Apriori算法挖掘疾病的关联规则
实验题目:
某医院为了研究几种内科疾病的关联,随机抽取了五十名病人的档案,得到的情况记录在 数据集.txt 中,其中一部分数据如下图所示:

Cardiacfailure表示心力衰竭,Myocardialinfarction表示心肌梗塞,uremia表示尿毒症,diabetes表示糖尿病,Renalfailure 表示肾衰竭,Other表示其他疾病
要求:请自行根据数据的实际情况指定最小支持度与最小置信度,并采用Apriori算法挖掘这些疾病之间的关联规则。
一、实验代码
实验环境:
使用语言:Python
开发环境:PyCharm
参数设置:
最小支持度为30%,最小置信度分别设为70%和80%。
def loadDataSet() :
"""
功能:构造原始数据。
:return: 原始数据集合
"""
f2 = open("数据集.txt", "r")
lines = f2.readlines()
retData = []
for line in lines:
items = line.strip().split(' ')
retData.append([(items[i]) for i in range(1, len(items))])
return retData
#
def createC1(dataSet) :
"""
功能:将所有元素转换为frozenset型字典,存放到列表中
:param dataSet: 原始数据集合
:return: 最初的候选频繁项
"""
C1 = []
for transaction in dataSet :
for item in transaction :
if not [item] in C1 :
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
def scanD(D, Ck, minSupport) :
"""
函数功能:过滤掉不符合支持度的集合
具体逻辑:
遍历原始数据集合候选频繁项集,统计频繁项集出现的次数,
由此计算出支持度,在比对支持度是否满足要求,
不满足则剔除,同时保留每个数据的支持度。
:param D: 原始数据转化后的字典
:param Ck: 候选频繁项集
:param minSupport: 最小支持度
:return: 频繁项集列表retList 所有元素的支持度字典
"""
ssCnt = {}
for tid in D :
for can in Ck :
if can.issubset(tid) : # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt : # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else :
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt :
support = ssCnt[key] / numItems
if support >= minSupport :
retList.insert(0, key)
supportData[key] = support
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
def aprioriGen(Lk, k) :
"""
功能: 生成所有可以组合的集合
具体逻辑:通过每次比对频繁项集相邻的k-2个元素是否相等,如果相等就构造出一个新的集合
:param Lk: 频繁项集列表Lk
:param k: 项集元素个数k,当前组成项集的个数
:return: 频繁项集列表Ck
举例:[frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
"""
retList = []
lenLk = len(Lk)
for i in range(lenLk) : # 两层循环比较Lk中的每个元素与其它元素
for j in range(i + 1, lenLk) :
L1 = list(Lk[i])[:k - 2] # 将集合转为list后取值
L2 = list(Lk[j])[:k - 2]
L1.sort();
L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1 == L2 :
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
def apriori(dataSet, minSupport=0.5) :
"""
function:apriori算法实现
:param dataSet: 原始数据集合
:param minSupport: 最小支持度
:return: 所有满足大于阈值的组合 集合支持度列表
"""
D = list(map(set, dataSet)) # 转换列表记录为字典,为了方便统计数据项出现的次数
C1 = createC1(dataSet) # 将每个元素转会为frozenset字典 [frozenset({A}), frozenset({B}), frozenset({C}), frozenset({D}), frozenset({E})]
# 初始候选频繁项集合
L1, supportData = scanD(D, C1, minSupport) # 过滤数据,去除不满足最小支持度的项
# L1 频繁项集列表 supportData 每个项集对应的支持度
L = [L1]
k = 2
while (len(L[k - 2]) > 0) : # 若仍有满足支持度的集合则继续做关联分析
Ck = aprioriGen(L[k - 2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
def calcConf(freqSet, H, supportData, brl, minConf=0.7) :
"""
对规则进行评估 获得满足最小可信度的关联规则
:param freqSet: 集合元素大于两个的频繁项集
:param H:频繁项单个元素的集合列表
:param supportData:频繁项对应的支持度
:param brl:关联规则
:param minConf:最小可信度
"""
prunedH = [] # 创建一个新的列表去返回
for conseq in H :
conf = supportData[freqSet] / supportData[freqSet - conseq] # 计算置信度
if conf >= minConf :
print(freqSet - conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7) :
"""
功能:生成候选规则集合
:param freqSet: 集合元素大于两个的频繁项集
:param H:频繁项单个元素的集合列表
:param supportData:频繁项对应的支持度
:param brl:关联规则
:param minConf:最小可信度
:return:
"""
m = len(H[0])
if (len(freqSet) > (m + 1)) : # 尝试进一步合并
Hmp1 = aprioriGen(H, m + 1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1) : # need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
def generateRules(L, supportData, minConf=0.7) : # supportData 是一个字典
"""
功能:获取关联规则的封装函数
:param L:频繁项列表
:param supportData:每个频繁项对应的支持度
:param minConf:最小置信度
:return:强关联规则
"""
bigRuleList = []
for i in range(1, len(L)) : # 从为2个元素的集合开始
for freqSet in L[i] :
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1) :
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
else :
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
if __name__ == "__main__":
# 初始化数据
dataSet = loadDataSet()
# print(dataSet)
# 计算出频繁项集合对应的支持度
L, suppData = apriori(dataSet,minSupport=0.3)
print("频繁项集:")
for i in L:
for j in i:
print(list(j))
# 得出强关联规则
print("关联规则:")
rules = generateRules(L, suppData, minConf=0.7)
二、实验结果
当最小支持度为30%,最小置信度为70%时:

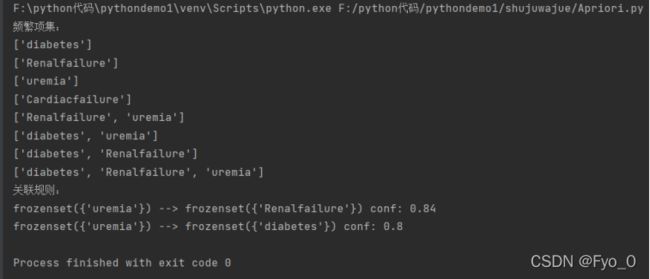
当最小支持度为30%,最小置信度为80%时:
三、结果分析
根据以上关联规则可得出以下结论:
当最小支持度为30%,最小置信度为70%时:
①糖尿病、尿毒症、肾功能衰竭三种疾病之间有一定的关联关系。
②对于尿毒症的疾病人群而言,有84%的患者会并发肾衰竭,有80%的患者会并发糖尿病,有72%的患者会并发糖尿病和肾衰竭。
③对于糖尿病的疾病人群而言,有71%的患者会并发肾衰竭,有71%的患者会并发尿毒症。
④对于肾衰竭的疾病人群而言,有71%的患者会并发尿毒症。
当最小支持度为30%,最小置信度为80%时:
①糖尿病、尿毒症、肾功能衰竭三种疾病之间有一定的关联关系。
②对于尿毒症的疾病人群而言,有84%的患者会并发肾衰竭,有80%的患者会并发糖尿病。
附 数据集.txt :
1 Cardiacfailure Myocardialinfarction Other
2 Cardiacfailure
3 Cardiacfailure uremia Myocardialinfarction
4 Renalfailure Cardiacfailure diabetes uremia
5 uremia Cardiacfailure Renalfailure diabetes
6 diabetes
7 diabetes Cardiacfailure Myocardialinfarction Other
8 diabetes uremia
9 diabetes
10 Renalfailure diabetes uremia
11 diabetes
12 Cardiacfailure diabetes uremia Renalfailure
13 uremia diabetes Renalfailure Cardiacfailure
14 Renalfailure
15 Other Renalfailure
16 Renalfailure diabetes
17 Myocardialinfarction Cardiacfailure
18 uremia Renalfailure
19 Renalfailure
20 uremia diabetes Renalfailure
21 uremia Renalfailure
22 uremia
23 Cardiacfailure uremia Renalfailure diabetes Myocardialinfarction
24 Renalfailure diabetes uremia Cardiacfailure
25 Myocardialinfarction Cardiacfailure Other
26 diabetes Renalfailure uremia Cardiacfailure
27 uremia Renalfailure diabetes Cardiacfailure Myocardialinfarction
28 uremia diabetes Renalfailure Myocardialinfarction
29 diabetes uremia
30 Myocardialinfarction
31 diabetes Renalfailure uremia Cardiacfailure
32 Cardiacfailure diabetes Other
33 Renalfailure diabetes
34 uremia diabetes Renalfailure
35 Myocardialinfarction Cardiacfailure
36 uremia Renalfailure
37 Other Renalfailure Myocardialinfarction
38 Renalfailure diabetes uremia
39 Cardiacfailure Myocardialinfarction Other
40 Myocardialinfarction Other
41 uremia Renalfailure diabetes
42 Cardiacfailure diabetes uremia Renalfailure
43 Myocardialinfarction
44 diabetes uremia Renalfailure
45 Myocardialinfarction Renalfailure
46 Cardiacfailure Myocardialinfarction
47 diabetes
48 Myocardialinfarction Cardiacfailure
49 diabetes Renalfailure uremia
50 Renalfailure