双目立体匹配算法
双目视觉基础
单目成像
根据相机的小孔成像模型可知,2D图像上的一个像素点经过反投影只能确定三维空间中的一条射线,无法得到三维空间该点的具体深度值。

双目成像
在两个不同姿态的相机内外参已知的前提下,根据对P点拍摄两张不同角度的图像,根据两幅图像中的一对同名点,可以确定两条射线,两条射线的焦点就是P点在世界坐标系下的位置,称此过程为双目交汇,寻找同名点的过程为双目立体匹配。

三角化
三角化原理:
得到多对同名点的前提下,计算左右图像对的视差图,基于三角化的原理恢复物体的三维信息。

由对极几何模型可知
z = T f d d = x l − x r (1) z=\frac{Tf}{d}\;\;\;\;\;\;\;\;\;d=x^{l}-x^{r}\tag1 z=dTfd=xl−xr(1)
极线校正
在相机标定完成,得到左右相机的内外参数之后,需要搜索同名点,如果采用暴力查找的方式,左图中的某一像素点点要遍历右图所有像素点,算法效率低。为此,利用极线约束来提高同名点搜索的算法效率。


为了进一步提升算法效率,便于计算图像对的视差,使用仿射变换对左右视图进行极线校正,使得左右相机的x轴与基线平行,相机光轴与基线垂直,同时左右相机具有相同的焦距。

极线校正前后的图像对如下图所示:


立体匹配难点
1.不同视角下颜色、亮度差异和噪声
2.物体表面反光
3.物体表面为弱纹理表面
 4.物体为倾斜面
4.物体为倾斜面
5.透视变形
6.透明物体
7.物体表面遮挡和深度不连续
8.重复纹理区域
立体匹配算法
立体匹配算法一直是计算机视觉领域的核心问题之一,双目立体匹配一般基于朗伯面假设和局部表面光滑假设,其主要分为:
- 局部方法:局部方法搜索某个像素点的匹配点时,考虑像素点的局部信息,基于局部窗口内的像素进行计算匹配代价、代价聚合和视差计算,这样的方法容易受到噪声的影响,但算法效率高,一般可以进行cuda并行加速。
局部滤波(均值滤波(Box Filter)、双边滤波(Bilateral Filter)、Guided Filter)、最小生成树(Minimum Spanning Tree(MST))、全图滤波(Full Image Filter) - 全局方法:全局方法一般不包含代价聚合步骤,在计算视差图时,考虑全局所有像素,基于全图的像素建立全局能量函数,能量函数一般包含数据项和平滑项,通过优化算法来最小化全局能量函数得到最优的视差输出图,计算效率不高,难以并行运算,但鲁棒性较强。
图割(Graph Cut)、置信度传播(Belief Propagation) - 半全局方法
Semi-Global Matching(SGM) ,在全局算法的架构下,利用将全局能量函数最小化(二维)问题分解为多个方向优化(一维)的子问题,通过一维多路径聚合的结果来近似全局能量函数最小化的最优解。
匹配代价体计算
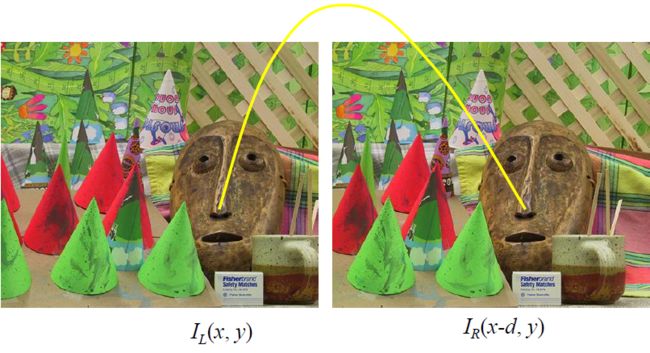
代价函数用于计算左、右图像两个像素之间的匹配代价(cost),cost越大,表示这两个点成为同名点的可能性越低,通过代价计算可以得到一个代价体。

常见的代价计算算法如下:
1.AD/BT
Absolute intensity difference C A D ( x , y , d ) = ∣ I L ( x , y ) − I R ( x − d , y ) ∣ (2) C_{AD}(x,y,d)=|I_{L}(x,y)-I_{R}(x-d, y)|\tag2 CAD(x,y,d)=∣IL(x,y)−IR(x−d,y)∣(2)
2.AD+Grandient ρ ( q , q ′ ) = ( 1 − α ) m i n ( ∣ ∣ I q − I q ′ ∣ ∣ , τ c o l ) + α m i n ( ∣ ∣ ▽ I q − ▽ I q ′ ∣ ∣ , τ g r a d ) (3) \rho(q, q^{'})=(1-\alpha)min(||I_{q}-I_{q^{'}}||, \tau_{col})+\alpha min(||\bigtriangledown I_{q}-\bigtriangledown I_{q^{'}}||, \tau_{grad})\tag3 ρ(q,q′)=(1−α)min(∣∣Iq−Iq′∣∣,τcol)+αmin(∣∣▽Iq−▽Iq′∣∣,τgrad)(3)
其中, τ c o l 、 τ g r a d \tau_{col}、\tau_{grad} τcol、τgrad为截断阈值, α \alpha α为权重,同时考虑两点间的像素差和梯度差。
3.Census

分别计算该点和八邻域之间的大小关系,得到的编码进行亦或,最后计算汉明距离得到Census代价。
4.NCC:normalized cross-correlation(归一化互相关)
C N C C ( x ′ , y ′ , d ) = ∑ ( x , y ) ∈ W ( x ′ , y ′ ) ( I L ( x , y ) − u ˉ L ) ( I R ( x − d , y ) − u ˉ R ) ∑ ( x , y ) ∈ W ( x ′ , y ′ ) ( I L ( x , y ) − u ˉ L ) 2 ∑ ( x , y ) ∈ W ( x ′ , y ′ ) ( I R ( x − d , y ) − u ˉ R ) 2 (4) C_{N C C}\left(x^{\prime}, y^{\prime}, d\right)=\frac{\sum \limits_{(x, y) \in W\left(x^{\prime}, y^{\prime}\right)}\left(I_{L}(x, y)-\bar{u}_{L}\right)\left(I_{R}(x-d, y)-\bar{u}_{R}\right)}{\sqrt{\sum \limits_{(x,y)\in W(x^{\prime}, y^{\prime})}\left(I_{L}(x, y)-\bar{u}_{L}\right)^{2}} \sqrt{\sum \limits_{(x, y) \in W\left(x^{\prime}, y^{\prime}\right)}\left(I_{R}(x-d, y)-\bar{u}_{R}\right)^{2}}} \tag4 CNCC(x′,y′,d)=(x,y)∈W(x′,y′)∑(IL(x,y)−uˉL)2(x,y)∈W(x′,y′)∑(IR(x−d,y)−uˉR)2(x,y)∈W(x′,y′)∑(IL(x,y)−uˉL)(IR(x−d,y)−uˉR)(4)
将两个窗口展开为向量,分别减去均值、归一化为模长为1的向量,再求内积,求出的代价值对图像的亮度的线性变化具有不变性,且表示两个向量夹角的余弦值。 5. AD+Census
5. AD+Census
对AD和Census加权得到代价值,结合AD对局部细节敏感和Census对光照鲁棒性的特点。
C A D ( p , d ) = ∑ i = R , G , B ∣ I i l e f t ( p ) − I i r i g h t ( p − ( d , 0 ) ) ∣ 3 C I ( p , d ) = 1 − exp ( − C A D ( p , d ) λ A D ) + 1 − exp ( − C census ( p , d ) λ Census ) C ( p , d ) = α ∗ C A D ( p , d ) + ( 1 − α ) C I ( p , d ) (5) \begin{array}{c} C_{A D}(\boldsymbol{p}, d)=\frac{\sum \limits_{i=R, G, B}\left|I_{i}^{l e f t}(\boldsymbol{p})-I_{i}^{r i g h t}(\boldsymbol{p}-(d, 0))\right|}{3} \\\;\\ C_{I}(\boldsymbol{p}, d)=1-\exp \left(-\frac{C_{A D}(\boldsymbol{p}, d)}{\lambda_{A D}}\right)+1-\exp \left(-\frac{C_{\text {census }}(\boldsymbol{p}, d)}{\lambda_{\text {Census }}}\right)\\\;\\C(\boldsymbol{p}, d) = \alpha*C_{A D}(\boldsymbol{p}, d)+(1-\alpha)C_{I}(\boldsymbol{p}, d) \end{array}\tag5 CAD(p,d)=3i=R,G,B∑∣Iileft(p)−Iiright(p−(d,0))∣CI(p,d)=1−exp(−λADCAD(p,d))+1−exp(−λCensus Ccensus (p,d))C(p,d)=α∗CAD(p,d)+(1−α)CI(p,d)(5)
6.CNN
使用CNN来计算左右视图的代价体
代价聚合
基于局部窗口的代价聚合方法通过将支撑区域内的代价求和或求平均进行代价聚合,支撑区域可以分为在固定视差平面的支撑区域(平行窗口)或在三维空间中的支撑域(倾斜窗口)。
常用的代价聚合方法
- Box Filtering(均值滤波)
假设:窗口内的每个点的视差值的权重相同,将窗口内的视差值总和除以N作为该中心点的视差值。
C d A ( p ) = 1 N ∑ q C d ( q ) (6) C_{d}^{A}(p)=\frac{1}{N}\sum_{q}C_{d}(q)\tag6 CdA(p)=N1q∑Cd(q)(6)
优点:计算速度快
缺点:不举报保留边缘的能力(窗口不能太大)
- Bilateral filter(双边滤波)
自适应权重:颜色+空间距离
C d A ( p ) = ∑ q e x p ( − ∣ p − q ∣ σ s ) e x p ( − ∣ I ( p ) − I ( q ) ∣ σ R ) C d ( q ) ∑ q e x p ( − ∣ p − q ∣ σ s ) e x p ( − ∣ I ( p ) − I ( q ) ∣ σ R ) (7) C_{d}^{A}(p) = \frac{\sum_{q}exp(-\frac{|p-q|}{\sigma s})exp(-\frac{|I(p)-I(q)|}{\sigma R})C_{d}(q)}{\sum_{q}exp(-\frac{|p-q|}{\sigma s})exp(-\frac{|I(p)-I(q)|}{\sigma R})}\tag7 CdA(p)=∑qexp(−σs∣p−q∣)exp(−σR∣I(p)−I(q)∣)∑qexp(−σs∣p−q∣)exp(−σR∣I(p)−I(q)∣)Cd(q)(7)
将分母的归一化项省略后得: C d A ( p ) = ∑ q e x p ( − ∣ p − q ∣ σ s ) e x p ( − ∣ I ( p ) − I ( q ) ∣ σ R ) C d ( q ) (8) C_{d}^{A}(p)=\sum_{q}exp(-\frac{|p-q|}{\sigma s})exp(-\frac{|I(p)-I(q)|}{\sigma R})C_{d}(q)\tag8 CdA(p)=q∑exp(−σs∣p−q∣)exp(−σR∣I(p)−I(q)∣)Cd(q)(8)
其中p为滑动窗口的中心点,q为邻域点, e x p ( − ∣ p − q ∣ σ s ) exp(-\frac{|p-q|}{\sigma s}) exp(−σs∣p−q∣)为空间距离项,表示距离中心点越远权重越小, e x p ( − ∣ I ( p ) − I ( q ) ∣ σ R ) exp(-\frac{|I(p)-I(q)|}{\sigma R}) exp(−σR∣I(p)−I(q)∣)为颜色距离项,表示邻域内颜色和中心点相似的权重大。
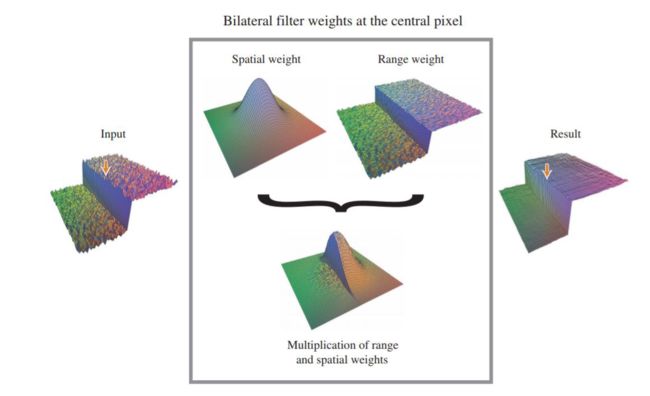
双边滤波具有保留边缘的特性,对噪声的鲁棒性高, 窗口可以开很大,匹配越稳定。
- Cross-based local stereo matching(基于十字叉支撑域的局部滤波)
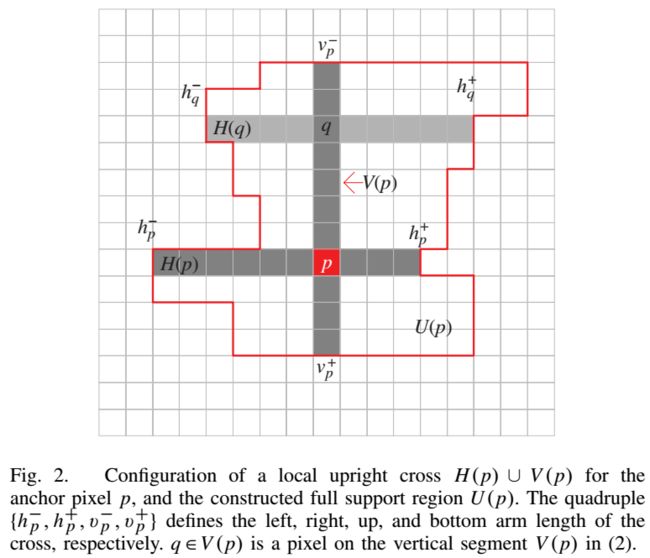
基于p点构建滑动窗口时,确定上下左右四点的十字骨架,由像素相似性来确定骨架长度,骨架满足尽可能长,且骨架内的像素和p点的像素差值不超过设定的阈值。同理,由p沿着竖向骨架遍历q点产生横臂,得到自适应窗口的支撑区域(support region)。

左右视图都计算自适应支撑区域,在用1D的积分图进行加速聚合运算。
(1)水平方向计算积分图HI
(2)基于HI计算每个像素点横臂的聚合代价
(3)计算纵向积分图VI
(4)对于某个十字臂区域用积分图VI计算
- Semi-Global Matching
能量函数:
E ( D ) = ∑ p ( C ( p , D p ) + ∑ q ∈ N p ( P 1 T [ ∣ D p − D q ∣ = 1 ] ) + ∑ q ∈ N p ( P 2 T [ ∣ D p − D q ∣ > 1 ] ) ) s . t . p 2 > p 1 (9) E(D) = \sum_{p}(C(p, D_{p})+\sum_{q\in N_{p}}(P_{1}T[|D_{p}-D_{q}|=1])+\sum_{q\in N_{p}}(P_{2}T[|D_{p}-D_{q}|>1])) \; \; \;\;\;\;\;\;\;\; s.t. p_{2}>p_{1} \tag9 E(D)=p∑(C(p,Dp)+q∈Np∑(P1T[∣Dp−Dq∣=1])+q∈Np∑(P2T[∣Dp−Dq∣>1]))s.t.p2>p1(9)
优化方式:动态规划(线扫描优化)
其中 ∑ p ( C ( p , D p ) \sum_{p}(C(p, D_{p}) ∑p(C(p,Dp)是数据项,是反应视差图对应的总体匹配的测度,具体的含义为当视差为D时,所有的像素的匹配代价的累加;
∑ q ∈ N p ( P 1 T [ ∣ D p − D q ∣ = 1 ] ) \sum_{q\in N_{p}}(P_{1}T[|D_{p}-D_{q}|=1]) ∑q∈Np(P1T[∣Dp−Dq∣=1])与 ∑ q ∈ N p ( P 2 T [ ∣ D p − D q ∣ > 1 ] ) ) \sum_{q\in N_{p}}(P_{2}T[|D_{p}-D_{q}|>1])) ∑q∈Np(P2T[∣Dp−Dq∣>1]))是平滑项,是为了让视差图满足某些条件假设的约束,如场景表面的连续性假设,平滑项会对相邻像素视差变化超过一定阈值的情况进行惩罚,如第一个表示 N p N_{p} Np邻域内的像素q, 如果p与q的像素值相差为1,给一个小惩罚为 P 1 P_{1} P1,较小的 P 1 P_{1} P1惩罚可以让算法能够适应视差较小的情况,如倾斜的曲面。
第二项表示,如果p与q点像素相差大于1,给予一个大惩罚 P 2 P_{2} P2, p 2 p_{2} p2惩罚往往是根据相邻像素的灰度差来动态调整,如下式所示: P 2 = p 2 ′ ∣ I b p − I b q ∣ s . t . P 2 > P 1 (10) P_{2}=\frac{p_{2}^{'}}{|I_{bp}-I_{bq}|} \;\;\;\;s.t.\;P_{2}>P_{1}\tag{10} P2=∣Ibp−Ibq∣p2′s.t.P2>P1(10)
P 2 ′ P^{'}_{2} P2′为 P 2 P_{2} P2的初始值,一般设置为远大于 P 1 P_{1} P1的数,公式的含义是如果像素和它的邻域像素亮度差很大,那么该像素很可能是位于视差非连续区域,则一定程度上允许其和邻域像素的视差差值超过1个像素,对于超过1个像素的惩罚力度就适当减小一点。
优化步骤:
(1)计算代价空间;
(2)代价聚合
方向r上p点的路径代价: L r ( p , d ) = C ( p , d ) + m i n [ L r ( p − r , d ) L r ( p − r , d − 1 ) + P 1 L r ( p − r , d + 1 ) + P 1 m i n i L r ( p − r , i ) + P 2 ] − min k L r ( p − r ) , k ) (11) L_{r}(p,d)=C(p, d)+min\begin{bmatrix}L_{r}(p-r,d)\\L_{r}(p-r, d-1)+P_{1}\\L_{r}(p-r, d+1)+P_{1}\\\mathop{min}\limits_{i}L_{r}(p-r, i)+P_{2}\end{bmatrix}-\min_{k}L_{r}(p-r),k)\tag{11} Lr(p,d)=C(p,d)+min⎣⎢⎢⎡Lr(p−r,d)Lr(p−r,d−1)+P1Lr(p−r,d+1)+P1iminLr(p−r,i)+P2⎦⎥⎥⎤−kminLr(p−r),k)(11)
其中r表示路径聚合方向上单位步长, p − r p-r p−r 表示路径上前一个像素。第一项为匹配代价,属于数据项;第二项是平滑项, C r ( p − r , d ) C_{r}(\mathrm{p}-\mathrm{r}, d) Cr(p−r,d) 表示如果路径上前一个像素的最优视差和当前像素的最优视差相同,则不加惩罚; C r ( p − r , d − 1 ) + P 1 和 C r ( p − r , d + 1 ) + P 1 C_{r}(\mathrm{p}-\mathrm{r}, d-1)+P_{1}和C_{r}(\mathrm{p}-\mathrm{r}, d+1)+P_{1} Cr(p−r,d−1)+P1和Cr(p−r,d+1)+P1 表示如果路径上前一个像素的最优视差和当前像素的最优视差相差1,则做 P 1 P_{1} P1惩罚、 min i C r ( p − r , i ) + P 2 \underset{i}{\min} C_{r}(\mathrm{p}-\mathrm{r}, i)+P_{2} iminCr(p−r,i)+P2表示表示如果路径上前一个像素的最优视差和当前像素的最优视差相差大于1,则做 P 2 P_{2} P2惩罚,取三者中的最小值;第三项是为了保证新的路径代价不超过数值上限。
将所有路径的代价直接求和得到总路径代价如下式所示: S ( p , d ) = ∑ r L r ( p , d ) (12) S(p,d)=\sum_{r}L_{r}(p,d)\tag{12} S(p,d)=r∑Lr(p,d)(12)
(3)WTA(赢者通吃)
 优化后的代价体,取d方向上的最小值作为最后的值。
优化后的代价体,取d方向上的最小值作为最后的值。
(4)视差后处理
视差计算
WTA(赢者通吃)
在局部算法中,代价计算和代价聚合是重点,视差计算是相对简单的,直接使用WTA算法逐个像素选择代价最小的视差值作为最优的视差值。如SGM算法使用了WTA来从聚合代价体S中得到视差图。
全局优化算法
全局算法一般没有代价聚合步骤,主要的工作都在视差计算步骤。许多全局算法都建立了全图能量函数,通过最小化全局能量函数来找到最优的视差图d,如下式所示:
E ( d ) = E data ( d ) + λ E smooth ( d ) (13) E(d)=E_{\text {data }}(d)+\lambda E_{\text {smooth }}(d)\tag{13} E(d)=Edata (d)+λEsmooth (d)(13)
数据项衡量左右视图的在视差图d下的整体匹配代价,也就是视差图d的准确性:
E d a t a ( d ) = ∑ ( x , y ) C ( x , y , d ( x , y ) ) (14) E_{d a t a}(d)=\sum_{(x, y)} C(x, y, d(x, y))\tag{14} Edata(d)=(x,y)∑C(x,y,d(x,y))(14)
平滑项是基于局部平滑性假设,让视差图更加平滑, 为了使优化的效率更高,平滑项通常仅限于测量相邻像素之间的差异, ρ \rho ρ是视差的单调递增函数:
E smooth ( d ) = ∑ ( x , y ) ρ ( d ( x , y ) − d ( x + 1 , y ) ) + ρ ( d ( x , y ) − d ( x , y + 1 ) ) (15) E_{\text {smooth }}(d)=\sum_{(x, y)} \rho(d(x, y)-d(x+1, y))+\rho(d(x, y)-d(x, y+1))\tag{15} Esmooth (d)=(x,y)∑ρ(d(x,y)−d(x+1,y))+ρ(d(x,y)−d(x,y+1))(15)
平滑项也可以用另外一种表达式表达:
ρ d ( d ( x , y ) − d ( x + 1 , y ) ) ⋅ ρ I ( ∥ I ( x , y ) − I ( x + 1 , y ) ∥ ) (16) \rho_{d}(d(x, y)-d(x+1, y)) \cdot \rho_{I}(\|I(x, y)-I(x+1, y)\|)\tag{16} ρd(d(x,y)−d(x+1,y))⋅ρI(∥I(x,y)−I(x+1,y)∥)(16)
同时考虑了相邻像素的视差差异和颜色差异,使得视差计算的结果更加鲁棒。
定义了全局能量函数之后,可以使用多种方法来优化能量函数,使得能量函数最小化,常用的优化方法包括:正则化、马尔可夫随机场、模拟退火算法、图割法等。
动态规划算法
全局能量函数最小化问题是个二维NP-hard问题,利用动态规划线扫描算法可以在多项式时间内找到全局的近似最优解,这些方法的原理是通过两个对应扫描线之间所有成对匹配代价矩阵来计算最小代价路径。算法详细信息如Semi Global Matching所示。
Disparity propagation(Patch Match)
基本思想:对于许多场景,很多区域可以近似用同一个平面来建模。
为了找到每个区域的平面参数,对每个像素赋予一个随机的平面参数(随机初始化)。希望每个区域至少有一个像素的初始平面是接近真实平面的。通过传播算法把正确的平面参数传递给这个区域的其他像素。
初始化:对于像素点 ( x 0 , y 0 ) (x_{0}, y_{0}) (x0,y0),在视差范围内随机选择一个深度 z 0 z_{0} z0;随机选择一个法向量 ( n x , n y , n z ) (n_{x}, n_{y}, n_{z}) (nx,ny,nz)。转化为平面的表达方式:
视差优化/后处理
1.左右一致性检测(LRC)
左视图的A点能匹配到右视图的B点,从B视图的B点也能匹配到左视图的A点
2.the minimum/ the second minimum cost(最小和次小有一定的差距)
每个像素计算最小代价和次最小代价的值,若两者相对差小于一定阈值,则被剔除。
3.Speckle Filter
为了移除噪声,对视差图进行连通区域提取(相邻像素的视差值小于阈值说明两个区域属于同一个区域),去除小的连通区域。

4.亚像素插值
在d处,与d的左右两个像素拟合二次曲线,求局部的亚像素最小值作为局部最优值,称之为二次曲线内插法。 
5. 中值滤波
6. 空洞填充
7. 加权中值滤波
基于深度学习的方法
- Disp-Net (A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation)-2016
- GC-Net (End-to-End Learning of Geometry and Context for Deep Stereo Regression)-2017
- PSM-NET (Pyramid Stereo Matching Network)-2018
- Stereo-Net (StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction)-2019
- GA-Net (GA-Net: Guided Aggregation Net for End-to-end Stereo Matching)-2019
- EdgeStereo (EdgeStereo:A Context Integrated Residual Pyramid Network for Stereo Matching)-2020