转转用户画像平台实践
文章目录
-
- 1. 背景
- 2. 什么是用户画像
- 3. 标签画像的应用场景
- 4. 转转用户画像平台的实践
-
- 4.1 系统结构图
- 4.2 标签画像的构建原则
- 4.3 标签类型和规则
- 4.4 标签的生产加工
- 4.5 标签的存储设计
- 4.6 用户洞察
- 4.7 用户分群计算
- 4.8 ID-MAPPING
- 5 未来规划
- 6 总结
1. 背景
转转作为二手电商交易领域的领军者,随着这几年的高速发展,用户数和业务量都急剧增长,为了更好的服务用户,并持续增长,产品运营的战略战术也会随之发生变化。在创业早期产品一般以粗放式运营为主,力求快速获取用户、推广产品,领跑赛道。业界也曾流传着这样的段子,产品有三宝:弹窗、浮层、加引导;运营有三宝:短信、push、加红包。然而到了中后期公司都会面临的三大问题是降本提效、持续增长、用户体验,所以基于数据的精细化运营成了大家的必然选择,而用户画像平台是帮助业务进行精细化运营的辅助工具,这其中,建设灵活、全面、高效的标签体系是工作的重中之重。本文就从标签画像体系建设的需求出发,阐述转转在建设用户画像平台过程中的思考和实践。
2. 什么是用户画像
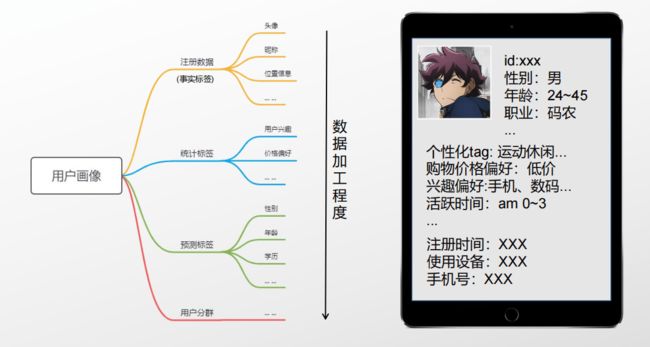
用户画像是指根据用户的属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。通俗说就是给用户打标签,而标签是通过对用户信息分析而来的高度精炼的特征标识。通过打标签可以利用一些高度概括、容易理解的特征来描述用户,可以让人更容易理解用户,并且可以方便计算处理。简单说,就是对用户的某个维度特征的描述。对一群用户而言,我们为了能让业务做的更好,就想知道他们的很多特征。比如说,我现在有个10万块钱的活动预算,那这个钱应该集中花在哪里呢?针对这个问题,我们希望对给定的用户群体,能知道他们的商业价值,对他们的商业价值有一个很好的描述。知道里面哪些人才是我们重点要服务的对象, 如下图是对一个用户的洞察,我们通过标签的加工可以观察到一个用户的一些特征属性。
3. 标签画像的应用场景
用户特征洞察:
辅助用户分析和用户洞察,用户标签可以帮助业务人员快速的对用户有一个认知,然后发现里面显著的特征,获得一些商业灵感。
增强数据分析:
标签还可以丰富数据的维度。对我们的业务数据,有更深层次的对比分析,而分析洞察得到的灵感以后,可以辅助业务落地。
精细化运营:
一方面,可以将用户群体,切割成更细粒度的群组,使得运营从粗放化到精细化,用多种不同的手段,不同的渠道去触达,比如说短信、推送、邮件等等,对于用户进行驱动或召回,从而达到事半功倍的效果。
4. 转转用户画像平台的实践
4.1 系统结构图
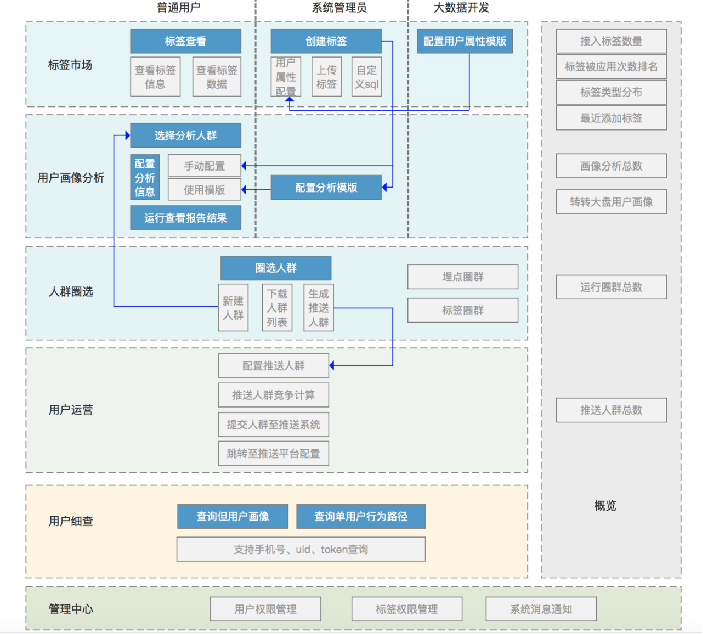
上图介绍了用户画像平台的系统结构图,按大的模块总共有6大模块,标签模块,人群计算模块,用户群画像分析模块,用户运营模块,用户洞察模块,以及权限管理模块。 下面介绍一下标签画像的构建过程。
4.2 标签画像的构建原则
我们建设用户画像平台的目的有2个:
- 必须从业务场景出发,解决实际的业务问题,之所以进行用户画像要么是获取新用户,或者是提升用户体验,或者是挽回流失用户等有明确的业务目标。
- 根据用户画像的信息做产品设计,必须要清楚知道用户长什么样子,有什么行为特征和属性,这样才能为用户设计产品或开展营销活动。一般常见的错误想法是画像维度的数据越多越好,画像数据越丰富越好,费了很大的力气进行画像后,却发现只剩下了用户画像,和业务相差甚远,没有办法直接支持业务运营,投入精力巨大但是回报微小,可以说得不偿失。鉴于此,我们的画像的维度和设计原则都是紧紧跟着业务需求去推动。
4.3 标签类型和规则
我们认为首先作为一个标签平台,它需要具有非常灵活的标签创建的能力,从而才能适应不断变化的业务需求。具体来说,我们根据标签的场景和特征把标签分成了两个大类。
-
通用标签 通用标签是一些用户的基本属性。比如年龄,性别,城市,出生年代等。
-
业务标签 而业务标签是主要是按照转转几大业务线来分类,包含了与业务行为有关的标签,比如累计下单订单数,历史下单一级品类,B2C用户业务环节等。
为了更好的描述和定义标签, 我们将标签分为四个层级,从上到下粒度逐渐变小,而标签的定义和命名也是按照四个层级来进行,规则为一级标签名称_二级标签名称_三级标签名称_标签值(四级标签)。
比如近30天活跃时间段这个标签,最终的定义形式是 业务标签_B2C_近30天活跃时间段_12点-20点, 其中12点-20点为我们标签的一个值,也是四级标签。
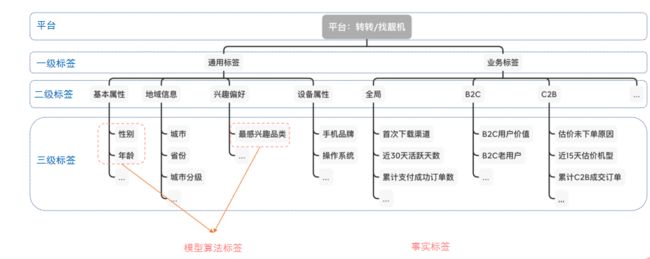
按照标签的计算方式我们把标签分为事实标签、统计标签和预测标签。
事实标签:是通过对于原始业务数据、埋点数据进行统计分析而来的,比如用户累计下单数,是基于用户一段时间内累计下单的数据量做的统计。
模型标签:模型标签是以事实标签为基础,通过构建事实标签与业务问题之间的模型,进行模型分析得到。比如兴趣类标签,最感兴趣的品类。
预测标签:通过算法建模预测该用户的一些特征,比如年龄、性别、学历、婚姻等。
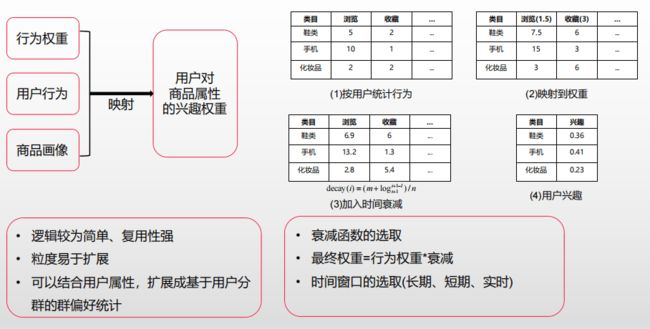
兴趣类标签的计算过程:
预测类标签的一般流程:
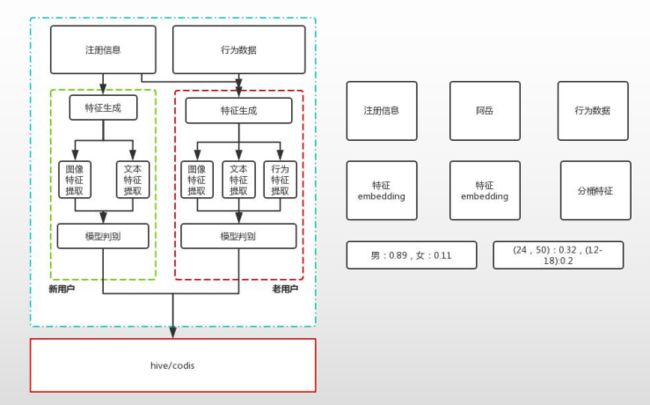
4.4 标签的生产加工
标签生产原则
标签的生产和加工要满足一下几个原则:
-
可扩展的标签创建规则 我们需要有非常灵活可扩展的标签的规则的定义,以满足用户业务场景变化导致的标签规则变化。所以我们开发了一套标签模板,每个标签的规则可以通过配置模板来实现,模板支持可视化配置相关的参数,支持随时变更模板规则,如果需要更改标签计算规则和参数 ,只需要更改模板SQL即可。并且一个模板既可以被用来一个标签上,也可以复用到多个标签了 ,大大降低了用户创建标签的门槛,同时有利于我们管理标签规则。
-
支持亿级用户的标签生产 在相对比较有限资源条件下,能够支持相对比较大的用户基数的标签生产,需要对计算或者存储方面有比较高的优化,对于系统架构来说,平台的伸缩性和这种适应性都会要求相对高一些。
-
标签数据按天更新 对于业务,我们一般的标签是按天更新的,每天凌晨会通过调度平台进行标签的计算,由于标签所依赖的上游表的产出的时间不定,标签计算会根据上游业务表的产出情况来计算,标签计算模块会检测相关依赖的表。如果监控到依赖表已经计算完成, 则开始计算这个标签。最后更新计算结果。
标签数据来源
转转标签计算所使用的数据主要分为2部分,一部分是业务数据,比如订单;一部分是用户行为数据,商品曝光事件。标签在创建前需要提前把相关业务数据或者埋点数据清洗好。
标签的模板的开发
我们设计了一套标签计算SQL模板,并支持可视化创建配置模板。创建好模板后用户不用关心标签的底层计算规则,只需要通过页面将相关的业务属性条件配置好就可以了。
模板类型有属性筛选模板和上传文件模板。属性筛选模板用于筛选特定属性的用户集,比如筛选男性,浏览商品次数为5次的用户。 上传文件是直接将特性属性的用户集上传,用户集上传之后会放到某个hive表的一个分区下,我们计算时用SQL取出这些用户即可。
用户属性集合运算
标签计算时会涉及到多种属性计算, 比如要计算浏览商品10次且下单未支付的用户。那就需要集合运算浏览商品10次的用户集和下单未支付的用户集。每个属性模板代表的都是一个用户集,这些用户集之间的运算就是集合运算。我们这里支持完整的集合运算:交、并、非,同时支持多级嵌套。为此,我们设计了一个简单的逻辑表达式,用来表示用户设置的逻辑。比如,我们想要的用户集(下图蓝色部分)是买过手机或看过手机的男性,并排除掉卖家。
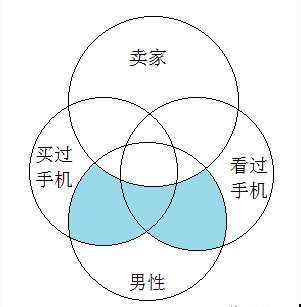
那这个的逻辑表达式就是:

实际使用的时候表达式中不会有中文,会用集合ID来代替(就是前面说的tag字段)。为了方便解析,每个集合都用括号包裹了起来,逻辑表达式中每个节点只能有两个子节点,或者没有子节点。
我们需要收集到每个用户的所有tag,这里我们把这个标签用到的所有模板union all 到一起,然后group by xxid,收集到每个用户的所有tag。
我们用UDF实现了这个逻辑表达式的执行引擎。将用户的tag列表和逻辑表达式传入UDF,就可以判断用户是不是我们想要的用户了。执行引擎会先将逻辑表达式解析为一棵树(会缓存,避免重复解析),类似于抽象语法树,然后遍历这颗树,做解释执行。逻辑运算中有个优化就是短路运算,即做一部分运算之后就可以得到整个表达式的值,剩下部分不需要再计算。比如,“与运算”中有一个false,结果就是false,“或运算”中有一个true,结果就是true。解析得到的树如下:
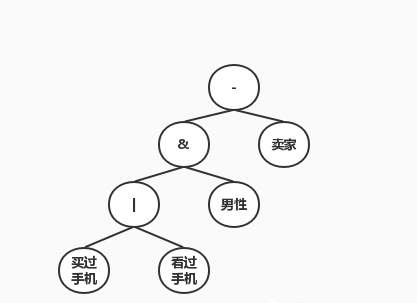
通过自定义UDF函数,我们解决了多种用户集和运算的问题,满足了用户不同业务场景不同用户属性的标签计算。
标签的创建方式
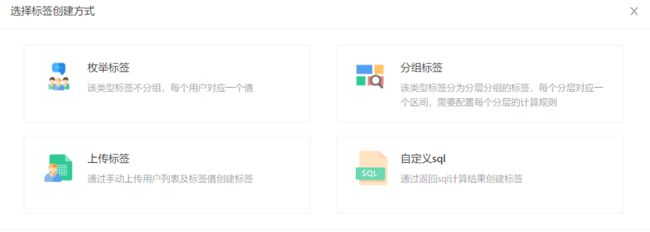
我们使用标签SQL模板作为标签计算的基石,在创建标签时支持4中标签类型,其中枚举标签和分组标签都使用SQL模板来实现,用户不需要了解SQL。
上传标签是可以直接上传用户的ID数据。自定义SQL满足在一些情况下用户自己写SQL来定义标签。
4.5 标签的存储设计
由于我们的标签是基于离线数据计算的,所有标签数据集都存放在Hive中,因为离线计算一般是按天调度,所以底层表按照天作为分区来存储,每日的标签存一个分区。然后这个partition下面的数据文件为ORC文件,采用ORC文件是为了利用ORC的列式存储,节省存储空间。如下图所示:
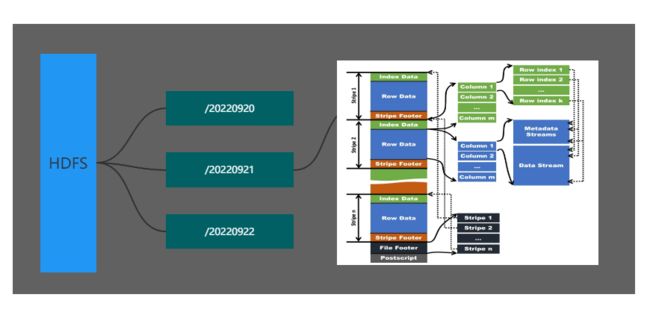
数据模型表
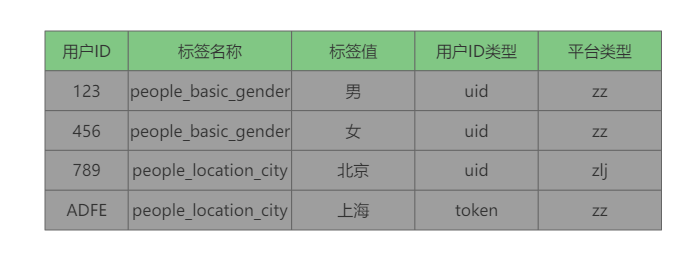
标签模型表将所有的用户token/uid和用户的标签名和值关联起来,形成明细数据集,并增加平台和用户ID字段,用来区分转转和找靓机平台侧的用户。
用户ID类型用来标识用户身份标识是注册后生成的uid还是设置token。同时为了快速检索单个标签的数据,我们将标签id作为分区,提高查询单个标签数据的效率。目前每日标签全量数据达300亿左右,为了减少存储以及避免特殊字符,应对标签名称变更问题,对标签数据存储表做了规范约束,标签名称存储为英文名称,多级名称之间由下划线连接,同时开发了标签中文名的维表,当用户需要查询中文名称时,关联维表进行查询。
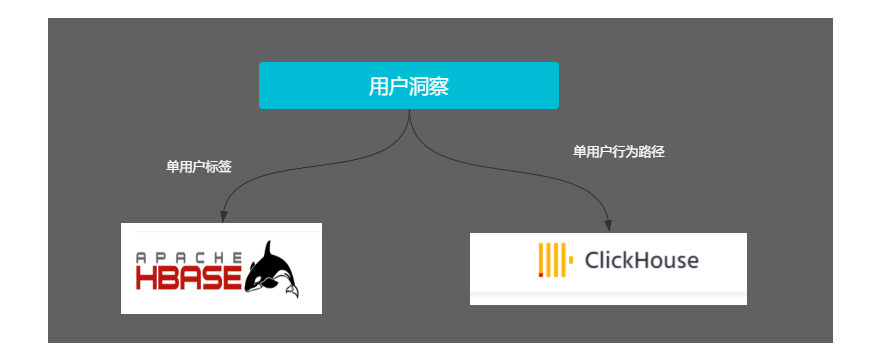
4.6 用户洞察
为了支持对单个用户的洞察分析,开发了查询单用户的标签画像和用户行为路径。单用户标签画像的思路将所有的标签明细数据根据用户ID聚合,聚合后的数据写入Hbase KV存储, 设计Rowkey时,对用户uid做字符串反转+hash(uid)运算后取6位,来解决Hbase Rowkey查询热点的问题,使用Hbase我们可以提供秒级的用户标签查询能力。
同时将用户事件行为数据从Hive同步到Clickhouse, 通过Clickhouse实现对用户行为路径的查询分析。只所以选择Clickhouse作为事件行为分析的组件,是考虑到Clickhouse的是一个比较强大的OLAP引擎,在海量数据的场景下依然可以做到秒级响应的即席查询。
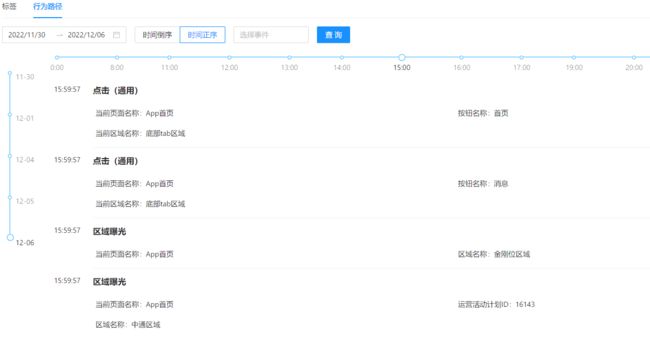
下面展示的一个用户单日按时间序列的行为路径,业务通过对路径的分析可以帮助更好的理解用户,更好的优化运营计划。
4.7 用户分群计算
用户分群是将不同类型规则的标签进行运算, 圈出符合某些特征属性的用户,可以针对这部分用户来做运营计划。我们支持多种类型圈群,可以基于标签圈人,比如年龄为20-40岁的男性用户且累计B2C支付订单为1单的用户。也可以根据用户行为事件属性来圈人,比如对进行商品比价行为事件且事件属性为品牌的用户进行分群计算。标签数据和行为数据都是Hive宽表, 结合开发的UDF函数,支持且、或、非三种运算和多层规则嵌套计算场景。下面是简单的示例代码:
select
xid
from
(
SELECT
xid,
'1670502093000' as tag_ex
from
table
where
label_name = xxx
and label_value = xxx
union
all
select
xid,
'1670502131570' as tag_ex,
from
table
where
label_name = xxx
and label_value = xxx
)
group by
xid
having
group_c (
collect_set(tag_ex),
'((1664348724964)&(1664348724974))'
)
基于Clickhouse的人群计算尝试
从上面用Hive计算的思路来看,我们是先筛选出来不同标签的用户集合, 再进行多个集合的用户id的运算。那这种运算刚好可以使用bitmap来运算。于是我们借助于Clickhouse的BitMap特性来计算,计算效率要比HiveSQL快很多。使用Clickhouse计算人群分几个步骤:
- 将用户标签hive表中的用户id都生成一个全局唯一的mappingId,这个mappingId是整数,比如用户设备id为abc, 生成一个123的mappingId。
- 将用户id->mappingId映射写入Hbase KV 存储。
- 生成一张包含mappingId,标签名称,标签值的Hive表。
- 使用Spark将mappingId标签表同步到Clickhouse的bitmap表。
- 通过Clickhouse bitMap函数来计算人群。
简化后的Clickhouse表:
CREATE TABLE user_labels
(
label_name String,
label_value String
userIds AggregateFunction(groupBitmap, UInt64)
)
ENGINE = MergeTree
PARTITION by label_name,label_value
ORDER BY label_name,label_value
Clickhouse计算人群示例SQL:
bitmapAnd (
(
select
groupBitmapMergeState(mapping_id)
from
table
where
dt = '2022-12-01'
and label_name = 'XXX'
and label_value = 'XXX'
group by
label_name,
label_value
),
(
select
groupBitmapState(abs(mapping_id))
from
table
where
dt = '2022-12-01'
and label_name = 'XXX'
and label_value = 'XXX'
)
)
使用Clickhouse计算分群的时间可以达到秒级,比HiveSQL要快很多。但由于我们的标签数据量很大,目前已达到百亿级别,当分群规则配置的特别复杂时,bitMap也会耗时较长,再加上业务需要下载人去明细数据,按照我们的方案,通过Clickhouse计算后还需要查询Hbase把mappingId关联的token查询出来,当数据量很大的时候会有一些性能或稳定性问题,所以目前针对于Clickhouse的分群计算还在探索中。
4.8 ID-MAPPING
当前转转APP、找靓机APP和小程序登录状态的uid和未登录状态的token是散乱的,无法识别同一个用户或设备,各端用户标识并没有打通。在收集和积累用户信息与行为信息之后,为了建立更完善的标签体系、更完整的用户画像、支持更多的数据应用场景,要将各端的ID 关联起来,尽可能地将用户的数据打通,从而提供更加全面准确的分析。通过ID-MAPPING我们建立全域下的统一的、标准的、高准确率、高时效性的OneID数据模型。
各端标识信息,在授权的情况下允许获取到的设备标识信息。
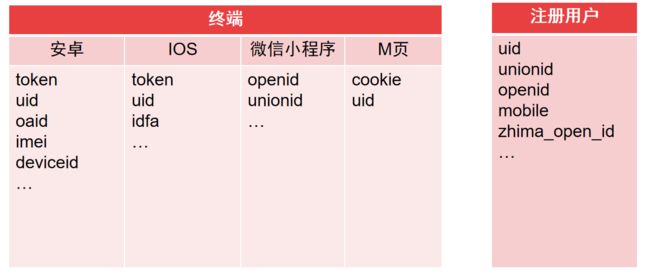
OneID用户识别规则-场景抽象
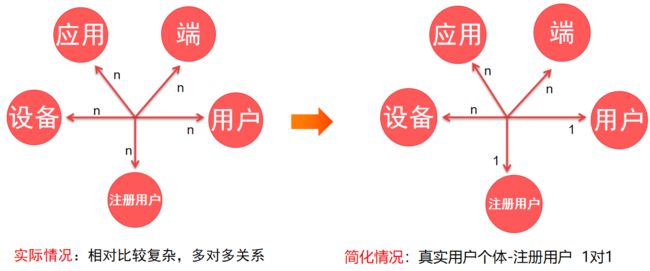
识别规则
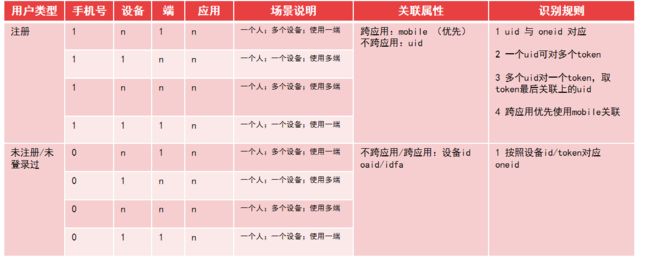
OneID模型设计
表结构示例 作用域:集团全域

5 未来规划
对标签画像未来的规划:
- 支持实时标签。随着业务运营对标签的产出失效有更高的要求,未来我们会以业务场景出发,对部分标签进行实时打标,系统架构会同时支持离线和实时标签的计算,这对我们目前的纯离线标签架构有更大的挑战。
- 和智能运营计划平台无缝打通。目前标签画像和运营计划平台是相对割裂的,在产品形态上并没有完全的融合,用户使用起来也不是很顺畅, 未来会更加紧密的跟运营计划平台打通,更好的助力业务。
6 总结
以上主要是针对转转用户标签画像的建设实践,主要从标签的构建,标签的生产加工,存储设计, 用户洞察,用户分群以及ID-MAPPING等几个方面阐述了一些经验和思考。在实践的过程中也会遇到一些问题,未来会持续优化标签画像产品和架构,为业务更好的助力。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~