【第二章 数据预处理】袁博《数据挖掘:理论与算法》
目录
1 数据清洗
Outline
1、数据从哪里来?
2、为什么要做数据预处理?
3、缺失数据(Missing Data)
4、Outliers(离群点)
5、Anomaly(异常点)
2 异常值与重复数据检测
1、Local Outlier Factor(局部异常因子)
2、Duplicate Data(重复数据)
3 类型转换与采样
1、数据类型
2、类型转换
3、采样(Sampling)
4、Imbalanced Datasets(不平衡数据)
5、Over-Sampling(向上采样)
6、Boundary Sampling(边缘采样)
4 数据描述与可视化
1、标准化(Normalization)
2、数据描述(Description)
3、数据可视化(Visualization)
4、两个可视化软件
5 特征选择
1、如何评价属性好与不好?
2、熵(Entropy)
3、Feature Subset Search
6 主成分分析(PCA)
1、Feature Extraction(特征提取)
2、Principal Component Analysis(PCA,主成分分析)
7 线性判别分析(LDA)
1、LDA 和 PCA
2、LDA(Linear Discriminant Analysis,线性判别分析)
3、 可分性的度量
4、数学推导
5、LDA的例子
6、多分类问题的LDA
7、LDA的限制
8 阅读材料
1 数据清洗
数据往往是杂乱无章的,不能直接进行分析,需要预处理才能进行后续的工作
Outline
- 数据清洗(Data Cleansing)
- 数据类型转化(Data Transformation)
- 数据描述(Data Description)
- 特征选择(Feature Selection)
- 特征提取(Feature Extraction) PCA LDA
1、数据从哪里来?
金融数据(电子银行)、手机、GPS、传统的调查问卷、超市购物、健康管理(手环等)......
数据来源不同,格式也会有非常大的不同
2、为什么要做数据预处理?
真实的数据是非常 dirty 的,是数据挖掘中最大的挑战
需要借助领域知识,是数据挖掘工作的基础性工作
- 不完整(Incomplete):问你的职业是什么,你没填
- 不正确(Noisy):问你的工资是多少,你填了 -100
- 不一致(Inconsistent):问你的年龄(你填了42),后面又让你填生日(你填了01/09/1985),发现年龄和生日不匹配;
或:小张的个人信息中身份证号倒数第二位是单数,性别为女 - 冗余(Redundant):数据太多或属性太多,无法处理,或把真实有用的信息淹没了
- 其他:数据类型、数据集本身的不平衡
3、缺失数据(Missing Data)
(1)为什么会缺失?
- 设备坏了
- 未提供,如隐私数据
- Not Applicable(N/A) 不适用的
如:男女生做体检,体检项目是不同的,没填不代表缺失,而是不适用;
又如:学生小明在调查问卷中没有回答下述问题:“你去年的工资收入和前年相比是否有所增加?”
(2)缺失的类型
- 完全随机缺失:如有一阵风把试卷吹走了,100份只找回来60份,这40份的缺失是完全随机的,概率一样
- 缺失与另外的属性有关:如询问体重,缺失可能跟性别有关(女生可能不愿意回答)
- 缺失与自身取值有关:如询问收入,高收入人群或收入来源复杂的人可能不愿意填
(3)怎样处理缺失数据
具体问题具体分析
More art than science:与其说这个领域的工作是科学研究,不如说是艺术。因为没有严格的标准化流程,更多的是经验形成的结果
- 忽视或删除:缺失太多的情况下,不可以这样做
- 手工填:这个过程是十分麻烦(tedious)的,具体又可分为以下两种——
—重新采集
—领域知识(Domain Knowledge)推测:
如:问你住的房子是租的还是买的(没填),但是有另外一项问你是从什么时候开始住在这个地方的,有一个人填了18年,那么可以推测这个房子是他自己买的,而不是租的
又如:假设男生用1表示,女生用0表示,某人的性别未填,应根据其他信息(如身高、体重)推测 - 计算机自动填:固定值、均值或中位数、最可能的值
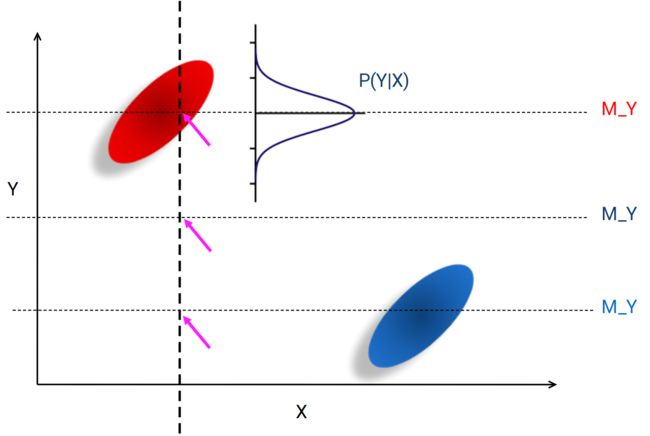
(4)例子
两堆数据(男人、女人),两个属性(身高X、体重Y)
现在来了一个新的样本,只有属性X(只知道身高,不知道体重),如何推测Y(体重)?
- 填所有样本的均值,但交叉处没有任何我们已有的样本 ×
- 填蓝色样本的均值 ×
- 填红色样本的均值交叉处的值,但再来一个相同X的未知样本,Y都一样,所以为了使结果更加逼真,加上一个高斯的概率分布,再采样,这样每次填的数都不一样
4、Outliers(离群点)
离群点(也可称之为噪点)对有些算法的影响是非常大的,如最小二乘、聚类
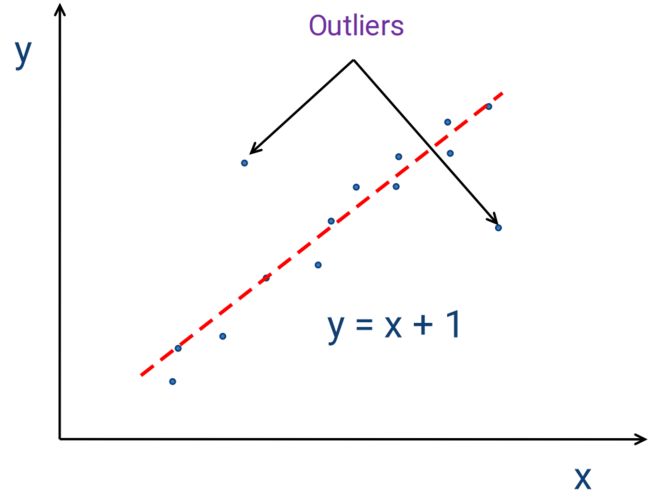 最小二乘
最小二乘 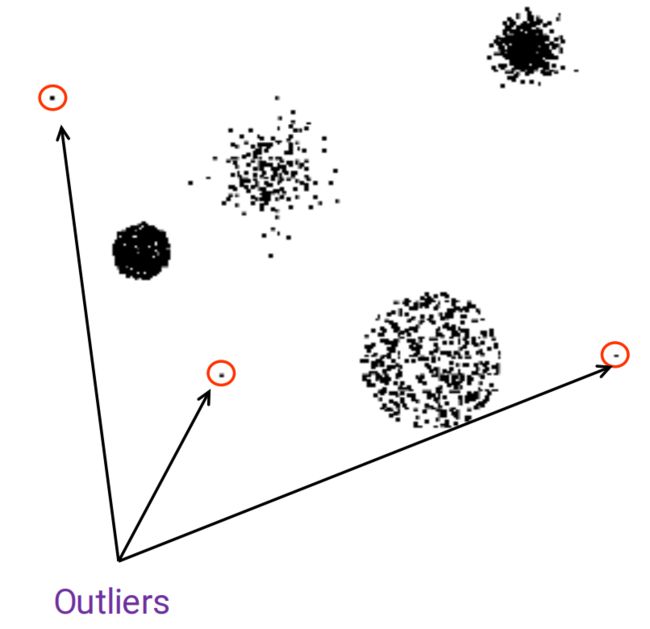 聚类
聚类
5、Anomaly(异常点)
与离群点(Outlier)是两个概念,不能混为一谈
2 异常值与重复数据检测
1、Local Outlier Factor(局部异常因子)
离群与否是一个相对的概念,关于离群点的判定,需要考虑相对距离因素
(1)引入distance
![]() :O点的k近邻,如k=3,找3个离O点最近的点,如果第3个点和第4个点是一样远的,那么都算在里面,即实际的点可能>3个。把第3个远的点画一个虚线的圆
:O点的k近邻,如k=3,找3个离O点最近的点,如果第3个点和第4个点是一样远的,那么都算在里面,即实际的点可能>3个。把第3个远的点画一个虚线的圆
![]() :A和B两点之间的欧氏距离
:A和B两点之间的欧氏距离

(2)引入lrd
分母:A有多少个近邻
分子:A到每个k近邻的距离之和
若一个点离它的近邻都非常近,则分子会非常小(其实是在算平均距离),整个又分之一,则:若一个点与它周围的点都特别地紧密,那么分之一后就会非常大,即 lrd(A) 特别大。即: lrd(A) 值越大,A与自己的近邻越紧密
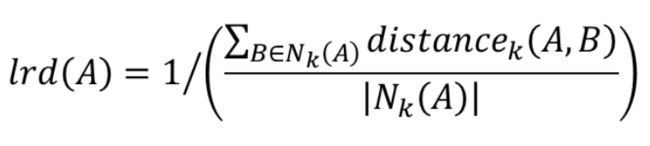 (3) 真正判断离群点的方式(引入LOF):
(3) 真正判断离群点的方式(引入LOF):
我算算我自己的 lrd 值(我离我自己的近邻有多远),再看看我的近邻到它们的近邻有多远,做一个比值。若 lrd(B) >> lrd(A),即我(A)的近邻(B)和它们的近邻的距离都特别近,而我(A)与我的近邻(B)又相对较远,则我(A)比较不合群
综上:LOF的值越大,是离群点的可能性越大
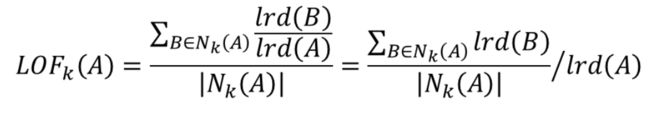
当给定一组样本时,对每一个样本都可以计算这样一个相对距离的概念
 数字代表 LOF 的值,值越大,圈越大
数字代表 LOF 的值,值越大,圈越大
2、Duplicate Data(重复数据)
(1)不同数据集中可能包含同一个人的信息,但格式可能不同,例如:
- 性别:有的公司用1/0表示,有的公司用M/F表示
- 名字:有的直接写名字,有的分 FirstName 和 LastName
- ID号:有的用CID(ClientID),有的用Cno(ClientNumber)
Q:CaseA:两个人名字不同,身份证号相同 CaseB:两个人同名同姓,身份证号不同
谁为重复数据的可能性大? A
分析:身份证号重复的概率极低(理论上为0),改名和重名重姓的情况在实际中并不罕见
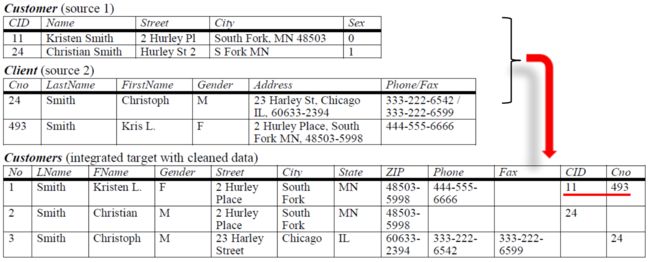 CID=11 和 Cno=493 其实表示的是一个人
CID=11 和 Cno=493 其实表示的是一个人
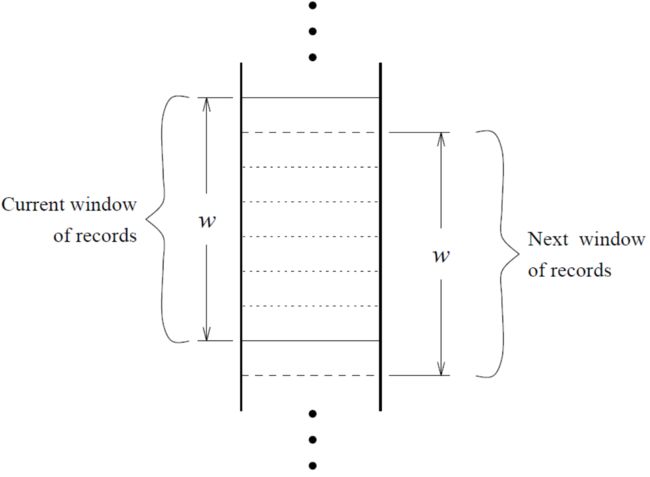
(2) 如何找出其中冗余或一样的信息? ——滑动窗口
- 窗口较小,容量为w(如100),每次向下移一位,新进来的只与前面的 w-1 进行比较(局部比较)
- 使用假设:真正高度疑似的样本是挨着的(重复记录的样本在数据库中必须是挨着的),这样才可以保证它们在一个滑动窗口当中,才可以比较
 生成键值 —> 排序 —> 比较
生成键值 —> 排序 —> 比较
对数据库中的每一条记录生成一个键值,根据key去排序
基本原理:如果两个样本非常可能是一样的,那么生成的key要一样或差一点点,这样排完序才能保证这些记录都放在一个滑动窗口里
key如何生成? ——不容易记错或听错的位数作为key
Q:在记录手机号码时,相对而言前 3 位不容易记错。
例子:

先看两个人的 last name(姓),两个人的姓如果一模一样,两个人的 first name(名)差一点点,他们的地址又一样,则认为这两个人对应着同一个人
为什么先比较姓? ——这与文化背景有关。外国人中,姓更容易区分,名反而没有多少区分度
Q:在记录英语国家人名时,姓容易写错
分析:姓氏种类繁多,容易因为不熟悉写错
3 类型转换与采样
- 把缺失值填充、重复值剔除之后的数据是 error-free 的,但还是不能直接使用,还需要进行一些类型转换或采样的工作
- 在实际数据分析工作中,数据类型转换和数据自身的错误是面临的主要挑战之一
1、数据类型
- 连续型(Continuous):数值,如身高、体重
- 离散型(Discrete):数值,如人数
- 序数型(Ordinal):有前后顺序,需要转换成数值,如优良中差、按ABCD打分的考试成绩数据
- 标称型(Nominal):最麻烦的一种,如职业—老师、工人、销售员等等,颜色—RGB等等,少数民族—56个民族
- 文本型(String):非结构化,字符串,如朋友圈、日志等
2、类型转换
(1)RGB三种颜色,如何编码?
若编码为012,暗含了绿色与红色的距离<蓝色与红色的距离(在空间中施加了距离度量),这是没有道理的
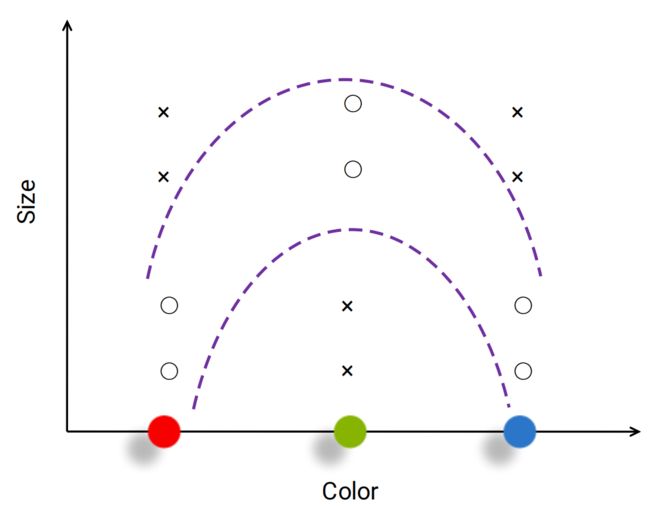
(2)水果有三种颜色、不同的大小,○和x分别代表一种水果,现在要把二者分开
分界面为两条类似抛物线的曲线
 红=0,绿=1,蓝=2
红=0,绿=1,蓝=2
数据不动,只调整编码方式(绿色和蓝色对调一下),此时分界面为两条直线,简化了问题
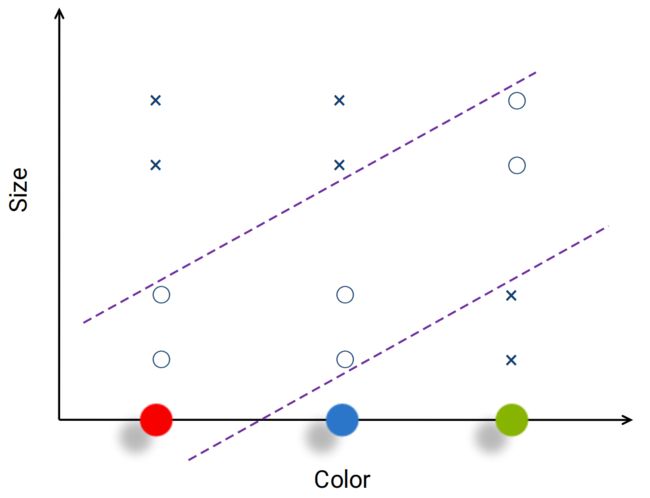 红=0,蓝=1,绿=2
红=0,蓝=1,绿=2
这个例子说明:不同的编码会造成问题结构的不同,或数据在空间的分布不同,可能使问题简化或复杂
(3)RGB到底如何编码?

四种颜色,拆成四位,任何两种颜色的小球之间的距离都是一样的(等间距空间)
即拆成维度更高的表达形式,显然只适用于少量的颜色,否则维度无法处理
(4)在对标称型数据(如颜色、职业等)进行编码时:
- 类别较少时,可考虑采用扩维法
- 不同编码可能会影响数据的空间分布
3、采样(Sampling)
- 采样的目的是降低时间复杂度
- 大数据中的采样是因为数据太多,无法处理;统计学中的采样是因为数据的采集过程十分昂贵
- 采样还有一个作用是调整类的比例,对原始数据集进行调整,使比例接近1:1,再进行分类算法
- 在大数据分析中,利用采样技术可以:减少需要处理的数据量,有助于处理不平衡数据,提高数据的稳定性
为了减少数据,还有很多种方法,如 Aggregation(根据需要将数据进行聚集,不需要知道最底层的数据,可以大大减少数据量,数据也可以更加平稳),举 2 个例子:
- 每打一个电话,都会记录几分几秒开始,到几分几秒结束,打给谁。但是有时不需要记录如此详尽的信息,只需知道这个客户在某一天打了多少个长途电话,多少个市内电话;或只需知道每个月打了多少话费,或变化规律就行了
- 记录每一个分店的营业额 —> 记录地区(如华南区)的营业额
4、Imbalanced Datasets(不平衡数据)
100个人中只有1个人生病,分类器:无论谁来都判定为健康,准确率为99%,但它是无意义的
- 红和蓝代表两类问题(一维分类),分界面为一根线,线的右手边(RHS)判定为蓝色,左手边(LHS)判定为红色
- 对于A分类器来说,判定所有的样本为蓝色,准确率为95%;B分类器右边全分对,但左边有10%的蓝色被误判了,所以准确率为90%
- 准确率来看A好,但实际效果好的是B
对于极度不平衡的二分类数据集,应特别注意少数类样本的准确率
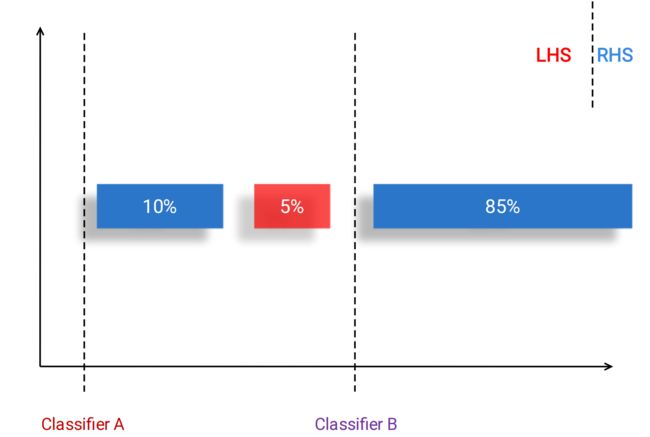
整体准确率的概念不适用于不平衡数据集(两类数据集差别特别大),应采用新的度量模式:
(1)G-mean:取值0~1之间,要单独看正类准确率和负类准确率,但要G-mean值高,必须在两类上都分的对才可以
(2)F-measure:在信息检索中常用
- Precision(准确率):搜关键词,返回100篇文章,有多少是真正需要的
- Recall(召回率):事实上有多少篇文章与关键词相关,但只返回了多少篇

5、Over-Sampling(向上采样)
数据集中红色远远多于蓝色,怎么办?
- 蓝色多采样一些,类似于克隆(多复制),但不是完全克隆(无意义)
- 一个蓝色点(样本数较少的点),找它的近邻点,在区域中随机生成,类似插值的方法
SMOTE的工作原理是:对少数类样本通过插值进行上采样

6、Boundary Sampling(边缘采样)
只有最外面这层点(边缘点)最有价值,如何找出边缘点?
- 密度:边缘点一面比较密,一面比较稀
- 法向量
4 数据描述与可视化
1、标准化(Normalization)
在计算机中,数据本身是无单位的,如身高可以是1.7、170、1700等,需要进行标准化
几种标准化的操作:
(1)把原始数据映射到 [0,1] 区间
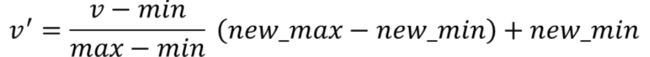 适用于有明确上下界的数据
适用于有明确上下界的数据
如:做了一个收入的调研,人群中最低收入12000,最高收入98000,这是一个区间。想把这个区间当中所有的收入都映射到 0和1 之间,如何映射?

(2)Z-score:计算点偏离均值(μ)多少个 standard deviation(标准方差σ)
高斯分布偏离 3个 standard deviation 以外的点就已经很少了,可以看做离群点
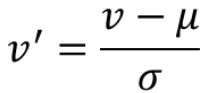
数据无明确上下界,可以无限延伸,如高斯

2、数据描述(Description)
(1)一般性描述(统计信息):
- 均值(Mean):容易受极端值影响
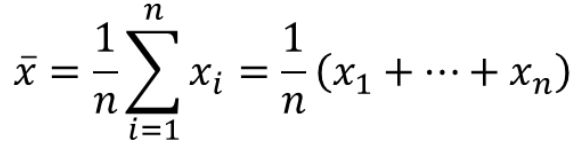
Q:很多人感觉到自己的收入与官方公布的平均收入相去甚远,最有可能的解释是:个体收入分布极度不均衡
分析:人群的收入分布通常具有长尾特点,因此其均值容易被少数高收入者拉高,显著偏离样本的中位数,不具有代表性 - 中位数(Median)
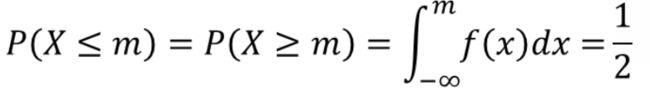
- 众数(Mode):频率最高的数,有可能与均值或中位数重合,如正态分布时三者重合

- 方差(Variance)
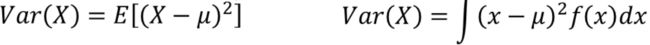
(2)相关性:
皮尔逊相关系数
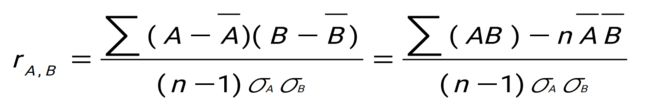
- r>0:A和B正相关,如个子越高,体重越高
- r<0:A和B负相关,如随着年龄越大,身体状况越来越差
- r=0:A和B之间没有线性相关,即线性不相关,不是A和B不相关
皮尔逊卡方检验
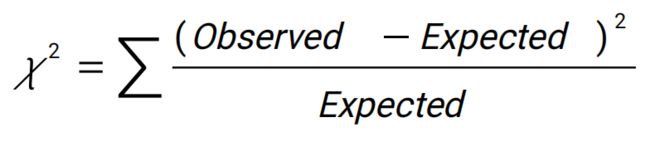
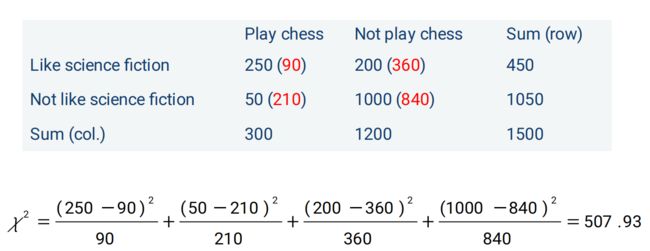
例子:一个人喜不喜欢下国际象棋,与他喜不喜欢科技小说有无关系
- 找了1500个人,其中300个人下象棋,1200个人不下象棋,其中250个人又下象棋又喜欢科幻小说(其他三个数以此类推)
- 如果下象棋与喜欢科幻小说没有关系,下象棋的人跟不下象棋的人是1:4,那在喜欢科技小说那一行的两个数,也应该是1:4,一共是450,则分别为90和360
- 即假设不相关是红色的数据(Expected),但实际是蓝色的数据(Observed)
- 求出的卡方值很大,结果判断两者不是独立的,是有相关性的
3、数据可视化(Visualization)
可视化不仅可以很好地展示结果,也可以帮助人们思考数据中蕴含的模式、要做怎样的数据挖掘。数据可视化工作贯穿数据挖掘工作全过程,从最初数据简单的分析处理的可视化,到数据挖掘过程的可视化,到结果的可视化,每一步都发挥着重要的作用
(1)一维:MATLAB 或 Excel
- 圆饼图:中国收入的不同档次有多少人(百分比)
- 曲线图:股票价格随着时间波动
- 直方图:人的平均寿命或身高的分布

(2)二维:MATLAB
汽车的排量和汽车0-60英里的加速时间之间的关系
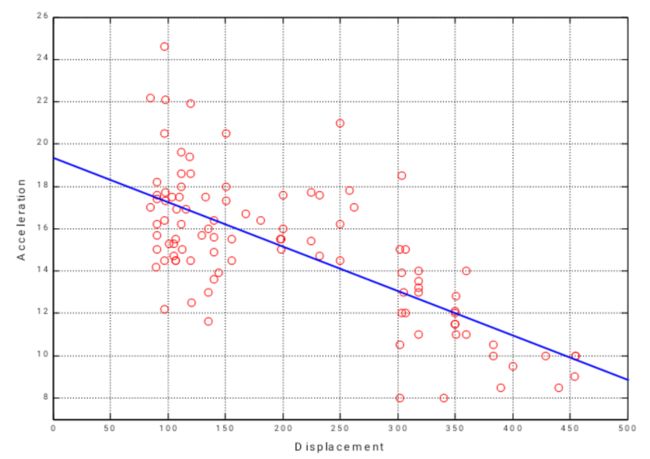 一个○代表一辆车,作回归
一个○代表一辆车,作回归
(3)三维:MATLAB
z = f(x,y)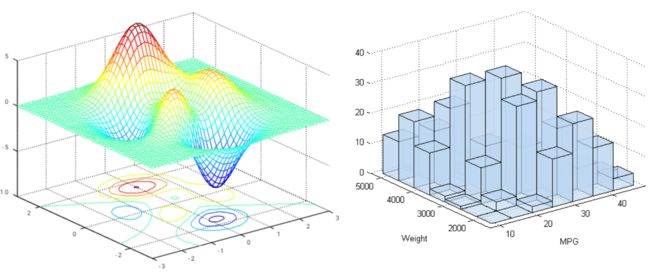
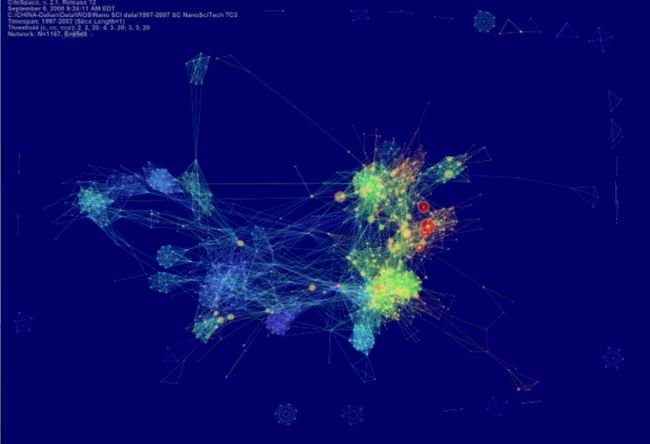
(4)高维:MATLAB
将高维数据以某种形式做转换或映射
- Box Plots 是 MATLAB 中的一个函数,把维数依次排开,每一维度用盒子来展示数据的分布,盒子的上沿为25%,中间的红线为50%(中位数),下沿为75%。盒子外的红色为Outliers。可以看出,数据在某些维度上偏大,某些维度偏小;盒子越窄,说明数据分布越紧密
Q:在 Box Plots 中,一个盒子越扁,说明在该维度上,25%-75%之间的数据分布越为集中
缺点:丧失了数据各个维度之间的关联,即看不到某个点在下一个维度上的值。即完全割裂开,一维一维单独地可视化
 展示四维数据
展示四维数据
- 平行坐标(Parallel Coordinates):相对来说最简单、但却直观有效的一种高维可视化的方法。每一个维度用一根竖线来表示(即一个个轴),每一个高维样本点用一个红色的折线来表示,它和每一个数轴的交点代表了该数据点在这个特定维度的取值
有些属性是离散的,明显地聚集在若干个点位
缺点:数据太多,图被线覆盖,看不清
4、两个可视化软件
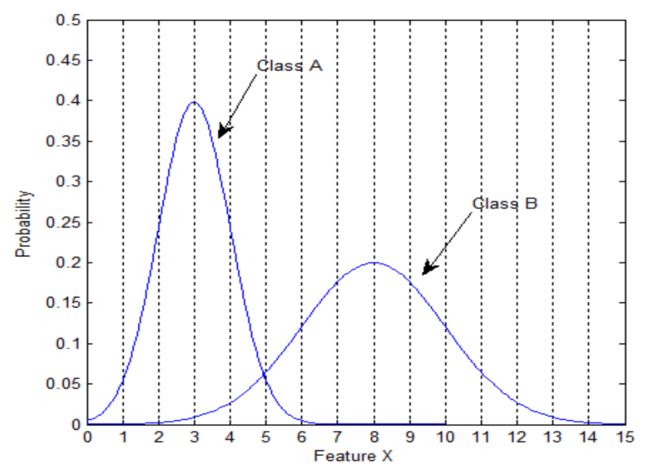
(1)Citespace:可视化的是文本(文献可视化),研究一个领域研究热点的变化、最近都在研究什么问题、过去十年中哪些文章经常被人引用等等
 引用图
引用图
(2)Gephi:把各个元素之间的相互关系用网络图展示,例如社交网络
5 特征选择
现实生活中可能有很多的属性,但一些属性可能是不相关的,或重复的(如 Address 和 Location),而且属性太多会造成空间维度太大、问题难度太大,因此需要特征选择(Feature Selection)挑出最相关的属性,降低问题难度
Q:进行属性选择的原因是:属性可能存在冗余、属性可能存在噪声、降低问题复杂度
1、如何评价属性好与不好?
(1)属性的区分度:理论上,一个属性最好能够100%区分两类目标,但实际上很难做到,都会存在 overlapping 的区域
 横坐标为身高,Class A为女人,B为男人
横坐标为身高,Class A为女人,B为男人
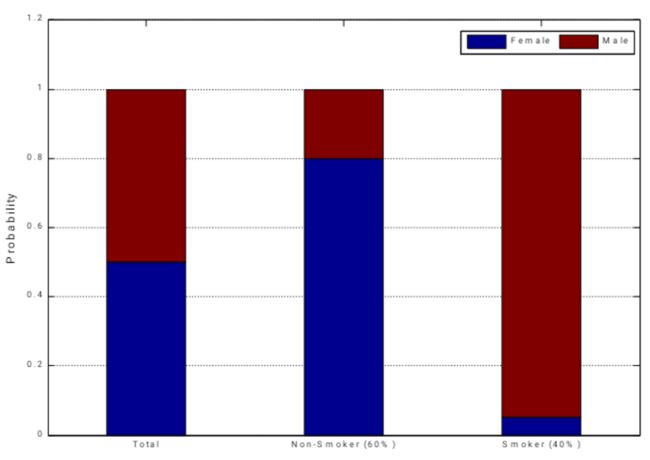
(2)离散型:
- 所有人(Total):50%男人,50%女人
知道一个属性:这个人抽烟还是不抽烟
- 不抽烟(Non-Smoker 60%):80%女人,20%男人
- 抽烟(Smoker 40%):95%男人,5%女人
知道属性之后,对于这个人是男人还是女人的判断,会更加有自信
如何量化属性的区分度? ——熵
 2、熵(Entropy)
2、熵(Entropy)
衡量系统的不确定性,即:关于一个变量的值取多少,有多大的 confidence
- 熵的最大值为1,即最不确定的情况,发生在概率为0.5时(50%可能性男人,50%可能性女人)
- 概率为0或1的时候,熵是最小的(不确定性最低)
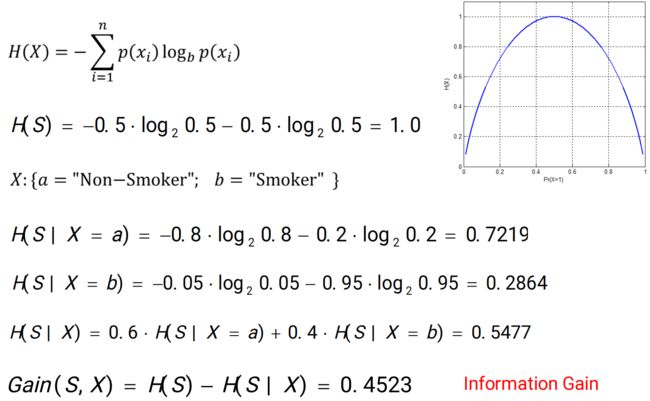
0.2864 < 0.7219 说明:在烟民中,性别的分布更加不平衡,即如果知道一个人抽烟,对这个人是男还是女的判断会更加准确
原来的不确定性与现在的不确定性的差值:信息增益(Information Gain)
- 含义:当你知道一个额外属性时,你对这个系统的不确定性能降低多少(简单可以理解为属性的价值)
- 信息增益越大,说明属性的效能越高(信息增益越大越好)
- 决策树中会用到
Q:假设某数据集的原始熵值为0.7,已知某属性的信息增益为0.2,那么利用该属性进行划分后数据集的熵值为0.5
3、Feature Subset Search
有100个属性,只想用5个,如何找到最优的5个属性的属性组?
(1)排列组合(Exhaustive Search):组合爆炸

(2)分支定界(Branch and Bound)
- 树状搜索算法
- 依赖属性的单调性假设
例:有5个属性12345,想找到最优的两元组
- 做一个单调性的假设,J 代表属性的某一种效能(评估这组属性好不好)
 随着属性越来越少,属性组的效能越来越低
随着属性越来越少,属性组的效能越来越低
- 有了这个假设之后,不需要再遍历整棵树
剪枝,简化搜索空间,可以找到最优解(不是近似解或启发式的解)
 由于0.75<0.8,(1,3,4,5)后面的子树都不需要再检测,因为后面子树的节点的值一定会<(1,3,4,5)的值,那必然会<(2,3)
由于0.75<0.8,(1,3,4,5)后面的子树都不需要再检测,因为后面子树的节点的值一定会<(1,3,4,5)的值,那必然会<(2,3)
(3)近似解
以下方法都不能保证全局最优,都是一种简单的贪婪算法
- Top K Individual Features:一个一个找,最好的K个组成一个K元组(但最优秀的属性组在一起,不一定是最优秀的 subset,因为属性可能是重复的或有相关性的)
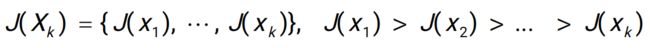
- Sequential Forward Selection:已知2个最好的,剩下的一个个找出3个最好的,逐渐扩张
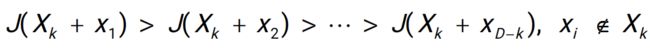
- Sequential Backward Selection:10个每次删1个,9个里查出最好的,作为新的出发点,再找8个最好的,以此类推
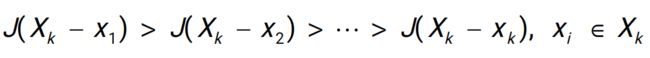
- 优化算法(Optimization Algorithms):
模拟退火(Simulated Annealing)
禁忌搜索(Tabu Search)
遗传算法(Genetic Algorithm)
Q:以下方法中可以确保获得最优属性子集的是
- Top K Individual Features
- Sequential Forward Selection
- Sequential Backward Selection
- Simulated Annealing
- Exhaustive Search
6 主成分分析(PCA)
1、Feature Extraction(特征提取)
与 Feature Selection(特征选择)的不同之处:
- 特征选择:n个属性中选出m个
- 特征提取:对原始属性作变换,不同属性间作线性组合(包含特征选择)
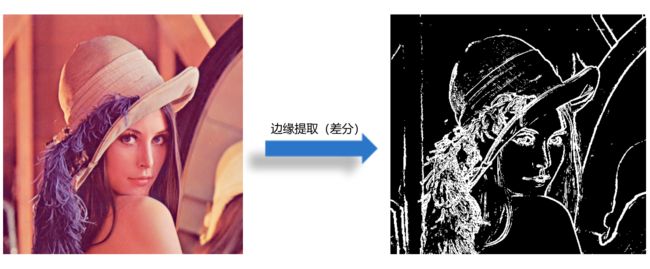
2、Principal Component Analysis(PCA,主成分分析)
平面图中的老鹰能够被人们识别的原因是:观察角度合适
3维映射到2维,丢失了很多信息,但是关键的属性都被保留下来了
不同映射方法信息损失不同,有效信息的保留也不同
 同样的物体,从不同角度看,差别非常大
同样的物体,从不同角度看,差别非常大
(1)2维例子:
假设数据是高斯分布的
情况1:长短轴与坐标轴平行
沿着某一属性分布地比较开,其 Variance 比较大,就说明这个属性所体现的信息量比较大,即这个属性越重要(Variance=Information)
在PCA变换中,应尽量把数据向数据散布大的方向投影
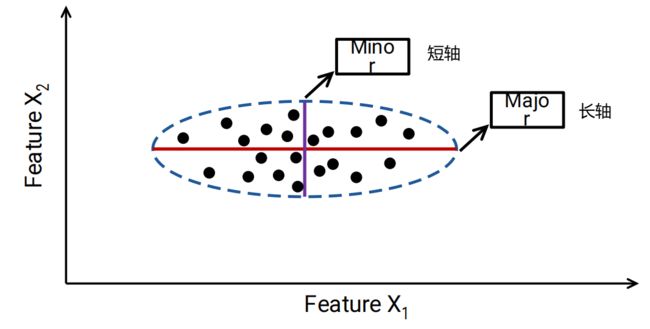 沿着长轴散布地更开,所以X1属性更好
沿着长轴散布地更开,所以X1属性更好
所以把数据沿着长轴去投影,变成一维的
情况2:X1与X2有协方差存在
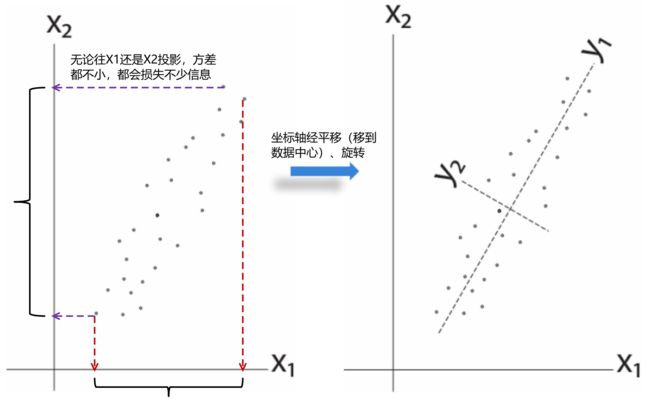
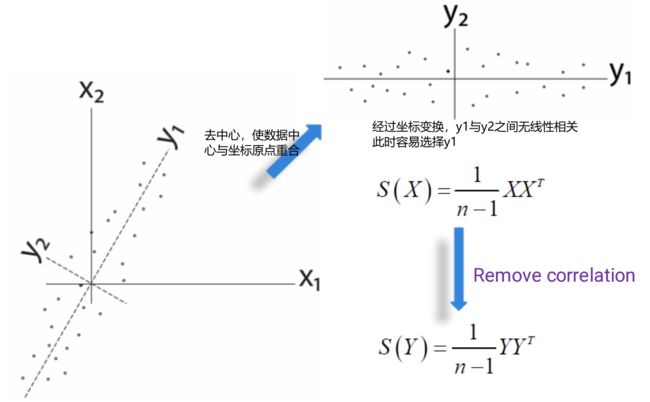
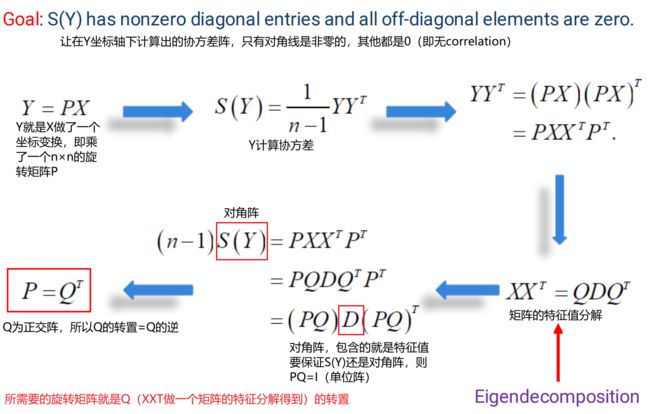 总结:PCA就是在做一个坐标的旋转,使得旋转以后,在新的坐标轴下,去掉数据之间的correlation,需要的旋转矩阵P就是Q的一个转置
总结:PCA就是在做一个坐标的旋转,使得旋转以后,在新的坐标轴下,去掉数据之间的correlation,需要的旋转矩阵P就是Q的一个转置
另一个角度推导PCA:
基本思想:想把高维空间中的点投影到线上,若所有的点都能排到一根线上,相当于降维
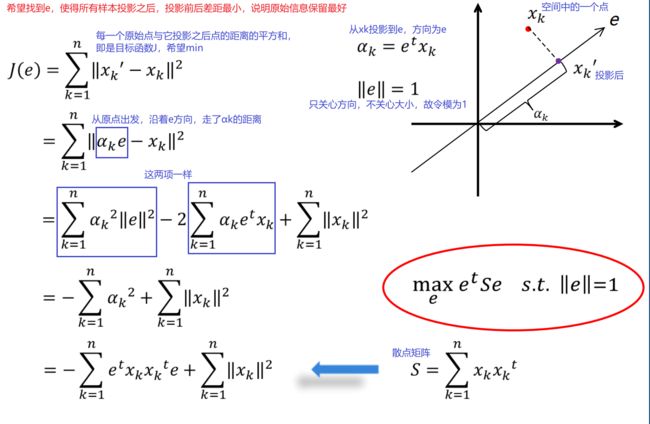
如何计算? —— 拉格朗日乘数法(适用于带条件的约束问题)
例:

用拉格朗日乘数法求解上述问题:
 PCA做的就是把原始数据投影到特征向量(对应特征值最大的那些特征向量)上
PCA做的就是把原始数据投影到特征向量(对应特征值最大的那些特征向量)上
例1:
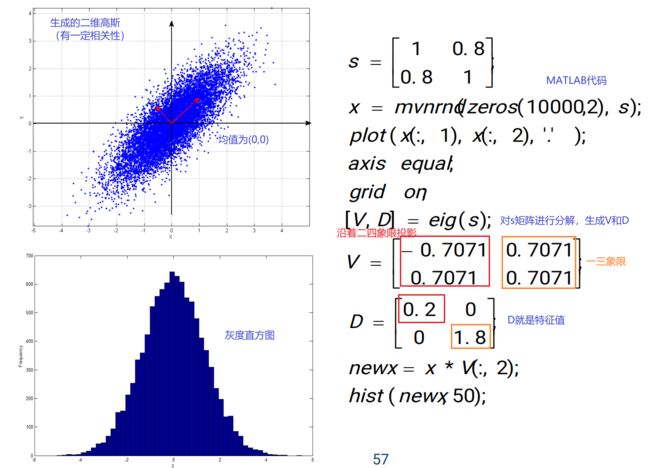
例2:
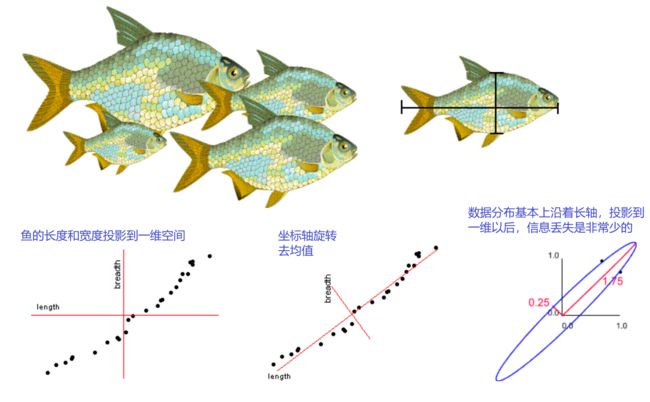 同一种类的鱼(一般:越长越宽)
同一种类的鱼(一般:越长越宽)  不同种类的鱼
不同种类的鱼
Q:PCA变换中不包含以下哪一种操作?
- 去均值
- 矩阵特征值分解
- 属性值标准化
- 坐标变换
Q:假设样本数大于维数,利用PCA技术,可以把N维数据降为1~N-1维
7 线性判别分析(LDA)
1、LDA 和 PCA
例:分类问题,两种颜色代表不同的类,每一类都是高斯分布
若做PCA,投影方向很可能是一三方向(长轴),但这样投影,两种颜色的数据会全部融合在一起,完全分不开。而沿二四方向(短轴)投影是可以分开的,这是为什么?
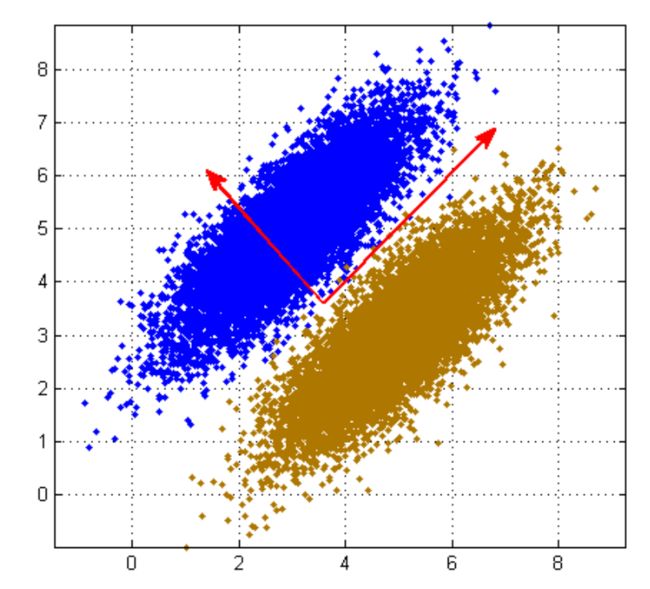
原因:做PCA时是不考虑 label 的(即 class information:样本是属于A类还是B类),它是 Unsupervised Learning。因此,如果是有标签的数据,要用线性判别分析(Linear Discriminant Analysis,LDA)
Q:如果将PCA应用于带标签的分类数据,效果视情况而定
Q:LDA与PCA最本质的区别是( )
能够降到的维数不同 计算效率不同 降维的目标不同
Q:关于 LDA 和 PCA 投影方向描述正确的是( )
必然相同 必然不同 LDA总是优于PCA 世事难料
2、LDA(Linear Discriminant Analysis,线性判别分析)
基本思路:降维,且要保留类的区分信息
![]() ,其中 x 为高维空间中分布的点,w 为投影方向(向量),y 为一维空间中的点,且尽可能分开
,其中 x 为高维空间中分布的点,w 为投影方向(向量),y 为一维空间中的点,且尽可能分开
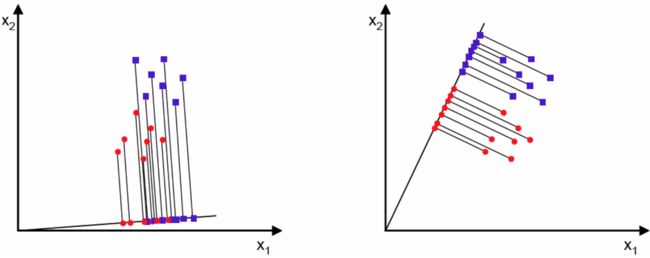 数据完全一样,两种不同的投影方式
数据完全一样,两种不同的投影方式
3、 可分性的度量
(1)不同 class 之间(between)距离尽可能远,同一 class 里(within)的数据尽可能紧凑
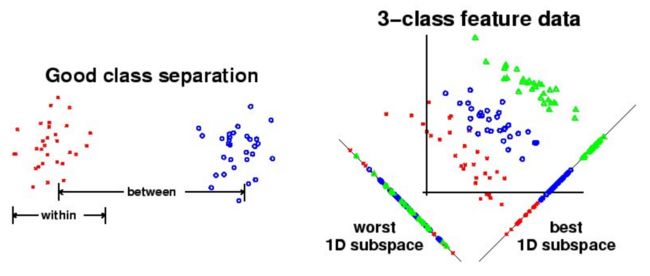
(2)Fisher准则
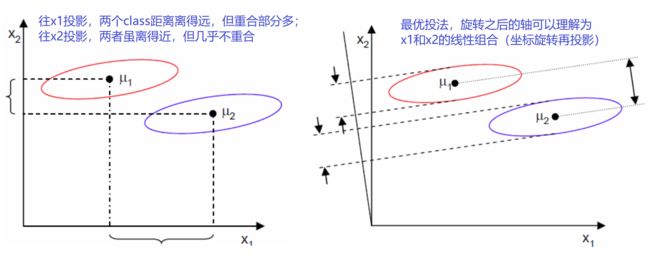

LDA目标:找投影方向使 J 最大化
4、数学推导
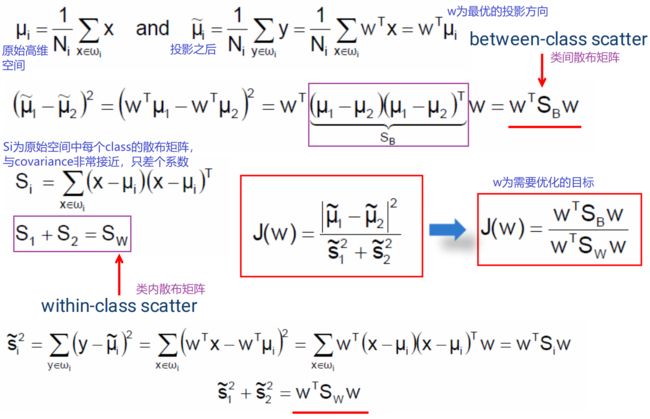 SB 矩阵的 rank=1
SB 矩阵的 rank=1


以上推导都是基于两分类问题
5、LDA的例子
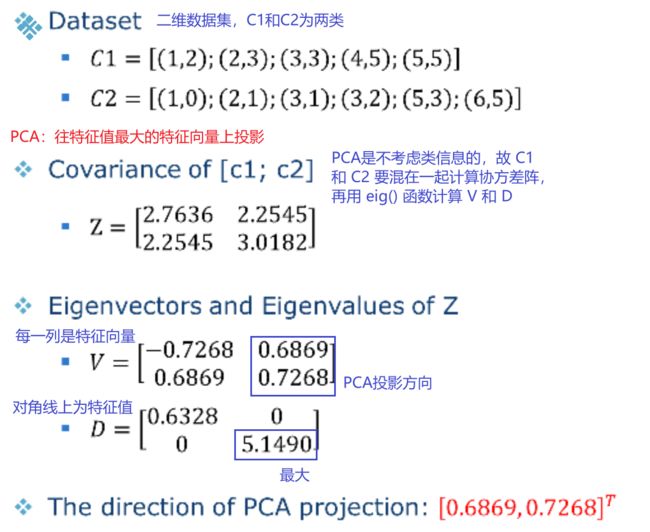


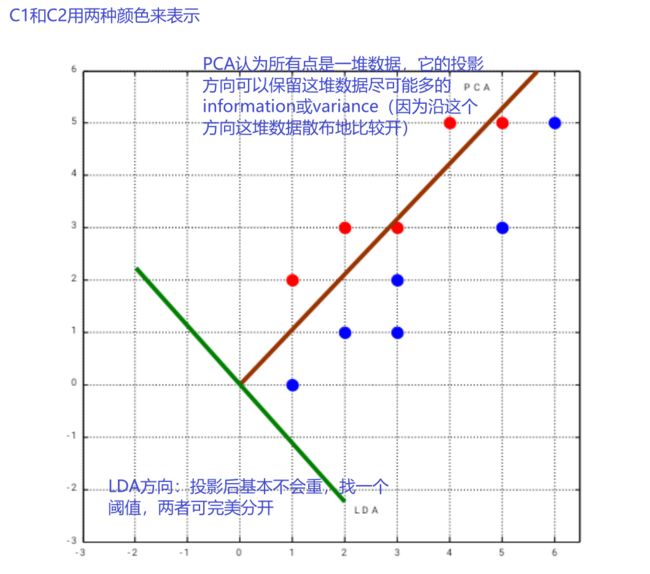
6、多分类问题的LDA
LDA 容易被拓展到更多类的问题
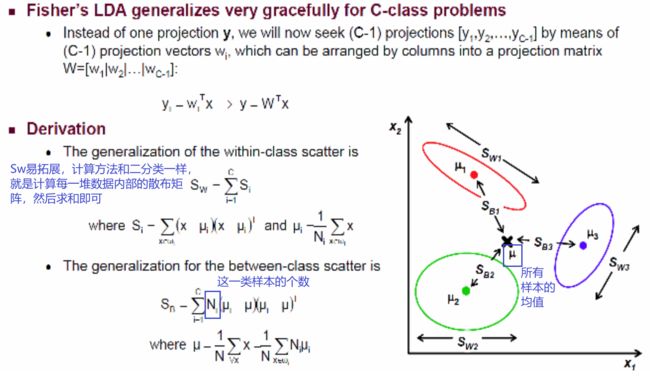
假设 C 分类问题:

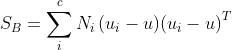
其中: 为所有样本的均值,
为所有样本的均值,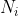 为第
为第  类中样本的个数
类中样本的个数

LDA 可投影到 C-1 维,即 C-1 个特征向量的特征值不为0
PCA 算出的每个投影方向都是正交的,而 LDA 不一定
 7、LDA的限制
7、LDA的限制
(1)类间散布矩阵 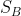 矩阵的 rank 最大就是 C-1,只有 C-1 个特征值不为 0 的特征向量,所以它不能像 PCA 一样随意降到几维
矩阵的 rank 最大就是 C-1,只有 C-1 个特征值不为 0 的特征向量,所以它不能像 PCA 一样随意降到几维
(2)类内散布矩阵  可能是奇异的,即它的逆是不存在的。当样本个数低于维度时,它的逆不存在(此时可能需要先用 PCA 降维,然后再用 LDA)
可能是奇异的,即它的逆是不存在的。当样本个数低于维度时,它的逆不存在(此时可能需要先用 PCA 降维,然后再用 LDA)
(3)LDA在类的均值(中心点)重合的情况下效果不佳


Q:当样本个数小于数据维数时,LDA 不能正常工作的原因是( )
类间散布矩阵 不满秩
类内散布矩阵 不满秩
计算量过高
Fisher准则无意义
Q:当类中心重合的时候,LDA 不能正常工作的原因是( )
Fisher准则函数分母为0
类内散布矩阵 奇异
Fisher准则函数恒等于0
类间散布矩阵 不满秩
Q:对于二分类问题,LDA只能将原始数据降到一维的原因是( )
类间散布矩阵 秩为1
类内散布矩阵 秩为1
原始数据维度过高
原始数据维度过低
8 阅读材料
