文献阅读(68)ACL2021-Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis
本文是对《Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis》一文的浅显翻译与理解,如有侵权即刻删除。
朋友们,我们在github创建了一个图学习笔记库,总结了相关文章的论文、代码和我个人的中文笔记,能够帮助大家更加便捷地找到对应论文,欢迎star~
Chinese-Reading-Notes-of-Graph-Learning
更多相关文章,请移步:
文献阅读总结:网络表示学习/图学习
文献阅读总结:自然语言处理
文章目录
- Title
- 总结
-
- 1 GCN模型
- 2 DualGCN
-
- 2.1 SynGCN
- 2.2 SemGCN
- 2.3 双向映射
- 3 损失函数
-
- 3.1 正交正则化
- 3.2 差异正则化
Title
《Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis》
——ACL2021
Author: Ruifan Li
总结
他人笔记:https://zhuanlan.zhihu.com/p/404343036
文章认为,当前情感分析方法往往采用句法依存树,但这种架构中会包含很多噪声,从而导致模型的效果受限。为解决这一问题,文章提出了DualGCN算法,同时使用句法GCN和语义GCN来对输入的评价语句建模,并加入了正交正则化和差异正则化来约束模型损失函数,其结构如下:

1 GCN模型
文章主要使用了句法模型Syntax-based GCN (SynGCN)和语义模型Semantic-based GCN (SemGCN)来对输入语句进行建模,在此介绍了GCN模型的基本结构:

即通过层层加权偏置聚合邻域信息,得到当前层的隐藏状态输出,并作为下一层的输入。
而输入到GCN的图(矩阵)结构数据,是通过句法依存树的结构来构建的邻接矩阵A,A_ij表示单词i和单词j之间的依存关系,为1表示依存,为0表示不依存。
2 DualGCN
文章提出的DualGCN是对输入的评价语句进行建模,对此,给出了句点对(s,a),其中a={a_i,…,a_m}为aspect(方面),s={w_1,…,w_n}为语句。在此利用Glove+BiLSTM或BERT对输入语句进行初始化,通过s在单词嵌入表中查询得到单词嵌入x={x_1,…,x_2},并输入到BiLSTM中得到隐藏向量H={h_1,…,h_n}。
2.1 SynGCN
该子模型是基于句法的GCN模型,通过句法编码的邻接矩阵,可以利用GCN的基本框架聚合得到句法表征H^syn ,其中对aspect节点,单独用h_a^syn 表示。
2.2 SemGCN
为学习与句法信息不同的隐藏信息,文章还构建了基于语义信息的模型,通过自注意力矩阵对初始化的隐藏向量H进行加权从而得到语义表征H^sem:

2.3 双向映射
得到上述两个GCN输出的表征后,文章采用双向映射的方法,将synGCN向量投影到SemGcn空间,SemGcn投影到synGcn空间,交叉引用,递归收敛:

而后,将两类表征进行拼接,得到最终的aspect表征向量r:
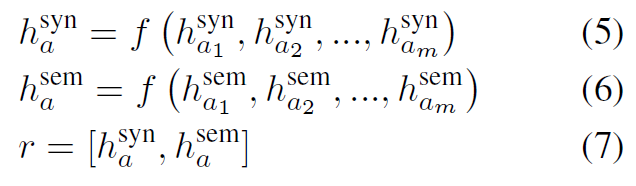
其中,f为平均池化函数。而后,可以利用softmax函数得到关于aspect的概率分布p:

3 损失函数
得到上述概率分布后,可以构建子损失函数为:
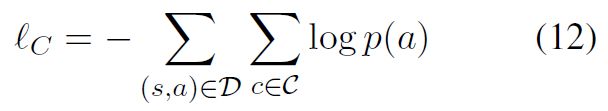
其中D包含所有句子-方面对,C是不同情感极性的集合。而最终的损失函数由多个部分构成:

其中第二项和第三项分别是正交正则化和差异正则化,第四项则是模型中出现的所有参数。
3.1 正交正则化
文章认为每个单词的相关项应当分布在语句中的不同区域,即注意力分数分布很少重叠。因此,该正则化约束所有单词的注意力分数向量之间为正交关系,即:

3.2 差异正则化
为了鼓励SynGCN和SemGCN学习到的信息表征不同,因此约束两者的邻接矩阵尽可能不同:
