基于深度学习的Image Inpainting (图像修复)
- 《Context Encoders: Feature Learning by Inpainting》
CVPR 2016
链接:https://arxiv.org/abs/1604.07379
Github代码:
基于torch:https://github.com/pathak22/context-encoder
基于pytorch:https://github.com/BoyuanJiang/context_encoder_pytorch
主要贡献:
提出了基于上下文像素预测驱动的无监督视觉特征学习算法,通过利用周围图像信息来推断损失部分的图像信息。其贡献点在于对于大范围图像损失,传统方法已经无法满足修复要求,作者首次提出了基于CNN和GAN的修补方法,首次较好地解决了大范围图像损失修补问题。
主要思路:(CNN+GAN)
通过结合Encoder-Decoder网络结构和GAN,利用L2损失(Reconstruction Loss)和对抗损失(Adversarial Loss)来修复图像。Encoder-Decoder结构用来学习全局图像特征和推断损失部分,GAN部分用来判断预测推断的图片和真实图片。不过一个主要的区别是,这里GAN只固定Generator,试图通过极大化Loss来训练更强的Discriminator。当GAN无法区分两者的区别时,则默认为网络模型参数已经达到最有状态。
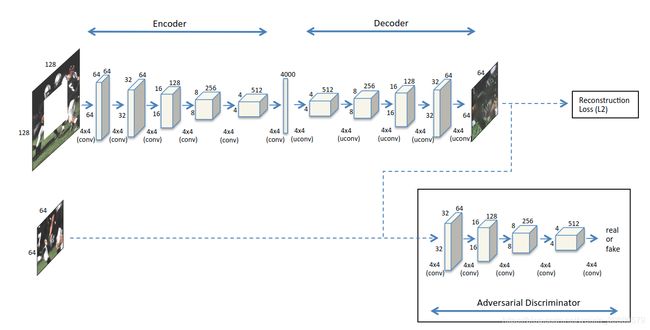
缺陷:
-
由于没有考虑填补区域与周围像素信息的一致性,得到的图片有时候缺少比较好的纹理细节,在填补的边缘能看到明显的痕迹。
-
当输入图片较大时难以训练Adversarial Loss,因此无法解决高分辨率的图片修复问题;
-
输入图片尺寸是固定的。
- 《High-Resolution Image Inpainting using Muti-Scale Neural Patch Synthesis》
CVPR2017
链接:https://arxiv.org/abs/1611.09969
Github代码:
基于torch:https://github.com/leehomyc/Faster-High-Res-Neural-Inpainting
主要贡献:
提出了结合图像内容与纹理的多尺度CNN匹配方法,不仅可以保留纹理结构,而且可以通过提取分类网络的中间层生成高频细节部分。以一定方式解决了高清图像补全问题。
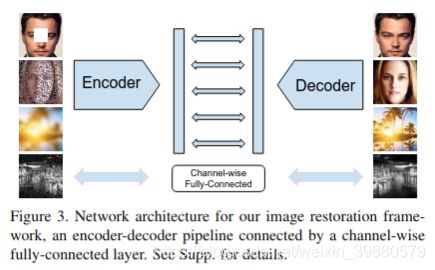
主要思路:(Encoder-Decoder + CNNMRF)
整体架构分为内容网络与结构网络。内容网络采用Encoder-Decoder 形式,其损失函数使用了L2损失和对抗损失的组合。结构网络采用训练好的VGG分类网络,原因在于其中间层的特征对于纹理变化表现出很强的不变性,因此有助于更加准确地补全缺失部分的内容。其损失部分分为三个部分,即Pixel-wise的欧式距离,基于已训练好纹理网络的feature layer的perceptual loss,和用于平滑的TV Loss。

缺陷:
纹理部分寻找patch时只是在该图片内寻找,没有利用数据集的数据。因此补全效果并没有特别理想。
参考
- 《On-Demand Learning for Deep Image Restoration》
ICCV 2017
链接:https://arxiv.org/abs/1612.01380
Github代码:
基于torch:https://github.com/rhgao/on-demand-learning
主要贡献:自动对原始图像修复难度进行分级,然后进行图像填补,像素插值,去模糊,去噪。
4. 《Globally and Locally Consistent Image Completion》
SIGGRAPH 2017
链接:http://iizuka.cs.tsukuba.ac.jp/projects/completion/en/
Github代码:
基于torch:https://github.com/satoshiiizuka/siggraph2017_inpaintinggithub.com
基于TF:https://github.com/shinseung428/GlobalLocalImageCompletion_TF
基于Pytorch:https://github.com/akmtn/pytorch-siggraph2017-inpainting
主要贡献:
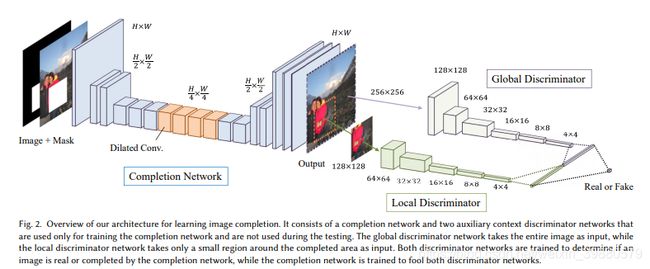
在Context Encoder中加入 Global context discriminator 和 Local context discriminator 使其从全局和局部两个角度判别生成效果的好坏。与此同时,可以修补任意不规则形状的缺损区域。
主要思路:
将需要进行填补的原始图片输入Encoder-Decoder网络,然后通过全局判别其和局部判别器从两个方面判别生成效果。全局判别器将完整图像作为输入,识别场景的全局一致性,而局部判别器仅在填充区域上观测,识别局部一致性。最后经过快速匹配方法[Telea 2004]后处理,从而将生成的边缘更加友好地融入全图。
[引]Alexandru Telea. 2004. An Image Inpainting Technique Based on the Fast Marching Method. Journal of Graphics Tools 9, 1 (2004), 23–34.
5. 《Image Inpainting for Irregular Holes Using Partial Convolutions》
ECCV 2018
链接:https://arxiv.org/abs/1804.07723
Github代码:
基于Pytorch:https://github.com/NVIDIA/partialconv
基于Pytorch:https://github.com/naoto0804/pytorch-inpainting-with-partial-conv
主要贡献:
可以解决任意形状缺损的图像修补,并且不需要额外的后期处理。