Pytorch笔记3:深入浅出理解“张量”
文章目录
- 前言
- 一、常见的Tensor类型
-
- 1.标量(0D张量)
- 2.向量(1D张量)
- 3.矩阵(2D张量)
- 4.3D张量及高维张量
- 二、基本的张量操作
-
- 1.创建张量
- 2.张量数据的转换、初始化
- 3.规则索引及切片
- 4.无规则索引
- 三、张量的维度变换
-
- 1.Veiw函数调整形状
- 2.维度增加和减少
- 总结
前言
我们已经接触过Numpy中的数组,在拓宽一步,其实numpy中的多维数组(ndarray)就是一个张量数据。张量(Tensor)在深度学习领域非常重要,从谷歌的TensorFlow框架命名足以可见其地位。张量是一个数据容器,包括标量、向量等。
举个栗子,矩阵熟悉吧,它就就是一个二维张量,张量是矩阵在多维度的推广,张量维度通常也称为轴(axis),向量的维度为元素数,可以结合下面黄色标注理解。
一、常见的Tensor类型
张量数据可以在GPU上进行加速运算,python中的数据类型需要转换为Torch中的张量数据类型,具体的对应见下图如下图所示:
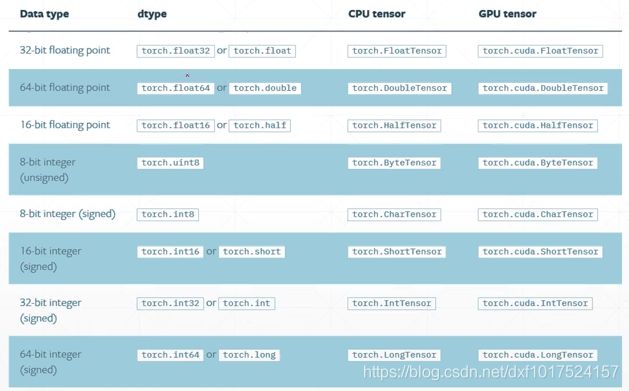
Torch中CPU的张量数据和GPU的张量数据表示,略有区别,GPU表示时多了.cuda.
1.标量(0D张量)
只含有一个数值类型的张量叫做标量(标量张量、零维张量、0D张量)。如Numpy中的一个数字,他的轴属性为0(ndim = 0)
代码如下:
import numpy as np
#为a赋值一个数值5
a = np.array(5)
print(a.ndim)
#其打印输出结果为 0
2.向量(1D张量)
带有方向的标量叫做向量(1D张量)。如Numpy中的一些列数字组成的数组,他的轴属性为1(ndim =1)
代码如下:
import numpy as np
#为a赋值一组数据[1,2,3,4,5]
a = np.array([1,2,3,4,5])
print(a.ndim,a.shape)
#其打印输出结果为 1 (5,)
这个向量有5 个元素,所以被称为5D 向量。注意是5D 向量不是5D 张量。听起来有点绕,耐心琢磨一下就好了。 5D 向量只有一个轴,沿着轴有5 个维度(即元素个数),而5D 张量有5 个轴(沿着每个轴可能有任意个维度(元素个数))。
3.矩阵(2D张量)
有多个向量组成的数组,就成为一个有行和列的矩阵(二维张量、2D张量)行和列即2个轴,所以矩阵轴属性为2(ndim =2)
代码如下:
import numpy as np
#为a赋值三个数组数据[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]
a = np.array([[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]])
print(a.ndim,a.shape)
#其打印输出结果为 2 (3, 5)
这个矩阵有3行5列,两个维度,即2D张量。其实判断是几维张量,查一下小括号里面左侧中括号个数,有几个就是几D张量,算是一个小技巧。
4.3D张量及高维张量
有多个矩阵组成的数组,就得到一个3D张量。即表示有几个二维矩阵,有个数,行,列即3个轴,所以矩阵轴属性为2(ndim =2)
代码如下:
import numpy as np
#为a赋值三个3行5列矩阵[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]]
a = np.array([[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]],
[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]],
[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]]])
print(a.ndim,a.shape)
#其打印输出结果为 3 (3, 3, 5)
将多个3D张量组成一个数组可以得到4D张量,以此类推得到5D或者更多。
我们常见维度的张量信息如下:
向量数据:采用2D张量,两个维度分别是(样本个数,数据)
时间序列或者序列数据:采用3D张量,维度分别是(样本个数,时间戳,数据)
图像数据:采用4D张量,维度分别是(样本个数,图像高度,图像宽度,颜色通道)或者(样本个数,颜色通道,图像高度,图像宽度)
视频数据:采用5D张量,维度分别是(样本个数,时间戳,图像高度,图像宽度,颜色通道)或者(样本个数,时间戳,颜色通道,图像高度,图像宽度)
二、基本的张量操作
1.创建张量
区分torch.FloatTensor()和torch.tensor()用法。
.tensor() 接收的是具体数据。
.FloatTensor一般接收是数据形状,也可接受具体数据(数组、矩阵等)。
代码如下:
import torch
# .tensor() 接收的是具体数据。
# .FloatTensor() 一般接收是数据形状,也可接受具体数据。
a = torch.tensor(1)
b = torch.FloatTensor(1)
print(a,a.ndim,a.shape)
print(b,b.ndim,b.shape)
print("****************************************")
a = torch.tensor([2,3])
b = torch.FloatTensor(2,3)
print(a,a.ndim,a.shape)
print(b,b.ndim,b.shape)
print("****************************************")
a = torch.tensor([2,3])
b = torch.FloatTensor([2,3])
print(a,a.ndim,a.shape)
print(b,b.ndim,b.shape)
print("****************************************")
在第一个代码块:.tensor接收具体数据1,所以打印输出的shape为空,因为为一个具体数字,0D张量。.FloatTensor接收的是数据形状,故打印输出的为1D张量(即向量,在深度学习领域以后都用张量来表达。)
在第二个代码块:.tensor接收数组[2,3],带有方向的标量(即数据)。所以输出维度为1,是1D张量。.FloatTensor接收的为数据形状,2,3 即2行3列,是一个矩阵,故打印输出维度为2,是2D张量。
在第三个代码块:.tensor接收数组[2,3],带有方向的标量(即数据)。所以输出维度为1,是1D张量。.FloatTensor接收的为具体数组数据,带[]表示接收数组[2,3],是一个数组,故打印输出维度为1,是1D张量。
输出结果:

torch.randn()函数创建一个2D张,2行3列,并且随机初始化数据为均值为0,方差为1,服从正态分布。
torch.rand() 随机生成0-1的均匀分布。
.type() 数据的类型默认设置为torch.FloatTensor。
.shape 显示向量的维度信息,可以用shape[]对维度索引,也可以使用 .size() ,size()进行维度索引。 当数据为标量时结果见下图。
isinstance(a,b) 可以判断是a否为b类型。
a =a.cuda() 可以将数据部署到GPU上。
代码如下:
import torch
#随机初始化一个2D张量2行3列
a = torch.randn(2,3)
#打印
print(a,a.type(),a.shape)
print(isinstance(a,torch.FloatTensor))
# a = a.cuda()
#数据a不是在部署在GPU上,会打印false
# print(isinstance(a,torch.cuda.FloatTensor))
b = torch.tensor(1.)
print(b,b.shape)
输出结果:

2.张量数据的转换、初始化
代码如下:
import torch
c = np.ones(3)
print(c,c.shape)
# 将numpy数据类型转换为张量类型
c = torch.from_numpy(c)
print(c,c.shape)
print("****************************************")
#.numpy将张量数据转换为nummpy数据
#随机生成3D张量,数据是0-1的均匀分布
a = torch.rand(1,2,3)
print(a,a.shape)
b = a.numpy()
print(b,b.shape)
print("****************************************")
#采用list方法将torch.size转换为列表形式
c = list(a.shape)
print(c)
输出结果:

再来区分一下 .tensor() , .Tensor(). 及 .FloatTensor() 区别,上面以及对tensor做了介绍,即接受的是数据需要[]括起来,单独一个数值不用。
.Tensor(). 与 .FloatTensor() 共同点都是接收数据形状,区别是==.Tensor().== 创建张量时根据默认设置创建张量类型,可以通过 .set_default_tensor_tpye() 自行设置如:torch.DoubleTensor或者 torch.FloatTensor (默认设置)。
代码如下:
import torch
#代表使用tensor中默认的类型,FloatTensor是创建时采用单精度类型
b = torch.Tensor(2,3,3)
print(b)
print(b.type(),b.shape)
c = torch.FloatTensor(2,3,3)
print(c)
print(c.type(),c.shape)
#可以通过.set_default_tensor_tpye()设置默认的Tensor类型
torch.set_default_tensor_type(torch.DoubleTensor)
d = torch.Tensor(2,3,3)
print(d)
print(d.type(),d.shape)
输出结果:

由结果可以看出,生成的张量数值需要重新赋值,以防后续出现Bug。
.randperm(a,b) 用于生成 a 到 b (不包含b)的随机索引。
代码如下:
#empty全部赋值为0
a = torch.empty(2,3)
#empty全部赋值为1
b = torch.ones(2,3)
#e对角线赋值为1
c = torch.eye(3,3)
#.full 全部赋值为指定的数据
d = torch.full([2,3],7)
#.arange(a,b,c)生成一个[a,b]的每次加c数据
e = torch.arange(0,10,3)
#生成随机索引[0,10)不包含10
f = torch.randperm(10)
print(a)
print(b)
print(c)
print(d)
print(e)
print(f)
输出结果:

3.规则索引及切片
代码如下:
#生成一个4D张量数据,可以理解为,批量大小为4,颜色通道为3,图像高度为28,图像宽度为28的图像数据
data = torch.rand(4,3,28,28)
# 4:0 axis
# 3:1 axis
# 28:2 axis
# 28:3 axis
# 0 维度的形状,取第一张图像3通道宽高数据
print(data[0].shape)
# 取第一张的第一个通道的宽高数据
print(data[0,0].shape)
#取图像的具体数据值
print(data[0,1,2,3])
输出结果:

切片
代码如下:
import torch
#生成一个4D张量数据,可以理解为,批量大小为4,颜色通道为3,图像高度为28,图像宽度为28的图像数据
data = torch.rand(4,3,28,28)
# 1:3 在数据0,1,2,3(3,28,28)中取1,2(3,28,28)
print(data[1:3].shape)
# :3 前面省略 代表从0开始取到2结束。在数据0,1,2,3(3,28,28)中取0,1,2(3,28,28)
print(data[:3].shape)
# 2: 冒号后面省略 代表从2开始到最后结束。在数据0,1,2,3(3,28,28)中取2,3,(3,28,28)
print(data[2:].shape)
# : 冒号前后都省略 代表取所有数据0,1,2,3(3,28,28)
print(data[:].shape)
#a:b:c两个同一个维度内两个冒号表示取从 a 到 b(不包含)隔c个数据(省略代表1可以理解吧)
print(data[:,:,0:28:2,:].shape)
#同理在相应的颜色通道等类似
print(data[1:2,0:3,3:25,:].shape)
输出结果:

4.无规则索引
在上述对数据所引中,或多或少时有连续的,如何离散的随心所欲的进行索引呢?请看大杀器 .index_select(a,b) a 表示要索引的数据所在维度,b表示要索引的条目(注意应为tensor类型不能直接使用列表)。
… 等于多个 : 代表取所有的维度。
代码如下:
import torch
data = torch.rand(4,3,28,28)
# 4:0 axis
# 3:1 axis
# 28:2 axis)
# 28:3 axis
#不规则数据索引,注意不能直接使用list,应转换为tensor数据类型
print(data.index_select(2,torch.tensor([23,25])).shape)
#...号等于多个:代表取所有维度
print(data[:,1,...].shape)
print(data[:,1,:,:].shape)
输出结果:
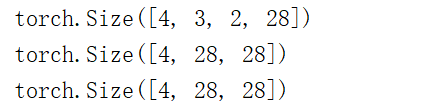
.ge(a) 将数据以a为界限的值标注出来,小于a为False,大于a为True。
代码如下:
import torch
a = torch.randn(3,4)
print(a)
b = a.ge(0.6)
print(b)
输出结果:

三、张量的维度变换
1.Veiw函数调整形状
.view() 类似于numpy中的reshape,view在张量数据中可以调整形状。但是要注意调整时数据的维度存储信息非常重要要有实际的意以,才能保证数据信息不被破坏,以图像数据为例。
代码如下:
import torch
# 生成一个4D张量数据,可以理解为数量大小为4,颜色通道为1,图像高度为28,图像宽度为28的图像数据
data = torch.rand(4,1,28,28)
# 4:0 axis
# 3:1 axis
# 28:2 axis)
# 28:3 axis
print(data.shape)
#调整图像,将颜色通道、宽度及高度合并,变成[图像数量,图像信息数据]的格式
a = data.view(4,1*28*28)
print(a.shape)
输出结果:

2.维度增加和减少
.squeeze() :压缩维度,即减少维度。
.unsqueeze() :增加维度。插入信息维度的范围正向为 0-dim,从左到右在维度前面插入;反向从-1到-dim-1:是从后面往前插入,为了方便理解,我们尽量采用前向插入方式。
代码如下:
# 生成一个4D张量数据,可以理解为,批量大小为4,颜色通道为3,图像高度为28,图像宽度为28的图像数据
data = torch.rand(4,3,28,28)
# 4:0 axis
# 3:1 axis
# 28:2 axis)
# 28:3 axis
print(data.shape)
# 正向在 0 1 2 3 维度之前插入 (从左往右)
print(data.unsqueeze(0).shape)
print(data.unsqueeze(1).shape)
print(data.unsqueeze(2).shape)
print(data.unsqueeze(3).shape)
print(data.unsqueeze(4).shape)
print("*******************************")
# 反向 从 -1 -2 -3 -4之后插入 (从右往左)
print(data.unsqueeze(-1).shape)
print(data.unsqueeze(-2).shape)
print(data.unsqueeze(-3).shape)
print(data.unsqueeze(-4).shape)
print(data.unsqueeze(-5).shape)
输出结果:

删减维度:squeez()
代码如下:
# 生成一个6D张量数据(0-5)
data = torch.rand(4,1,28,1,28,1)
# 4:0 axis
# 3:1 axis
# 28:2 axis
# 1:3 axis
# 28:4 axis
# 1:5 axis
print(data.shape)
# .squeeze()中不给指定维度时,会将dim=1 的维度都挤压
print(data.squeeze().shape)
print(data.squeeze(1).shape)
print(data.squeeze(3).shape)
print(data.squeeze(5).shape)
输出结果:

扩展维度:两种方式,一种是expend,Expand(广播方式)未增加数据;另一种是Repeat重复方式,增加了数据。
.expend() 使用的前提条件是要扩充的张量与扩充后的张量在维度要一致,并且只有dim=1,其他dim保持相同,才可以广播扩充。
代码如下:
# a 是4D张量,且在0轴,dim=1,1轴dim=3,2,3轴dim=1,故a可以扩充为(X,3,X,X)类型。
a = torch.rand(1,3,1,1)
print(a.shape)
a = a.expand(4,3,28,28)
print(a.shape)
# repeat 表示在原来的数据维度dim上重复指定的次数,即相乘
#(4,3,28,28)表示对a扩充(4x4=16,3x3=9,28x28=784,28x28=784,)
b = a.repeat(4,3,28,28)
print(b.shape)
输出结果:

转置:
.T 使用的前提条件是2D张量即(矩阵)。
.transpose(a,b) a,b是指要交换的维度,要注意数据的完整性不被破坏,详细例子见如下代码。
代码如下:
import torch
#2D张量矩阵转置
a = torch.rand(2,3)
print(a.shape)
print(a.T.shape)
#使用transpose时需要密切注意数据格式的改变
b = torch.rand(4,3,28,28)
# 4:0 axis
# 3:1 axis
# 28:2 axis)
# 28:3 axis
print(b.shape)
c = b.transpose(1,3)
print(c.shape)
#transpose会打散数据,使用.contiguous()将数据连续
d = c.contiguous()
d = d.view(4,3,28,28)
print(d.shape)
#判断二者数据是否相等,结果不相等,我们改变了数据格式,造成了数据污染
print(torch.all(torch.eq(b,d)))
#正确的转换如下,不能直接使用view,仍需转置:
e = d.view(4,28,28,3)
e = e.transpose(1,3)
print(torch.all(torch.eq(b,e)))
输出结果:

相比于transpose一次只能交换两个轴数据,.permute() 函数可以更方便的完成坐标轴的交换。
在4D张量图像数据的存储格式一般为:通道在前(数量,通道,宽度,高度)和 通道在后(数量,宽度,高度,通道)。
如果要将通道在前的格式转换为通道在后的格式,采用transpose需要两次,而采用permute只需要一次,但同样要注意恢复数据时保持数据不被污染。
代码如下:
import torch
a = torch.rand(4,3,28,32)
# (数量)4:0 axis
# (通道)3:1 axis
# (高度)28:2 axis)
# (宽度)32:3 axis
#采用transpose方法
print(a.shape)
b = a.transpose(1,3)
print(b.shape)
c = b.transpose(1,2)
print(c.shape)
#采用permute方法,将维度信息设置为0,2,3,1
d = a.permute(0,2,3,1)
print(d.shape)
print(torch.all(torch.eq(c,d)))
输出结果:

总结
张量的学习就先介绍到这里,有收获的老铁一键三连啊,您的点赞和认可是我的动力。