Momentum Contrast for Unsupervised Visual Representation Learning----论文阅读2020 CVPR KaiMing
Momentum Contrast for Unsupervised Visual Representation Learning----论文阅读2020 CVPR KaiMing
- 参考博客
- 前文
- 1. Introduction
- 2. Related Work
-
- pretext task and loss functions
- loss functions ------ Contrastive losses
- pretext task
- Contrastive learning vs. pretext tasks.
- 3. Method
-
- 3.1. Contrastive Learning as Dictionary Look-up
- 3.2 Momentum Contrast
-
- Dictionary as a queue.
- Momentum update
- 伪代码
- 4. Experiments
参考博客
参考此篇文章做的笔记
此篇博客有:
MoCoV1 和 MoCoV2 的论文和代码
建议对着论文一同食用
这篇博客写的非常好,个人觉得
前文

个人理解:Unsupervised Visual Representation Learning 无监督视觉表征学习 就是学习特征图之间的相似性。
关于上面提到的 memory bank 在 2018CVPR NCE方法中博客提到,且为了此篇博客为了增加负样本,添加了噪声样本,并为m倍的 真实样本。
1. Introduction
这里建议先看下introduction,无监督在视觉领域并不占主导,这里的网络框架即字典构建,是从无监督在NLP中应用衍生过来的。
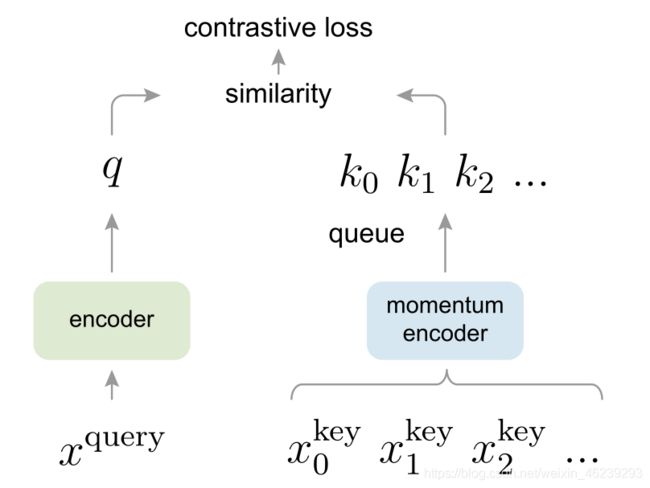
动量对比(MoCo)通过使用 对比损失 将编码查询 q 与编码关键字字典进行匹配来训练视觉表示编码器。字典键 {k0,k1,k2,…} 由一组数据样本动态定义。字典被构建为一个队列,当前的小批量入列,最早的小批量出列,将其与小批量大小分离。密钥由一个缓慢进展的编码器编码,由查询编码器的动量更新驱动。这种方法能够为学习视觉表示提供一个大且一致的字典。
大而一致性的字典意欲何为?
直观地说,较大的字典可以更好地采样底层的连续高维视觉空间,而字典中的键应该由相同或相似的编码器表示,以便它们与查询的比较是一致的。
个人理解:
大是针对视觉领域需要存储由采样而得到高维队列,一致性则就是用相同或类似的编码表示字典中其为表示队列的键。
A main purpose of unsupervised learning is to pre-train representations (i.e., features) that can be transferred to downstream tasks by fine-tuning.
无监督学习的一个主要目的是 预训练 (可以通过微调转移到下游任务的 )表示(即特征)。
括号不过定语而已,简单来说就是为了强化预训练中的特征层中特征图。
2. Related Work
通过论文了解一下即可
pretext task and loss functions
“借口”意味着正在解决的任务不是真正感兴趣的,而是为了学习良好的数据表示的真正目的而解决的。
损失函数通常可以独立于借口任务进行研究。
loss functions ------ Contrastive losses
这里提到几种loss
重点:Contrastive losses
对比损失[29]衡量样本对在表示空间中的相似性。在对比损失公式中,不是将输入与固定目标匹配,而是在训练过程中目标可以动态变化,并且可以根据网络计算的数据表示来定义[29]。
题外话:这里有提到NCE 噪声对比估计,可以了解下。
pretext task
简单来说通过借口任务形成伪标签
Contrastive learning vs. pretext tasks.
Various pretext tasks can be based on some form of contrastive loss functions.
3. Method
3.1. Contrastive Learning as Dictionary Look-up
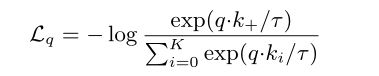
dot product 点积用来衡量匹配程度,针对图片就是相似度。
其中τ是的温度超参数。
总和超过一个正样本和K个负样本。直观地说,这种损失是基于(K+1)-way softmax classifier tries to classify q as k+ 的对数损失。对比损失函数也可以基于其他形式[29,59,61,36],例如基于保证金的损失和NCE损失的变体。
查询表示为 q = fq(xq),其中 fq 是编码器网络,xq 是查询样本(同样,k = fk(xk) )。
它们的实例化依赖于特定的借口任务。
输入 xq and xk 可以是图像。
网络 fq 和 fk 可以是相同的[29,59,63],部分共享的[46,36,2],或者不同的[56]。
3.2 Momentum Contrast
Dictionary as a queue.
Momentum update

这里m (0,1)是动量系数。只有参数 θq 通过反向传播更新。方程中的动量更新。(2)使θk比θq更平滑。结果,尽管队列中的密钥由不同的编码器编码(在不同的小批量中),但这些编码器之间的差异可以变小。在实验中,相对较大的动量(例如,m = 0.999,我们的默认值)比较小的值(例如,m = 0.9)工作得更好,这表明缓慢发展的密钥编码器是利用队列的核心。
θk 表示momentum encoder的参数, θq 表示query encoder的参数, m 表示更新速度, m 越大,更新速度越慢,对不同batch的样本进行编码的momentum encoder越一致。实验发现,m=0.999 时性能最好
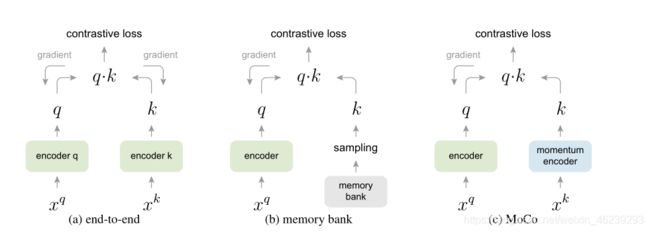
三种对比损失机制的概念比较(经验比较见图3和表3)。这里我们说明一对查询和键。这三种机制在如何维护密钥和如何更新密钥编码器方面有所不同。
(a):用于计算查询和密钥表示的编码器通过反向传播进行端到端更新(两个编码器可以不同)。
(b):关键表示从存储体中取样[61]。 就是上文 NCE 链接的论文
©: MoCo通过动量更新编码器对新密钥进行动态编码,并维护密钥队列(图中未显示)。
伪代码

如果一个查询和一个关键字来自同一个图像,我们将它们视为正对,否则视为负样本对。
我们在随机数据扩增下对同一图像取两个随机“视图”,形成正对。查询和密钥分别由它们的编码器 fq 和 fk 编码。编码器可以是任何卷积神经网络[39]。
算法1为这个借口任务提供了MoCo的伪代码。对于当前的小批量,我们对查询及其对应的关键字进行编码,这形成了正样本对。负样本样本来自队列。
技术细节。我们采用一个ResNet [33]作为编码器,它的最后一个全连接层(全局平均池化后)有一个固定维的输出(128-D [61])。该输出向量通过其L2范数进行归一化[61]。这是查询或键的表示。方程中的温度τ。(1)设为0.07 [61]。
数据增强设置如下:从随机调整大小的图像中截取224×224像素的裁剪,然后进行随机颜色抖动、随机水平翻转和随机灰度转换,所有这些都在PyTorch的torchvision包中提供。
洗牌BN。我们的编码器 fq 和 fk 都具有标准ResNet [33]中的批处理标准化(BN) [37]。在实验中,我们发现使用BN会阻止模型学习良好的表示。该模型似乎“欺骗”了借口任务,并很容易找到一个低损失的解决方案。这可能是因为样本之间的批内通信(由BN引起)泄漏了信息。我们通过洗牌解决这个问题。我们使用多个GPU进行训练,并为每个GPU独立地对样本执行BN(如通常实践中所做的)。对于键编码器 fk ,我们在分配给GPU之前,对当前小批量中的样本顺序进行洗牌(编码后再洗牌);查询编码器 fq 的小批量样本顺序没有改变。这确保了用于计算查询及其正关键字的批处理统计信息来自两个不同的子集。这有效地解决了作弊问题,并使培训受益于BN。我们在我们的方法及其端到端消融对应物中都使用了混洗BN(图2a)。它与内存库无关(图2b),内存库没有这个问题,因为正密钥来自过去不同的小批量。
4. Experiments
