模型实战(4)之Win10下VS2019+opencv部署yolov5实现目标检测
模型实战(4)之Win10下VS2019+opencv部署yolov5实现目标检测
- 由于C++语言的运行优势,多数算法模型在实际应用时需要部署到C++环境下运行,以提高算法速度和稳定性
- 本文主要讲述WIn10下在VS工程中通过Opencv部署yolov5模型,步骤包括:
1.python环境下通过export.py导出.onnx模型 2.C++环境下通过opencv的DNN模块进行模型导入和调用
- 部署完成后的检测效果如下图所示(CPU下运行,无加速!)
win10下VS2019+opencv部署yolov5
1.导出onnx模型
模型导出函数:
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
try:
check_requirements(('onnx',))
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'output': {
0: 'batch',
1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'{prefix} export failure: {e}')
命令:
python export.py --weights ./weights/yolov5s.pt --opset 12 --include onnx
若导出提示,是因为onnx不支持silu:
ONNX: starting export with onnx 1.13.0...
ONNX: export failure: Exporting the operator silu to ONNX opset version 12 is not supported. Please open a bug to request ONNX export support for the missing operator.
解决方案如下:
找到环境中
python路径/Lib/site-packages/torch/nn/modules/activation.py:
重写394行
def forward(self, input: Tensor) -> Tensor:
# 原始
# return F.silu(input, inplace=self.inplace)
# 重写
return input * torch.sigmoid(input)
重新输入命令,导出成功!

2.VS下opencv部署
2.1 新建VS项目并配置属性
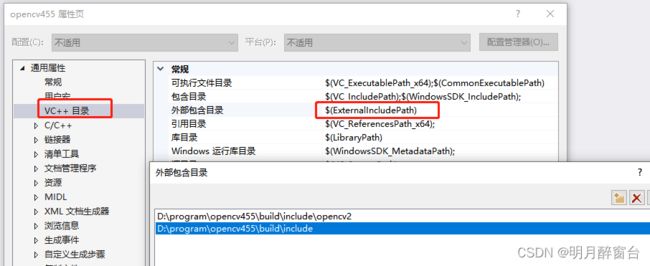


2.2 编译yolo.cpp
- 关于yolov5的部署相关代码可在yolov5-opencv下载
python代码:
git clone https://github.com/doleron/yolov5-opencv-cpp-python.git
cd yolov5-opencv-cpp-python
python python/yolo.py
如果想用cuda在GPU下测试:
git clone https://github.com/doleron/yolov5-opencv-cpp-python.git
cd yolov5-opencv-cpp-python
python python/yolo.py cuda
如果是在Linux下调试,则需要调试环境:
Any modern Linux OS (tested on Ubuntu 20.04)
OpenCV 4.5.4+
Python 3.7+ (only if you are intended to run the python program)
GCC 9.0+ (only if you are intended to run the C++ program)
IMPORTANT!!! Note that OpenCV versions prior to 4.5.4 will not work at all.
运行C++代码:
git clone https://github.com/doleron/yolov5-opencv-cpp-python.git
cd yolov5-opencv-cpp-python
g++ -O3 cpp/yolo.cpp -o yolo_example `pkg-config --cflags --libs opencv4`
./yolo_example
Or using CUDA if available:
git clone https://github.com/doleron/yolov5-opencv-cpp-python.git
cd yolov5-opencv-cpp-python
g++ -O3 cpp/yolo.cpp -o yolo_example `pkg-config --cflags --libs opencv4`
./yolo_example cuda
- 下边主要讲述在win10下VS工程中编译调试:
在下载好的文件夹中找出yolo.cpp,添加到已配置好项目属性的工程中,修改相应的路径运行即可得出结果
-
如下便是检测结果,帧率比较低是因为我在GTX1050,cpu下跑的,设置了
cuda = true,但还是自动选择了cpu调用,这是因为opencv中的DNN没有cuda,需要重新编译,即将cuda和opencv一起编译成新的库文件即可

-
yolo.cpp源码如下:
#include