就是一个Variable对象,这样才能应用自动梯度的功能。 - torchvision
torchvision包的主要功能是实现数据的处理、导入和预览等,所以如果需要对计算机视觉相关问题进行处理,就可以借用在torchvision包中提供的大量的类来完成相应的工作。 - torchvision.transforms
torch.transforms中提供了丰富的类对载入的数据进行变换。 - torchvision.datasets
完成数据下载。 - numpy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。 - matplotlib
Matplotlib是一个Python 2D绘图库,可以生成各种硬拷贝格式和跨平台交互式环境的出版物质量数据。Matplotlib可用于Python脚本,Python和IPython shell,Jupyter笔记本,Web应用程序服务器和四个图形用户界面工具包。 - matplotlib.pyplot
matplotlib.pyplot是一个命令型函数集合,它可以让我们像使用MATLAB一样使用matplotlib。pyplot中的每一个函数都会对画布图像作出相应的改变,如创建画布、在画布中创建一个绘图区、在绘图区上画几条线、给图像添加文字说明等。 - matplotlib.gridspec
gridspec是用来给图片分格的 - %matplotlib inline
%matplotlib具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python控制台里面生成图像。
2)设置图像属性
pylot使用rc配置文件来自定义图形的各种默认属性,称之为rc配置或rc参数。通过rc参数可以修改默认的属性,包括窗体大小、每英寸的点数、线条宽度、颜色、样式、坐标轴、坐标和网络属性、文本、字体等。
- figure.figsize
设置图像显示大小 - image.interpolation
interpolation/resampling即插值,是一种图像处理方法,它可以为数码图像增加或减少像素的数目。
某些数码相机运用插值的方法创造出像素比传感器实际能产生像素多的图像,或创造数码变焦产生的图像。实际上,几乎所有的图像处理软件支持一种或以上插值方法。图像放大后锯齿现象的强弱直接反映了图像处理器插值运算的成熟程度
nearest—最近邻差值: 像素为正方形 - image.cmap
设置输出图片颜色
gray—使用灰度输出而不是彩色输出
# 设置输出图像的默认属性
plt.rcParams['figure.figsize'] = (10.0, 8.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
参考:
plt.rcParams[]
3)设置展示图片函数
设置图像大小为(sqrtn, sqrtn),将整张图划分为(sqrtn, sqrtn)个网格,网格间的空隙为(0.05, 0.05),每个网格显示一张图片,图片大小为(sqrtimg, sqrtimg)。
- np.reshape(x, new_shape, order=‘C’)
其中-1表示该维度的数值不确定,需要根据其他维度的数值求出。 - np.ceil()
向上取整。 - np.sqrt()
求平方根。
参考:使用GridSpec和其他功能自定义图布局
def show_images(images):
# 将图片地形状更改为(batch_size, D)
# 个人认为这句代码没有意义,因为输入的图片均是二维的,执行该命令之后图片的形状并未发生任何变化
# images = np.reshape(images, [images.shape[0], -1])
sqrtn = int(np.ceil(np.sqrt(images.shape[0])))
sqrtimg = int(np.ceil(np.sqrt(images.shape[1])))
fig = plt.figure(figsize=(sqrtn, sqrtn))
gs = gridspec.GridSpec(sqrtn, sqrtn)
gs.update(wspace=0.05, hspace=0.05)
for i, img in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
img = img.reshape([sqrtimg, sqrtimg])
plt.imshow(img)
plt.show()
2、数据下载、载入、装载及预览
从网上下载MNIST数据集,从训练集中取前50000张图像用作训练集,接下来的5000张图像用作验证集。
数据最终装载在以下两个变量中:
loader_train:训练集;
loader_val:验证集。
1)类ChunkSampler
类ChunkSampler继承自父类torch.utils.sampler.Sampler
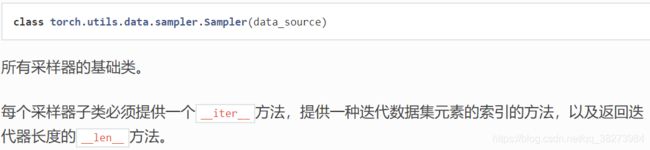
- 父类:class torch.utils.data.sampler.Sampler(data_source)
其中参数data_source (Dataset) – dataset to sample from ,即样本所在的数据集。 - 父类定义了两个函数:iter(self)和len(self)。
其中,iter(self)函数来获取一个迭代器,对数据集中元素的索引进行迭代;len(self)方法返回迭代器中包含元素的长度。
2)datasets.MNIST()
数据下载及载入
dset.MNIST(’./data/’, train=True, download=True,
transform=T.ToTensor())
3)torch.utils.data.DataLoader()

4)获取其中一个数据进行预览
imgs = loader_train.iter().next()[0].view(batch_size, 784).numpy().squeeze()
从训练集中取一个样本,将128张图片的像素存放起来,并从Tensor转换成一个128*784维的numpy矩阵,每一行存放着一张图片的所有像素值,将该矩阵传递给show_images()函数,展示图片。
- __iter__()
dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
也可以使用for inputs, labels in dataloaders进行可迭代对象的访问;
一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据。 - loader_train.__iter__().next()[0]
数据分为两个部分,一是图像像素,二是对应的标签,我们要输出图像,所以需要获取每张图像的像素,因此索引填“0”;若想查看对应的标签(即图片上显示的数值),索引填“1”即可。


- x = x.view()
x = x.view(height, weight) 这句话的出现就是为了将前面多维度的tensor展平成height*weight的tensor。

- numpy()
将数据类型从tensor转换为numpy。

- numpy.squeeze()
squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉。(不清楚为何要加上这个函数)
# 采样函数为自己定义的序列采样(即按顺序采样)
class ChunkSampler(sampler.Sampler):
"""
顺序采样:
参数:
1)num_samples: 采样个数;
2)start: 采样开始索引值。
"""
def __init__(self, num_samples, start=0):
self.num_samples = num_samples
self.start = start
def __iter__(self):
result = iter(range(self.start, self.start+self.num_samples))
return result
def __len__(self):
return self.num_samples
NUM_TRAIN = 50000 # 训练集数量
NUM_VAL = 5000 # 测试集数量
batch_size = 128 # batch的大小
mnist_train = dset.MNIST('./data/', train=True, download=True,
transform=T.ToTensor())
# 从0位置开始采样NUM_TRAIN个数
loader_train = DataLoader(mnist_train, batch_size=batch_size,
sampler=ChunkSampler(NUM_TRAIN, 0))
mnist_val = dset.MNIST('./data/', train=True, download=True,
transform=T.ToTensor())
# 从NUM_TRAIN位置开始采样NUM_VAL个数
loader_val = DataLoader(mnist_val, batch_size=batch_size,
sampler=ChunkSampler(NUM_VAL, NUM_TRAIN))
# squeeze(): 从数组的形状中删除单维度条目,即把shape中为1的维度去掉。个人认为squeeze()没有意义,因为图像的维度为(batch_size, 784)
# imgs = loader_train.__iter__().next()[0].view(batch_size, 784).numpy().squeeze()
imgs = loader_train.__iter__().next()[0].view(batch_size, 784).numpy()
show_images(imgs)
- 图像预览

3、定义噪声函数
这里产生一个从-1~1的均匀噪声函数,形状为[batch_size, noise_dim]
- torch.rand
用于生成数据类型为浮点型且维度指定的随机Tensor,和在NumPy中使用numpy.rand生成的随机数的方法类似,随机生成的浮点数据在0~1区间均匀分布。
def sample_noise(batch_size, noise_dim):
"""
生成均匀随机噪声,充当生成器的输入值
输入:
1)batch_size:batch尺寸;
2)noise_dim:生成噪声的维度。
输出:
维度为(batch_size, noise_dim)的张量,每个元素值介于-1和1之间
"""
temp = torch.rand(batch_size, noise_dim) + torch.rand(batch_size, noise_dim) * (-1)
return temp
4、定义平铺函数和反平铺函数,用于对图像中数据的处理
- 平铺:数据从[batch_size, channel, height, weight]平铺成[batch_size, channelheightweight];
- 反平铺:数据从[batch_size, channelheightweight]反平铺成[batch_size, channel, height, weight]。
class Flatten(nn.Module):
def forward(self, x):
# x.shape = [batch_size, channel, height, weight]
# 将shape中的数据依次赋给N, C, H, W
N, C, H, W = x.size()
# 将张量由[batch_size, channel, height, weight]平铺为
# [batch_size, channel*hight*weight],每一行分别代表一张图片的像素值
return x.view(N, -1)
class Unflatten(nn.Module):
# 将输入张量由[N, C*H*W]转变为[N, C, H, W]
def __init__(self, N=-1, C=128, H=7, W=7):
super(Unflatten, self).__init__()
self.N = N
self.C = C
self.H = H
self.W = W
def forward(self, x):
return x.view(self.N, self.C, self.H, self.W)
5、Discriminator实现
Discriminator输入为图片,输出为scalar。
1)包含的网络层
- 平铺,数据从[batch_size, channel, height, weight]展开成[batch_size, channelheightweight];
- 大小为 784到 256 的全连接层;
754 = 28 * 28(两个28分别是MNIST数据集中图像的height和weight) - alpha 值为0.01的 LeakyReLU层;
LeakyReLU,详参:神经网络中常用的激活函数 - 大小为 784 到 256 的全连接层;
- alpha 值为0.01的 LeakyReLU层;
- 大小为 256 到 1 的全连接层;
- D的输出应该为 [batch_size, 1] , 每个batch中包含正确分类。
2)inplace=True

def discriminator():
# 搭建判别器模型
model = nn.Sequential(
Flatten(),
nn.Linear(784, 256),
nn.LeakyReLU(0.01, inplace=True),
nn.Linear(256, 256),
nn.LeakyReLU(0.01, inplace=True),
nn.Linear(256, 1)
)
return model
6、Generator实现
Generator输入为noise,输出为图片。
包含的网络层
- 大小为 noise_dim 到 1024 的全连接层;
- ReLU;
- 大小为1024到 1024 的全连接层;
- ReLU;
- 大小为 1024到784 的全连接层;
- Tanh。
激活函数ReLU和Tanh,详参:神经网络中常用的激活函数
def generator(noise_dim=NOISE_DIM):
# 搭建生成器模型
model = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 784),
nn.Tanh()
)
return model
7、定义损失函数和优化函数
当计算交叉熵时,使用原生的函数会造成不稳定的求导,推荐使用 BCEWithLogitsLoss()。
- BCEWithLogitsLoss()
Pytorch 提供的交叉熵相关的函数之一,详参:Pytorch - Cross Entropy Loss(含官网说明);
举例说明:Pytorch详解BCELoss和BCEWithLogitsLoss
# 定义损失函数
Bce_loss = nn.BCEWithLogitsLoss()
# 定义优化函数
def get_optimizer(model):
"""
为模型构建优化函数,学习率为0.001,beta1=0.5,beta2=0.999
输入:
模型
输出:
模型的优化器
"""
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.5, 0.999))
return optimizer
8、计算损失值
分别计算G和D的损失函数,使用Adam优化:
- Generator:
l G = − 1 n ∑ i = 1 n [ l o g D ( G ( z ( i ) ) ) ] l_{G} = -\frac{1}{n}\sum_{i=1}^{n}[logD(G(z^{(i)}))] lG=−n1i=1∑n[logD(G(z(i)))] - Discriminator:
l D = − 1 n ∑ i = 1 n [ l o g ( D ( x ( i ) ) ) + l o g D ( 1 − G ( z ( i ) ) ) ] l_{D} = -\frac{1}{n}\sum_{i=1}^{n}[log(D(x^{(i)}))+logD(1-G(z^{(i)}))] lD=−n1i=1∑n[log(D(x(i)))+logD(1−G(z(i)))]
def discriminator_loss(logits_real, logits_fake):
"""
计算判别器的损失函数
输入:
1) logits_real:判别器对输入其中的真实图像的评分,维度为batch_size*1
2) logits_fake:判别器对输入其中的生成图像的评分,维度为batch_size*1
输出:
判别器的损失值
"""
loss = None
# Batch size
N = logits_real.size()
# 目标Label,全部设置为1意味着判别器需要做到的是将正确的全识别为正确,错误的全识别为错误
true_labels = Variable(torch.ones(N)).type(dtype)
# 识别正确的为正确-计算当输入真实图片时,D输出的scalar与正确标签1之间的差距,即D对于真实图片的损失函数
real_image_loss = Bce_loss(logits_real, true_labels)
# 识别错误的为错误-计算当输入生成图片时,D输出的scalar与正确标签0之间的差距,即D对于生成图片的损失函数
fake_image_loss = Bce_loss(logits_fake, 1-true_labels)
# 总的损失值由以上两部分组成
loss = real_image_loss + fake_image_loss
return loss
def generator_loss(logits_fake):
"""
计算生成器的损失值
输入:
logits_fake:判别器对于生成的图片的评分,维度为batch_size*1
输出:
生成器的损失值
"""
# Batch size
N = logits_fake.size()
# 由于生成器的目标是生成尽量真实的图片,试图骗过D,所以G的目标标签应当是1,即生成器的作用是将所有”假“的向真的(1)靠拢
true_labels = Variable(torch.ones(N)).type(dtype)
# 计算生成器损失
loss = Bce_loss(logits_fake, true_labels)
return loss
9、定义训练函数
def run_a_gan(D, G, D_solver, G_solver, show_every=250, batch_size=128,
noise_size=96, num_epochs=10):
"""
训练GAN
参数:
1)D,G:分别表示判别器和生成器模型;
2)D_solver,G_solver:D和G的优化函数;
3)batch_size:训练过程中使用的batch的大小;
4)noise_size:输入生成器的随机向量的维度;
5)num_epochs:训练的次数。
"""
iter_count = 1
for epoch in range(num_epochs):
for x, _ in loader_train:
if len(x) != batch_size:
continue
# step1: Training D
# 将D模型的参数梯度归零
D_solver.zero_grad()
# 转换参数类型,并在GPU可用的情况下完成数据迁移
real_data = Variable(x).type(dtype)
# 2*(real_data-0.5)???
logits_real = D(2*(real_data-0.5)).type(dtype)
# logits_real = D(real_data-0.5).type(dtype)
# 生成随机噪声
g_fake_seed = Variable(sample_noise(batch_size, noise_size)).type(dtype)
# 生成图片
fake_images = G(g_fake_seed).detach()
# 将生成的图片输入D,输出图片的scalar
logits_fake = D(fake_images.view(batch_size, 1, 28, 28))
# 计算D的损失值
d_total_error = discriminator_loss(logits_real, logits_fake)
"""
该函数的功能在于让模型根据计算图自动计算每个节点的梯度值并根据需求进行保留,有了这一步,
模型中的权重参数就可以直接使用在自动梯度过程中求得的梯度值,并结合学习速率来对现有的参数进行更新、优化
"""
d_total_error.backward()
# 使用计算得到的梯度值对各个节点的参数进行梯度更新
D_solver.step()
# Step2: Training G
# 将G模型的参数梯度归零
G_solver.zero_grad()
# 生成随机噪声
g_fake_seed = Variable(sample_noise(batch_size, noise_size)).type(dtype)
# 生成图片
fake_images = G(g_fake_seed)
# 将生成的图片输入D,输出图片的scalar
gen_logits_fake = D(fake_images.view(batch_size, 1, 28, 28))
# 计算G的损失值
g_error = generator_loss(gen_logits_fake)
# 参数更新、优化
g_error.backward()
G_solver.step()
# 每训练show_every次,输出一次样本图片
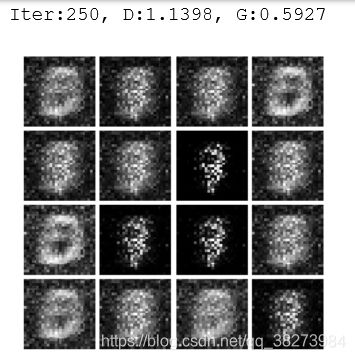
if(iter_count % show_every==0):
print('Iter:{}, D:{:.4f}, G:{:.4f}'.format(iter_count, d_total_error.data, g_error.data))
# 若GPU可用,则目前数据均为GPU张量,因为之后要完成从数组中取值的操作,所以需要先将数据转换为CPU张量,再转为numpy
if Use_gpu:
imgs_numpy = fake_images.data.cpu().numpy()
else:
imgs_numpy = fake_images.data.numpy()
images = imgs_numpy[0:16]
# 输出前16张图片
show_images(images)
print()
iter_count += 1
10、训练模型
# 判断GPU是否可用
Use_gpu = torch.cuda.is_available()
# 若可用,将数据迁移到GPU上,并将数据类型转换成FloatTensor
if Use_gpu:
dtype = torch.cuda.FloatTensor
# 若不可用,数据仍存放在CPU中,仅将数据类型转换成FloatTensor
else:
dtype = torch.FloatTensor
# 定义判别器,并完成数据类型转换
D = discriminator().type(dtype)
# 定义生成器,并完成数据类型转换
G = generator().type(dtype)
# 定义D和G的优化函数
D_solver = get_optimizer(D)
G_solver = get_optimizer(G)
# 开始模型训练
run_a_gan(D, G, D_solver, G_solver)
三、训练结果


四、参考
KL散度
生成式对抗网络(Generative Adversarial Nets,GAN)
机器之心GitHub项目:GAN完整理论推导与实现,Perfect!
PyTorch中文文档
PyTorch英文文档
pytorch实现自由的数据读取-torch.utils.data的学习
NumPy
NumPy 教程
Matplotlib中文文档
Matplotlib
Python数据可视化利器Matplotlib,绘图入门篇,Pyplot介绍
matplotlib: matplotlib.gridspec
Python关于%matplotlib inline
什么是GAN呢?
利用pytorch实现GAN(生成对抗网络)-MNIST图像-cs231n-assignment3
numpy.reshape
reshape(-1,1)什么意思 numpy.reshape
pytorch之dataloader深入剖析
什么是Tensor
PyTorch中网络里面的inplace=True字段的意思
Python中inplace=True的理解
神经网络中常用的激活函数
Pytorch - Cross Entropy Loss
Pytorch详解BCELoss和BCEWithLogitsLoss